Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, Martin Riedmiller
NIPS Deep Learning Workshop 2013
arXiv, pdf
どんなもの?
強化学習の行動価値関数Qの学習にDNNを使用(Deep Q-Networksを提案).
Arcade Learning Environment (ALE) にて7つのAtari 2600 gamesに対して実験を行った.
7つのうち6つのゲームのスコアで従来の学習手法を上回り,3つのゲームのスコアで人間(エキスパート)を上回った.

先行研究との差分
Q関数をDNNに.
入力はゲーム画面($84\times84\times4$).
これまでの手法のような事前の特徴量の設計が不要になった.
技術や手法のキモ
-
ロス関数
誤差計算の際,目標値に一つ前の反復におけるDNNの予測値を用いる. -
experience replay mechanism [Lin et al. 1993]
データの相関や学習の安定のために,過去の経験をメモリー (replay memory) に溜めておき,ランダムに選び学習に使用する.(?) -
報酬をゲームに依らず一定に
ゲームの種類によって報酬は異なるが,それを一定に(ポジティブな報酬は1,ネガティブな報酬は−1に). -
学習時の$\epsilon$
$\epsilon$-greedy法の$\epsilon$は初めの100万フレームで1から0.1に線形に落としていき,その後は0.1で固定. -
frame-skipping technique [Bellemare et al. 2013]
学習の効率化のために$k$フレーム毎の$k$枚の画像を使用して行動を選択($k=4$,Space Invaders は$k=3$).
どうやって有効性を検証したか
7種類の Atari 2600 games に対して実験を行い検証.
評価の方法としては,Bellemare et al.[3, 5]で用いられたものを使用.
$\epsilon=0.05$で固定.
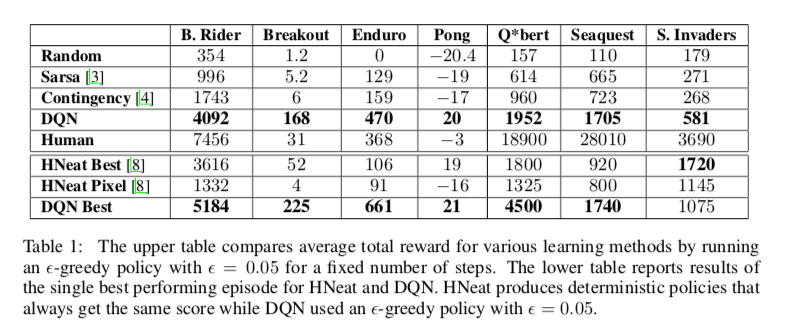
表の上側はゲーム毎の平均スコア.ほとんど事前の知識を情報として与えていないが,比較手法を上回っている.
表の下側は異なるアプローチの手法との比較.比較手法はhand-engineeredな物体検出アルゴリズムや,物体のラベルマップを使用しているものの,Space Invadersを除いて提案手法が比較手法を上回っている.

議論はあるか
新たな深層強化学習のモデルを提案した.
次に読むべき論文
DQN をもっと詳しく
比較手法
- Sarsa
- Contingency
- HNeat
深層強化学習の動向 / survey of deep reinforcement learningより,DQNの改良版.
- Double DQN
- Dueling DQN
- Prioritized Experience Replay
- 非同期学習