Samaneh Azadi, Matthew Fisher, Vladimir Kim, Zhaowen Wang, Eli Shechtman, Trevor Darrell
CVPR2018
pdf, arXiv, github
著者の記事内の画像も使用.
どんなもの?
一部のフォント画像(例えばA, B, C)からその他全てのフォント画像(D ~ Z)を生成するGAN, Multi-Content GAN (MC-GAN)を提案.

先行研究との差分
- 一部の既知のアルファベット画像から,同じスタイルの未知のアルファベット画像を生成するend-to-endの学習手法を提案.
- これを実現するstacked conditional GAN構造のネットワークを提案.
技術や手法のキモ
Multi-Content GAN (MC-GAN)はフォント形状のマスクを生成するGlyphNetと,その出力に対してフォントの色や装飾を推定するOrnaNetの2つのネットワークで構成される.
GlyphNet, OrnaNet共に,フォント画像生成に適した形にConditional GANを改良した.
Glyph Network
とあるフォントの少数既知サンプルから,残りの未知文字の特徴を捉える(generalizing all 26 capital letters of a font from a few example glyphs)ためには,既知文字と未知文字の間の相関や類似性を捉える必要がある.
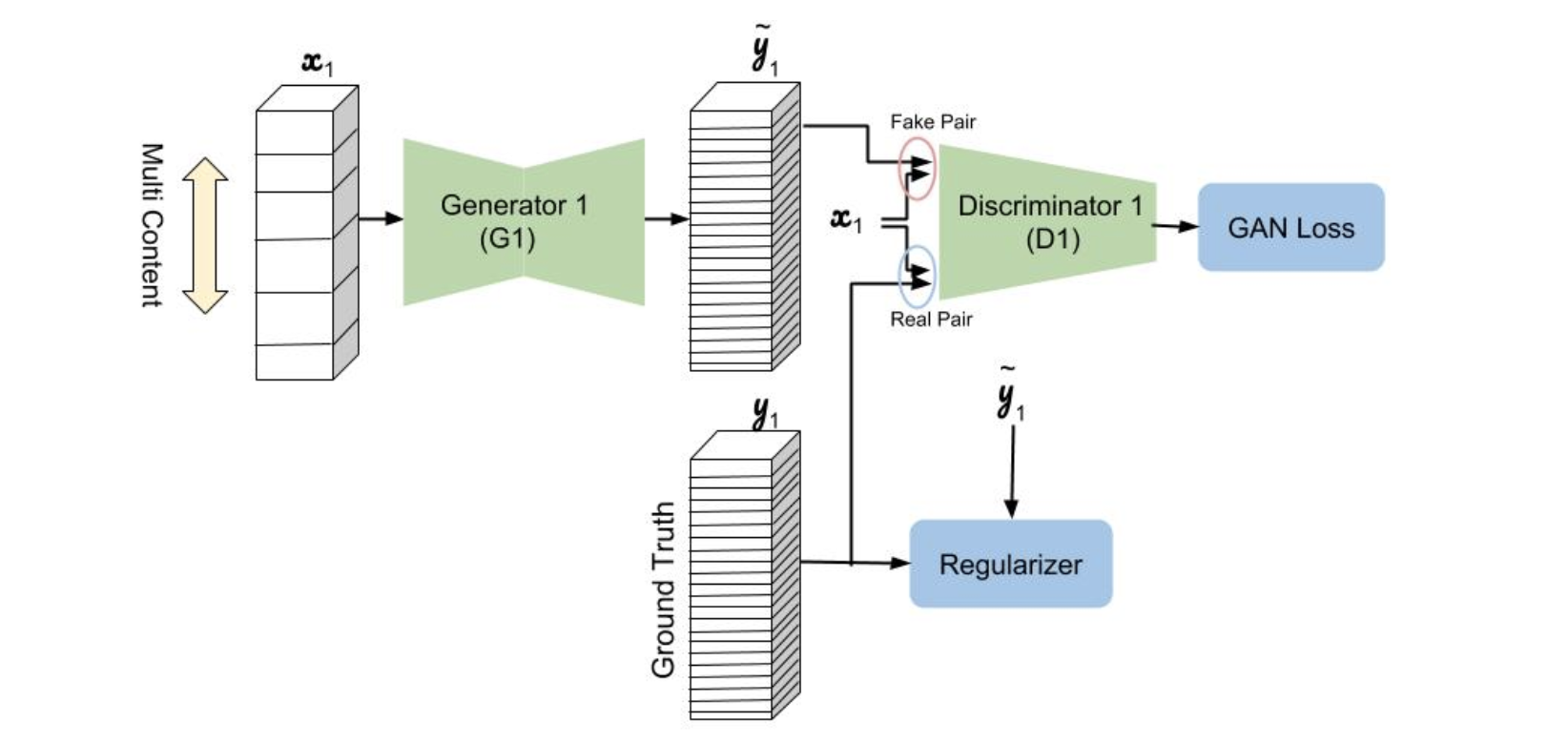
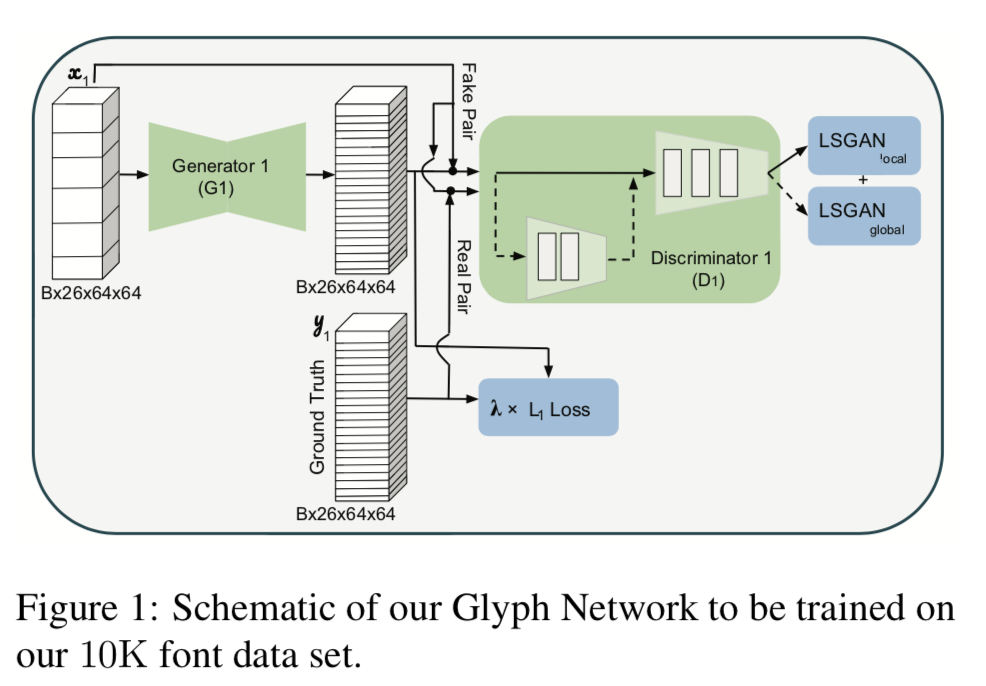
2つの図はどちらともGlyph Networkの概要図.上が記事内のもの,下が論文内のもの($D_1$の入力が分かりにくい).
- 26文字のアルファベットが26チャネルの入出力に対応している(入力$x_1$の未知文字部分は空なのでは).
- $G_1$の出力$\tilde{y_1}$は26文字のマスク(gray-scale?).
- $G_1$は[12]のもので6つのResNet blockを持つ.
- $D_1$は[11]のように3つの畳み込み層を持つlocal discriminatorと2つの畳み込み層を持つglobal discriminatorで構成される.
- $y_1$は$\tilde{y_1}$と同じ種類のフォントの真値
- ロス関数は$L_1$ロスとlocal, globalのleast squares GAN (LSGAN) lossで構成される.
L(G_1) = \lambda L_{L_1}(G_1) + L_{LSGAN}(G_1, D_1) \\
L_{LSGAN} = L_{LSGAN}^{local}(G_1, D_1) + L_{LSGAN}^{global}(G_1, D_1)
これを10K font datasetで学習し,各アルファベット間の相関を学習する.
