背景
スクレイピングしたデータをgspread経由で毎日スプレッドシートへ書き込みをしている。
シート名は書き込み対象データの日付(yyyy/mm/dd)
正常に動作し続ければ日付順にシートが並ぶはずだが、書き込み失敗等の影響で稀に日付がズレてしまっている事がある。
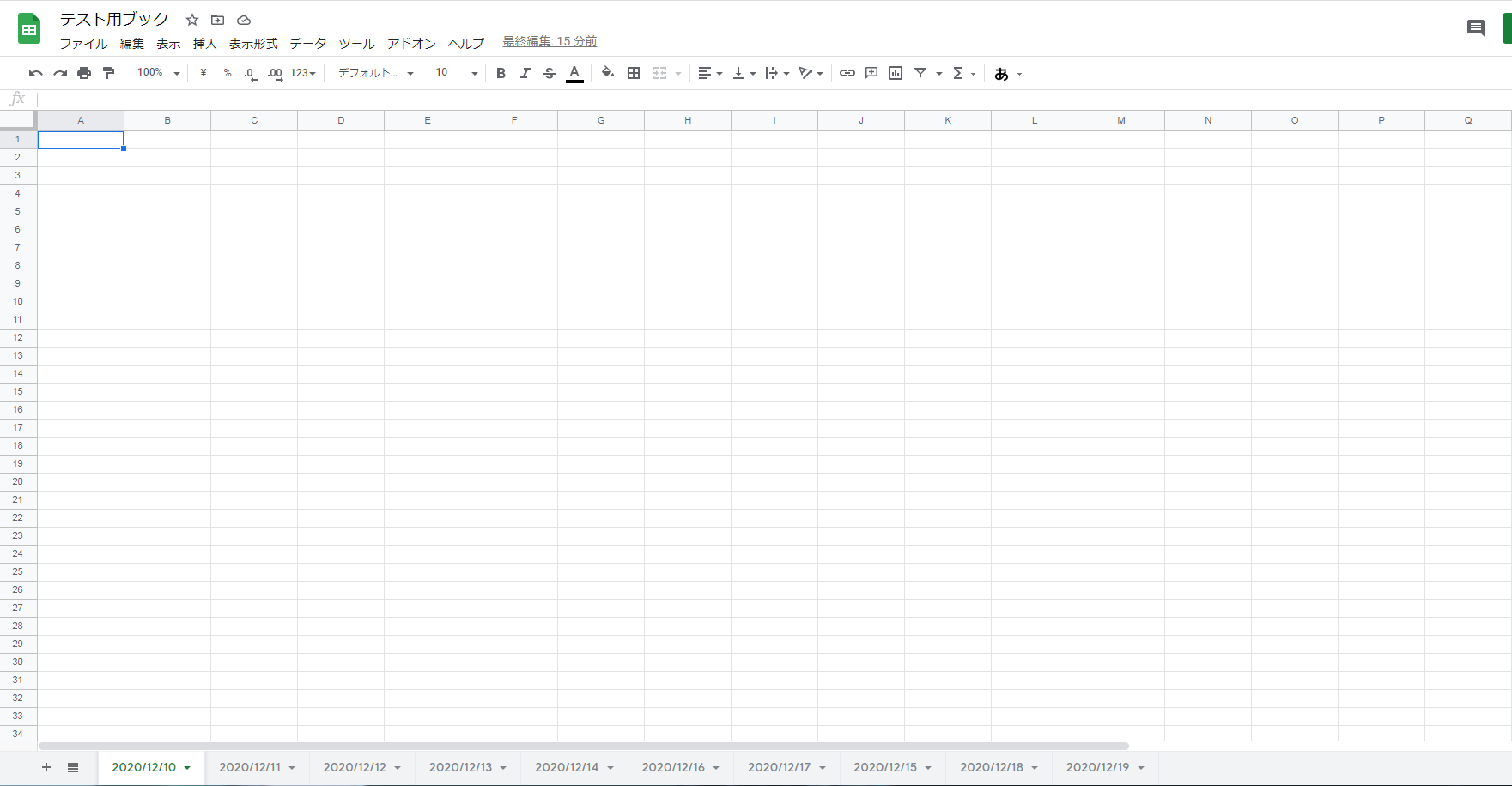
このような形。
見付ける度に手動で並び替えていたがいい加減面倒・・・
↓
そうだ、自動化しよう。
コード
import gspread
from oauth2client.service_account import ServiceAccountCredentials
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
import os
import sys
# GoogleAPI
scope = ['https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive']
# 認証用キー
json_keyfile_path = f'credentials.jsonのパス'
# サービスアカウントキーを読み込む
credentials = ServiceAccountCredentials.from_json_keyfile_name(json_keyfile_path, scope)
# pydrive用にOAuth認証を行う
gauth = GoogleAuth()
gauth.credentials = credentials
drive = GoogleDrive(gauth)
# スプレッドシート格納フォルダ
folder_id = 'ワークブックを格納しているフォルダID'
# スプレッドシート格納フォルダ内のファイル一覧取得
file_list = drive.ListFile({'q': "'%s' in parents and trashed=false" % folder_id}).GetList()
# ファイル一覧からファイル名のみを抽出
title_list = [file['title'] for file in file_list]
# gspread用に認証
gc = gspread.authorize(credentials)
# ワークブック名
book_title = 'テスト用ブック'