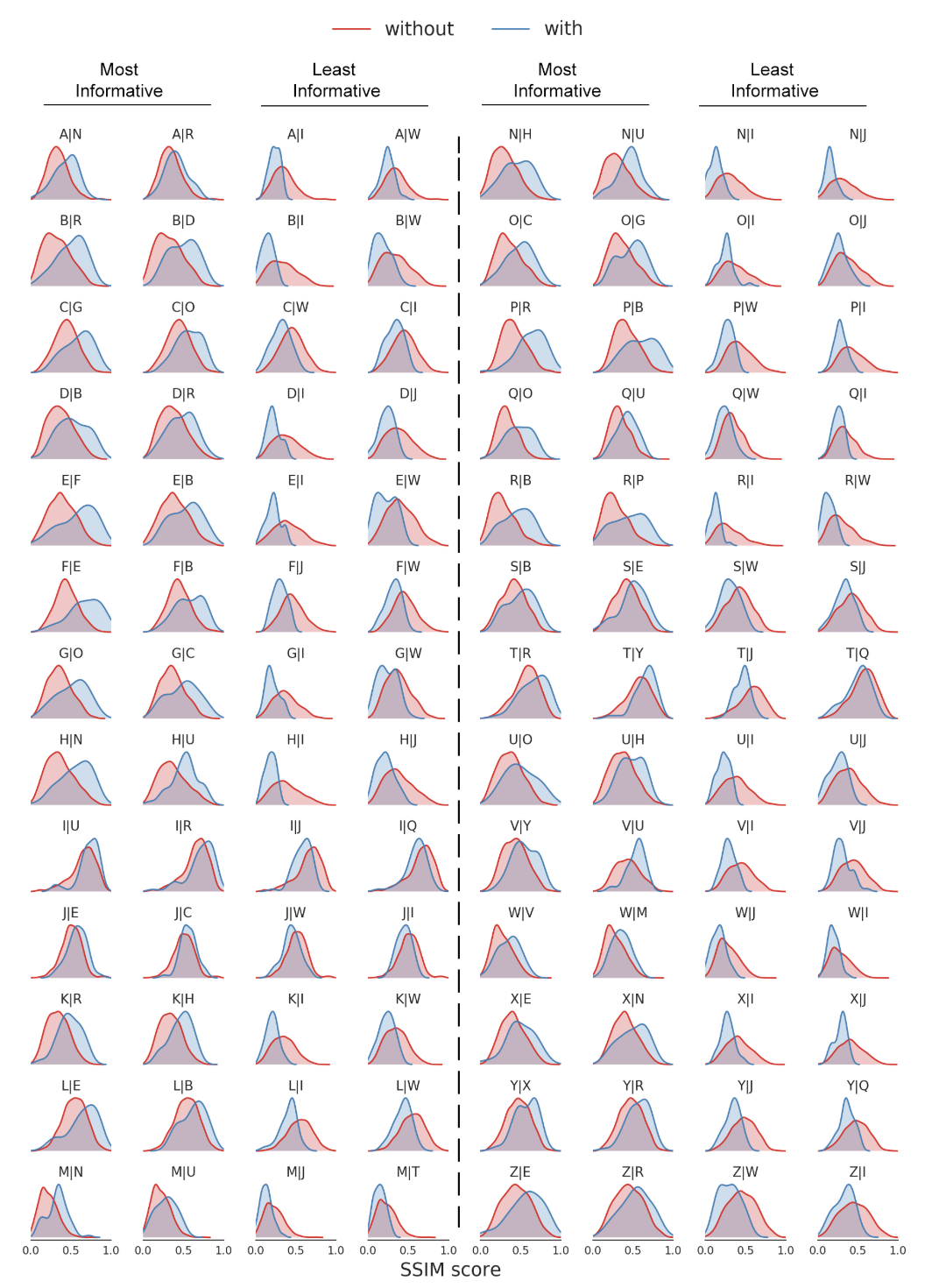
1500種類のフォントを学習したのち,生成画像と真値画像を比較,アルファベット間のstructural similarity (SSIM) を計算したものが下の図.SSIMはどれだけ
- 画素値(輝度値)の変化
- コントラストの変化
- 構造の変化
があるかの指標.http://visualize.hatenablog.com/entry/2016/02/20/144657
distributions α|β of generating letter α when letter β is observed (in blue) vs when any other letter rather than β is given (in red).
5行目を見ると,Eの構造はF, Bと似ていて,I, Wの構造とは似ていないということらしい(図の見方がよく分かりません...).
ここまでがGlyphNetのpre-train.
Ornamentation Network
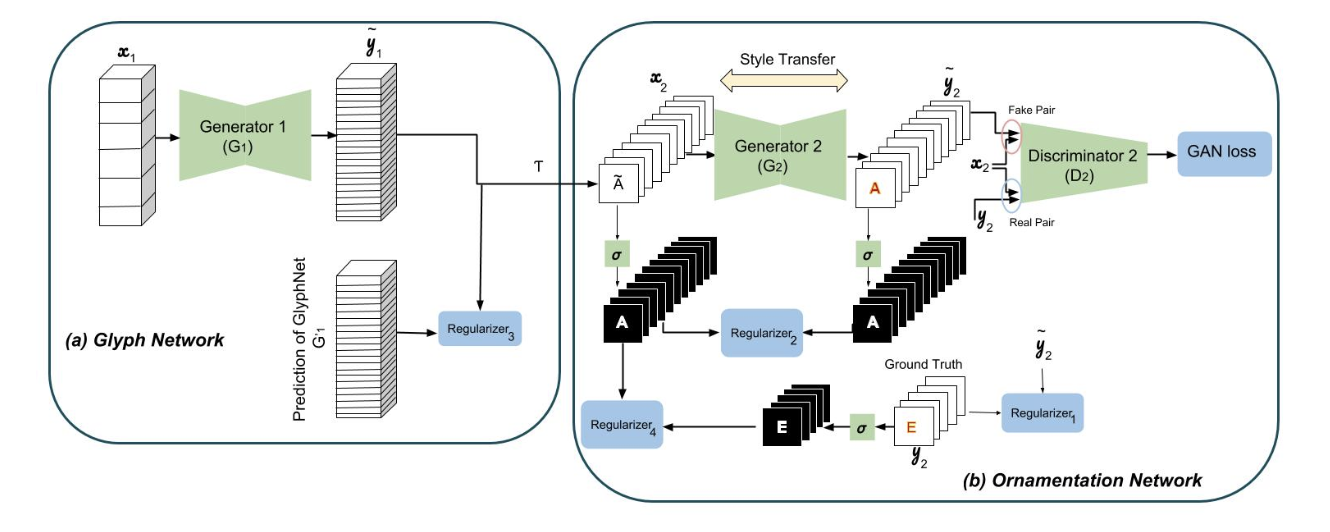
2つの図はどちらともMC-GANの全体図で,それぞれ右側がOrnamentation Network.上が記事内のもの,下が論文内のもの($D_2$の入力が分かりにくい).
Ornamentation NetworkではGlyph Networkの出力を入力として,色や装飾を施す.
GlyphNetは全てのフォントに対し,アルファベット間の相関を学習するが,OrnaNetは特定のフォントに対して学習を行う.
詳細は次の節.