# 開きたいワークブックのスプレッドシートIDを取得
sheet_id = [file['id'] for file in file_list if file['title'] == book_title]
sheet_id = sheet_id[0]
# ワークブックを開く
workbook = gc.open_by_key(sheet_id)
# 存在するワークシートの情報を全て取得
worksheets = workbook.worksheets()
# 現在のワークシートのタイトルをリストへ格納
tmp_worksheets_title_list = [worksheet.title for worksheet in worksheets]
# タイトルを降順ソート
worksheets_title_list = sorted(tmp_worksheets_title_list, reverse=True)
# Worksheet型オブジェクトをソートした順序でリストへ格納
worksheets_obj_list = [worksheet for title in worksheets_title_list for worksheet in worksheets if worksheet.title == title]
# ワークシートをソート
workbook.reorder_worksheets(worksheets_obj_list)
実行結果
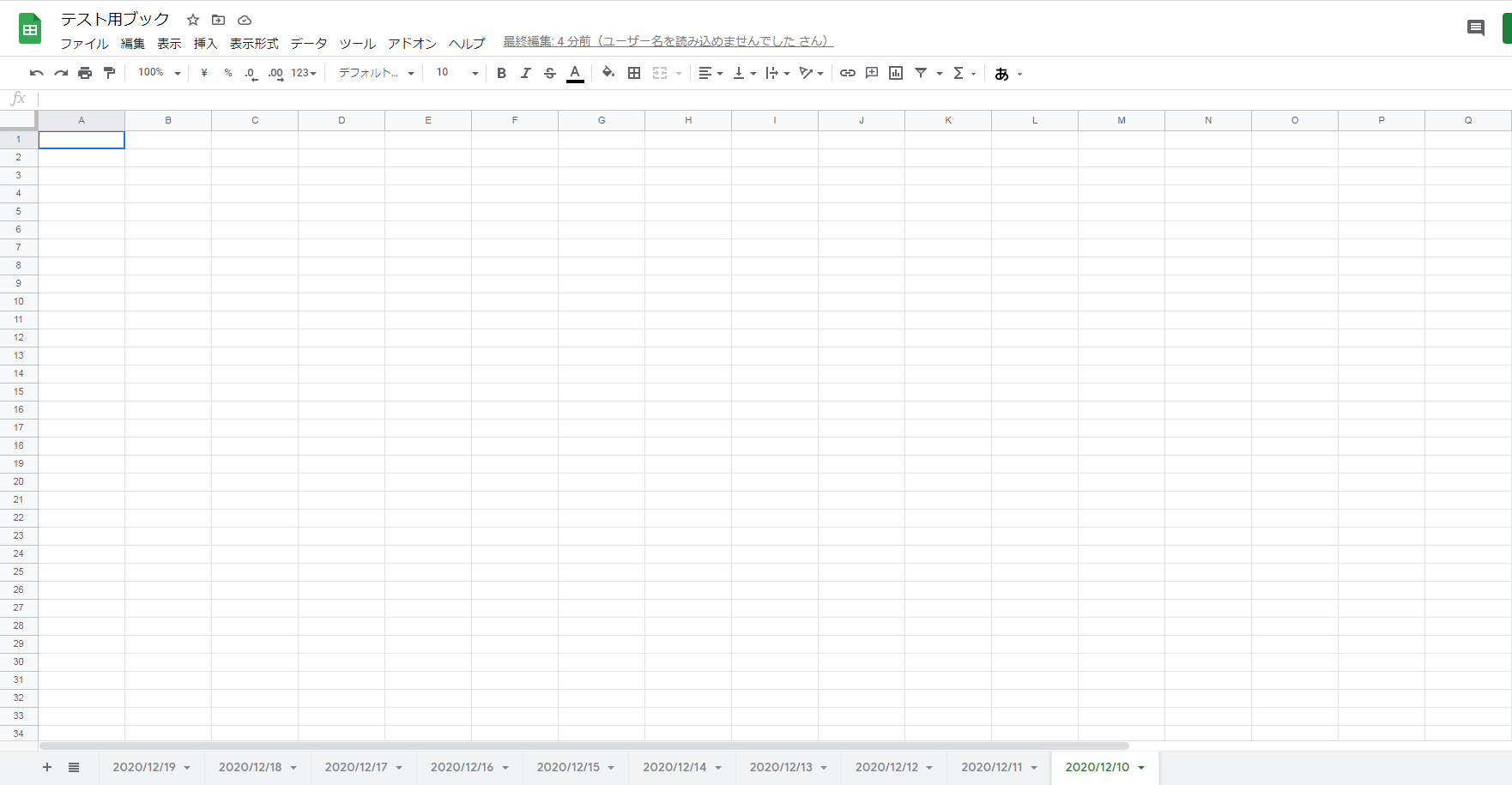
説明
まず、Google先生に色々聞いてみたが似たような作業をしている人が全く見当たらない。
どうやら自分でなんとかするしかないようだ。
次にAPIの公式リファレンスを色々探してみた。
すると、それらしき物を発見。
とりあえず読んでみる。
reorder_worksheets(worksheets_in_desired_order)
Updates the index property of each Worksheets to reflect its index in the provided sequence of Worksheets.
Parameters: worksheets_in_desired_order – Iterable of Worksheet objects in desired order.
Note: If you omit some of the Spreadsheet’s existing Worksheet objects from the provided sequence, those Worksheets will be appended to the end of the sequence in the order that they appear in the list returned by Spreadsheet.worksheets().
New in version 3.4.
日本語訳
各ワークシートのインデックスプロパティを更新して、提供された一連のワークシートにそのインデックスを反映します。
パラメータ:worksheets_in_desired_order –希望する順序でワークシートオブジェクトを反復可能。
注:提供されたシーケンスからスプレッドシートの既存のワークシートオブジェクトの一部を省略した場合、それらのワークシートは、Spreadsheet.worksheets()によって返されるリストに表示される順序でシーケンスの最後に追加されます。
バージョン3.4の新機能。
なるほど、わからん。
ソースを直接読んでみる事にした。
def reorder_worksheets(self, worksheets_in_desired_order):
"""Updates the ``index`` property of each Worksheets to reflect
its index in the provided sequence of Worksheets.
:param worksheets_in_desired_order: Iterable of Worksheet objects in desired order.
Note: If you omit some of the Spreadsheet's existing Worksheet objects from
the provided sequence, those Worksheets will be appended to the end of the sequence
in the order that they appear in the list returned by ``Spreadsheet.worksheets()``.