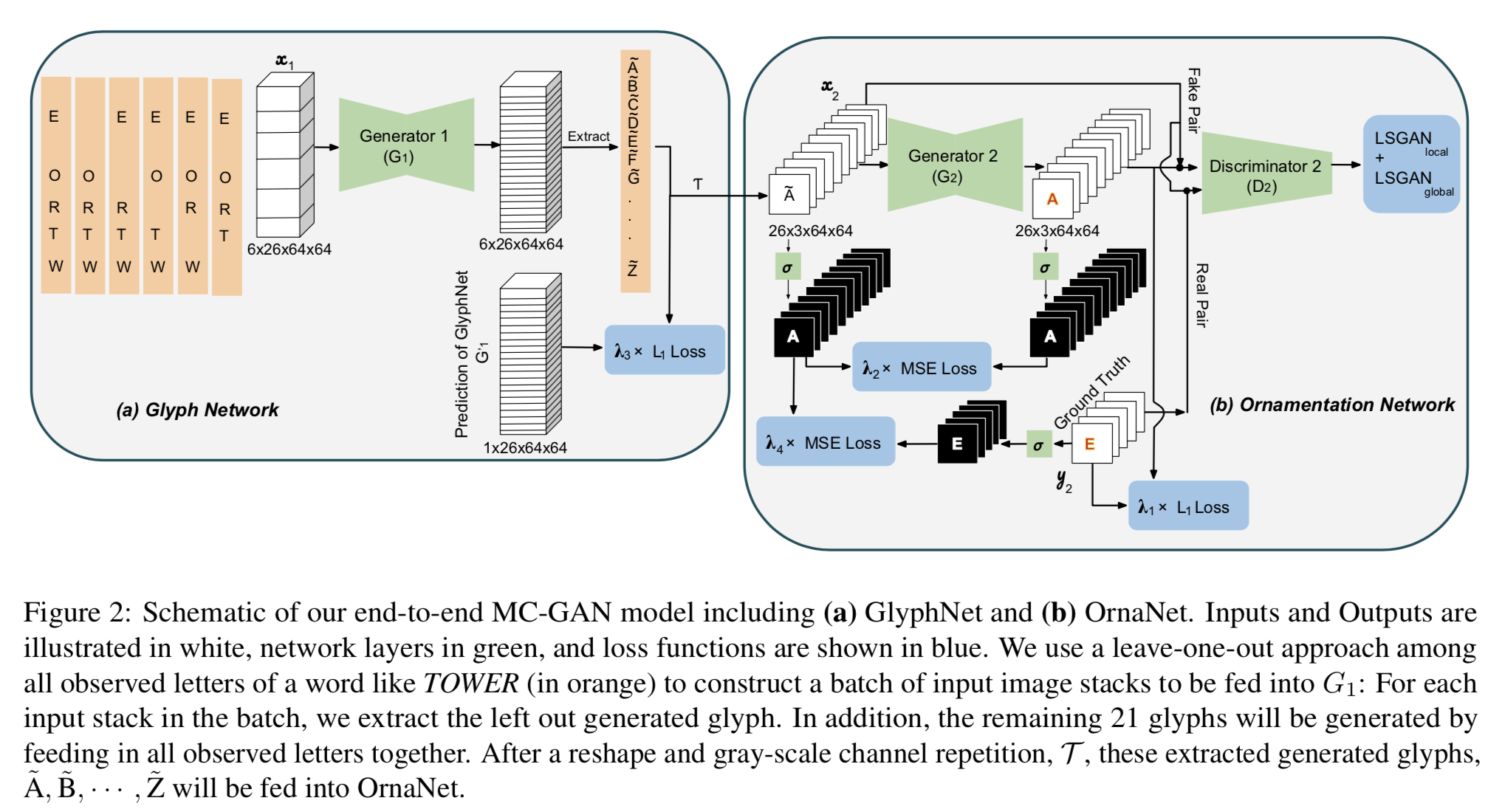
End-to-End Network
GlyphNetはpre-trainしておき,特定のフォントに対してEnd-to-Endでfine-tuningする.
End-to-Endで学習するために工夫(leave-one-out approach)をしている.
TOWERというアルファベットが既知である場合で考える.
- TOWEが既知としてRを出力する(1).それ以外の25チャネルはzeroing out.
- 同様にTOWEも出力できる(4).それ以外の25チャネルはzeroing out.
- TOWERが既知としてその他の21個のアルファベットを出力する(1).それ以外の5チャネルはzeroing out.