.. versionadded:: 3.4
"""
idx_map = {}
for idx, w in enumerate(worksheets_in_desired_order):
idx_map[w.id] = idx
for w in self.worksheets():
if w.id in idx_map:
continue
idx += 1
idx_map[w.id] = idx
body = {
'requests': [
{
'updateSheetProperties': {
'properties': {'sheetId': key, 'index': val},
'fields': 'index',
}
}
for key, val in idx_map.items()
]
}
return self.batch_update(body)
なるほど、w.idでワークシートのIDを取得してそれを元にソートしているらしい。
# ワークブックを開く
workbook = gc.open_by_key(sheet_id)
# 存在するワークシートの情報を全て取得
worksheets = workbook.worksheets()
print(worksheets)
print(type(worksheets))
print(type(worksheets[0]))
[<Worksheet '2020/12/10' id:0>, <Worksheet '2020/12/11' id:750827161>, <Worksheet '2020/12/12' id:868021966>, <Worksheet '2020/12/13' id:1358131870>, <Worksheet '2020/12/14' id:224556508>, <Worksheet '2020/12/16' id:2001082452>, <Worksheet '2020/12/17' id:207127532>, <Worksheet '2020/12/15' id:653171131>, <Worksheet '2020/12/18' id:1969672638>, <Worksheet '2020/12/19' id:428756371>]
<class 'list'>
<class 'gspread.models.Worksheet'>
このようにワークシートの情報はリストにWorksheet型として格納されている。
シート名、IDが格納されていて先程のライブラリが取得していたのがこのIDだ。
ライブラリにはこのWorksheet情報が格納されているリストを引数として渡す。
そして、このリスト内の順序を自分がソートしたい順序に変更してあげてから渡せばその順序でソートされるというわけだ。
# 現在のワークシートのタイトルをリストへ格納
tmp_worksheets_title_list = [worksheet.title for worksheet in worksheets]
print(tmp_worksheets_title_list)
# タイトルを降順ソート
worksheets_title_list = sorted(tmp_worksheets_title_list, reverse=True)
print(worksheets_title_list)
# Worksheet型オブジェクトをソートした順序でリストへ格納
worksheets_obj_list = [worksheet for title in worksheets_title_list for worksheet in worksheets if worksheet.title == title]
print(worksheets_obj_list)
['2020/12/10', '2020/12/11', '2020/12/12', '2020/12/13', '2020/12/14', '2020/12/16', '2020/12/17', '2020/12/15', '2020/12/18', '2020/12/19']
['2020/12/19', '2020/12/18', '2020/12/17', '2020/12/16', '2020/12/15', '2020/12/14', '2020/12/13', '2020/12/12', '2020/12/11', '2020/12/10']
[<Worksheet '2020/12/19' id:428756371>, <Worksheet '2020/12/18' id:1969672638>, <Worksheet '2020/12/17' id:207127532>, <Worksheet '2020/12/16' id:2001082452>, <Worksheet '2020/12/15' id:653171131>, <Worksheet '2020/12/14' id:224556508>, <Worksheet '2020/12/13' id:1358131870>, <Worksheet '2020/12/12' id:868021966>, <Worksheet '2020/12/11' id:750827161>, <Worksheet '2020/12/10' id:0>]
Worksheetを格納しているリストを直接ソートする事は出来ないのでシート名をキーにして新たにリストを作成する。
1.シート名のみをリストへ格納
↓
2.1で作成したリストを任意の順序へソート(今回は降順ソート)
↓
3.ソートしたシート名のみを格納しているリストをキーにして元のWorksheet情報格納リストからWorksheet情報を取り出し新たなリストへ格納
これで任意の順序に並び替えたWorksheet情報格納リストが出来た。
# ワークシートをソート
workbook.reorder_worksheets(worksheets_obj_list)
作成したリストをライブラリへ渡せばソート完了。
最後に
公式リファレンスわかりにくいよ・・・ぴえん。