以上の3つを同時に行うと考えて入力は6x26x64x64(Figure 2のGlyphNetの入力の絵)
ロス関数は(Figure 2参照),
L(G_2) = L_{LSGAN}(G_2, D_2) + \lambda_1L_{L_1}(G_2) + \lambda_2L_{MSE}(G_2) \\
L_{LSGAN}(G_2, D_2) = L_{LSGAN}^{local}(G_2, D_2) + L_{LSGAN}^{global}(G_2, D_2)
L(G_1) = \lambda_3L_{w, L_1}(G_1) + \lambda_4L_{MSE}(G_1) \\
= \mathbb{E}_{x_1 \sim p_{data}(x_1), y_2 \sim p_{data}(y_2)}[\lambda_3 \sum_{i=1}^{26}w_i \times |G_1^i(x_1) - G_1^{'i}(x_1)| + \lambda_4(\sigma(y_2) - \sigma(T(G_1(x_1))))^2]
$G_1^{'}(x)$はend-to-endの学習で更新される前の,pre-train済みのGlyphNetの出力.
どうやって有効性を検証したか
Img Translation[11](pix2pix ?)との比較と,パッチベースの手法T-Effect[34]との比較を行なっている.
pre-trainに使用するFont Datasetを作成している.
- 10K gray-scale Latin fonts each with 26 capital letters
- 64x64
- このgray-scaleフォントデータセットをrandom color gradientsで20K color datasetとしたものがFont Dataset
- 現実に存在しないフォントだがpre-trainに使用できるのではないか
以下が10K gray-scaleフォントデータセットの一部.

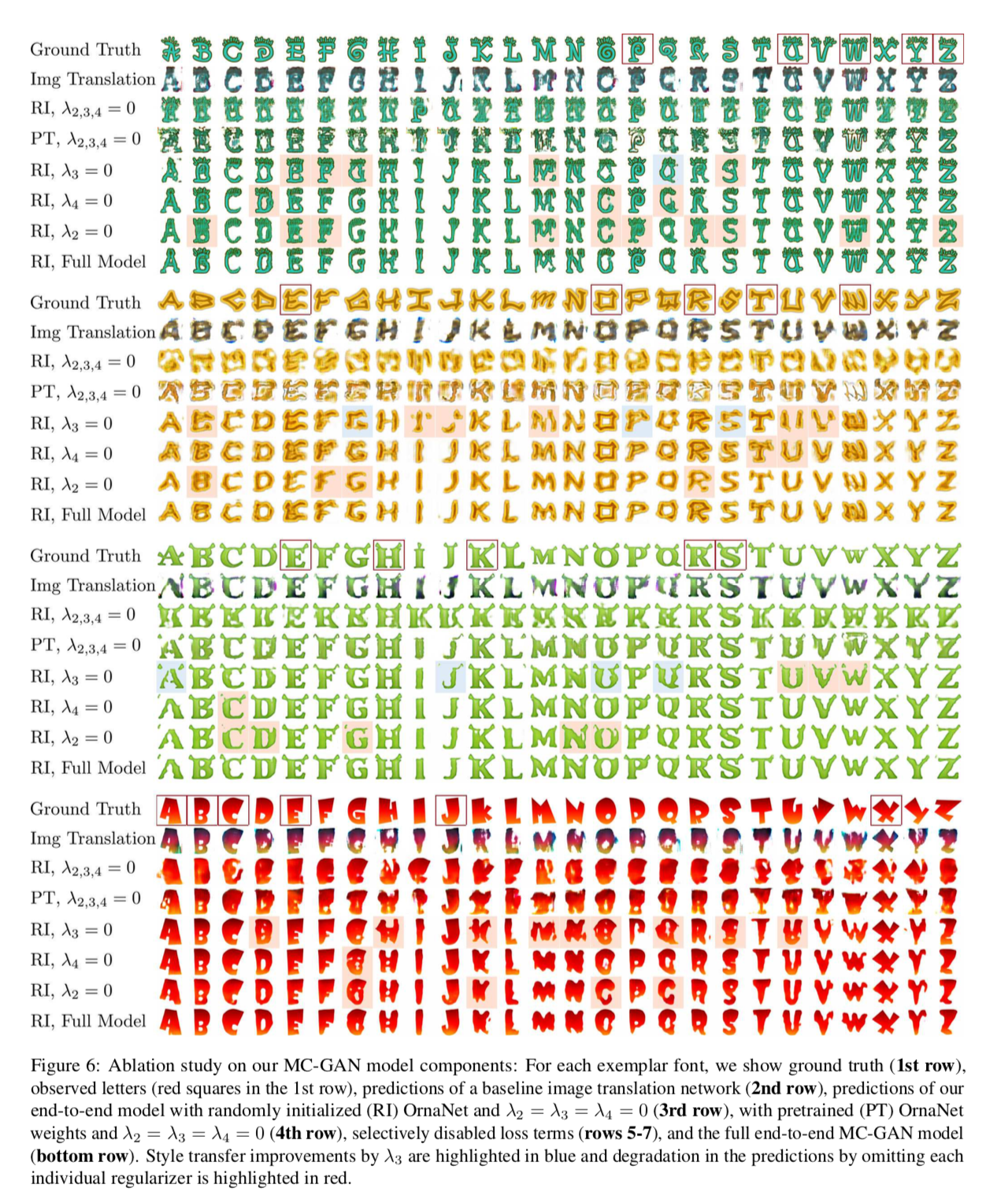
Img Translationとの比較
MC-GANの学習時の既知画像は26文字からランダムに3~8文字選択.
Img TranslationモデルはFont Datasetで学習.
以下が出力結果.
- 四角で囲まれたアルファベットが既知画像.
- RIはRandomly Initialized OrnaNet, PTはPreTrained OrnaNet.
- $\lambda_2, \lambda_3, \lambda_4$でロスの組み合わせを変えている.
- Img Translationの結果はフォントの正しい装飾を付けられておらず,アーティファクトが生じている.
- Font DatasetでのOrnaNetの初期化は役に立ってない.
- ロス$L_{w, L_1}(G_1)$($\lambda_3 L_{w, L_1}(G_1)$)は,pre-train済みのGlyphNetの推定から大きく離れないように学習を進めるための項だが,そうでもなく,結果にはtrade-offが生まれている.5行目の赤背景の出力は悪影響が出たもの,青背景は改善が見られたもの.
- その他の項($\lambda_2 L_{MSE}(G_2), \lambda_4 L_{MSE}(G_1)$)は,ブラーやノイズの低減に役立っている.
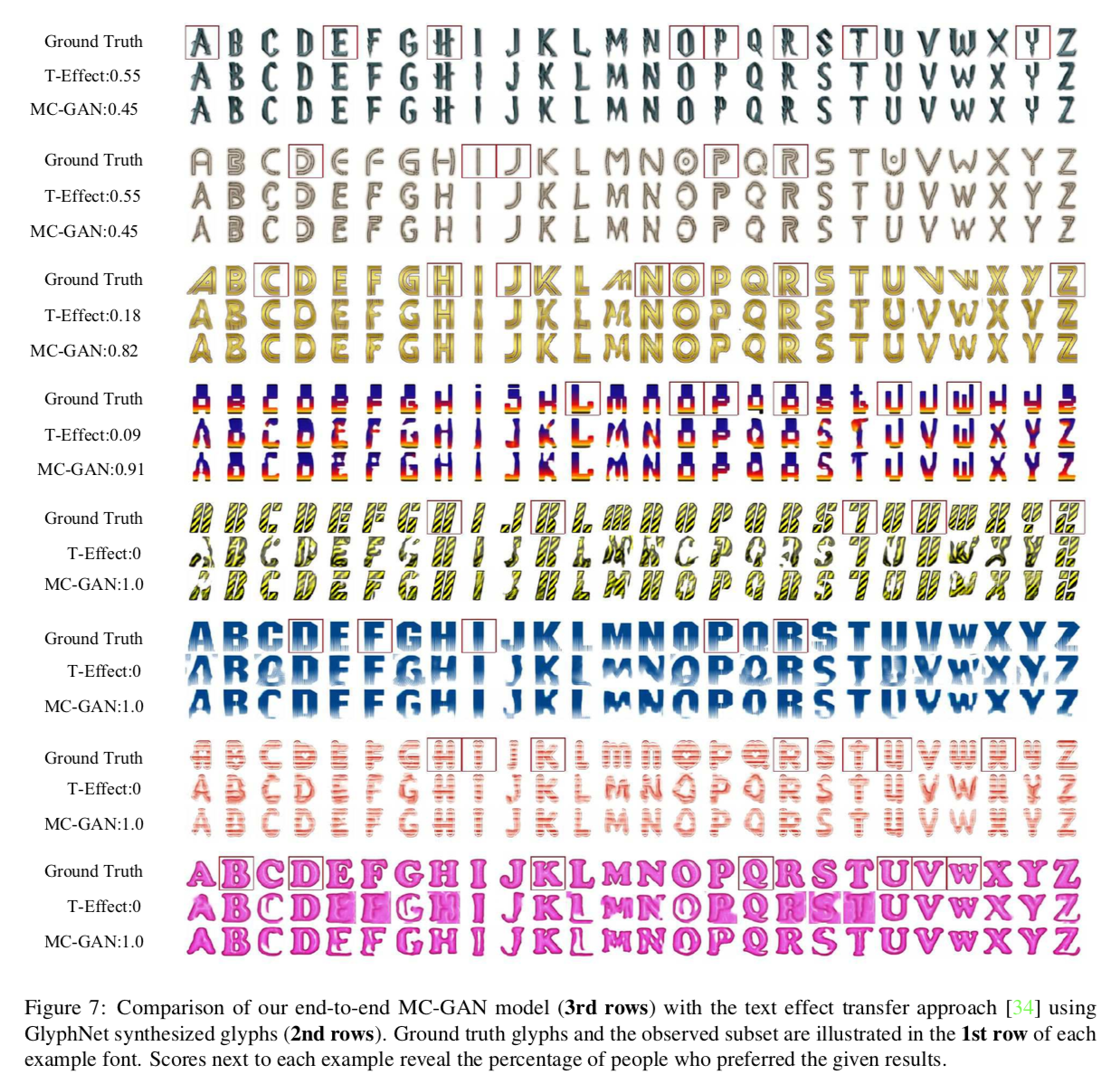
T-Effectとの比較
正しく比較をするために
- T-Effectの入力はpre-train済みのGlyphNetの出力とする.
- 比較手法の入力は1枚だけなので,入力には生成する文字に最もよく似た既知画像を選択する.
- ウェブ上の33のフォントで実験し,11人にどちらの手法の結果が良いか答えてもらう.
以下が出力結果.
上2行がT-Effectの評価が高かった上位2フォント,下2行がMC-GANの評価が高かった上位2フォント
- 80%の回答がMC-GANを選んだ
- T-Effectは綺麗な絵文字(clean glyphs)に施す手法であるため,GlyphNetの出力に対して変換を行うとほとんどの場合うまくいかなかった(比較の仕方に問題?).
- T-Effectはパッチベースのため,既知画像と未知画像の形が大きく異なる場合にうまく変換(straight patternなど)ができていない.MC-GANはその点でより良い結果が得られている.
正しい入力(ground-truth for GlyphNet)を与えた場合に,うまく装飾できるかの比較.
Figure 4はT-Effectがうまく変換できなかったフォント,Figure 5はどちらの手法もうまく変換できなかったフォント.
- MC-GANは存在する色を平均化してしまい,また目のような装飾を必ずしも生成できるわけではない.
- T-Effectは色の配置を保てているが,スタイルの要素を捉えられていない.

議論はあるか
- 一部の既知のアルファベット画像から,同じスタイルの未知のアルファベット画像を生成するend-to-endの学習手法を提案.
- フォントの形を学習するGlyphNet,装飾を学習するOrnaNetを提案.
- フォント画像は非常に高い解像度で生成する必要があり,階層的な生成や,直接的なベクタ画像の生成などへの拡張が必要.
今後は「少数のサンプルから,一貫したコンテンツを定式化」するその他の問題に取り組むつもり.例えば
- 特定の人物の顔(スタイル)を変更して特定の表現(コンテンツ)を持たせる
- 顔文字などの形状の一貫した定型化
- 材料を衣類や家具などの物体に移す
次に読むべき論文
GANでセマンティックセグメンテーションの性能向上
Conditional Generative Adversarial Network for Structured Domain Adaptation