この記事は
Python, Tensorflowの実装を勉強中.
簡単なデータセット作成からCNNによる画像識別をやってみました.
十番煎じのような内容ですが,今回はバーチャルYouTuber(以下VTuber)画像をYouTubeから取得し,識別してみます.

実行環境
- Ubuntu 16.04
- Python 3.5.2
- Tensorflow 1.4.0
- Opencv 3.4.1
データセット作成
画像を使用させて頂くVTuberさん
今回はVTuber四天王と呼ばれる5名のVTuberの識別に取り組みます.
キズナアイ(A.I.Channel)
チャンネル登録者数トップのVTuberの代表的存在です.メインチャンネルのやってみた系以外にも,サブチャンネルではゲーム実況もされており,ホラーゲーム実況では叫びまくっています.また,CGモデルが非常に美しいです.

ミライアカリ(Mirai Akari Project)
元気いっぱいで明るく,下ネタもイケるVTuberです.5名のVTuberの中で(おそらく)唯一胸が揺れます.

輝夜月(Kaguya Luna Official)
ハイテンションで非常に面白いVTuberです.モノマネが上手で,一度聞いたら忘れられない特徴的な声をしています.そして僕の推しです.

電脳少女シロ(Siro Channel)
5名の中では最もおしとやかな雰囲気のVTuberです.笑うとイルカの鳴き声が聞こえます.また,普段はおしとやかでニコニコしているのですが,ゲーム実況の際には言葉遣いが荒くなってしまいます.

バーチャルのじゃロリ狐娘Youtuberおじさん(バーチャル番組チャンネル(旧 けもみみおーこく国営放送))
ねこみみマスター(ねこます)と呼ばれます.見た目は小さく可愛らしい女の子なのですが,声はおじさんというインパクトの強いVTuberです.シュールな語りがツボです.チャンネルは現在,VTuberによる番組「Vaんぐみ」の配信に取り組まれています.

https://twitter.com/kemomimi_oukoku
pytubeによる動画の取得
pytubeを利用してYouTubeから動画をダウンロードします.しかしながら,YouTubeから動画をダウンロードすること自体あまりよろしいものでは無く,当たり前ですが著作者の権利を侵害しない範囲で使用しなければなりません.
pytubeは以下のようにインストールします.
$ pip install pytube
今回は各VTuber5本ずつの動画を使用します.ディレクトリの構造は以下のようになります.以下のdownload_videos.pyを実行することで動画をVTuberごとに保存します.
+ VTuber_recognition
+ download_videos.py
+ video
+ KizunaAI
+ video-00.mp4
+ video-01.mp4
+ ...
+ MiraiAkari
+ KaguyaLuna
+ Siro
+ NekoMas
from pytube import YouTube
import os
import glob
def download_video(link, save_dir):
print('Download %s to %s ...' %(link, save_dir))
YouTube(link).streams.first().download(save_dir)
print('Done\n')
links0 = ['https://www.youtube.com/watch?v=NasyGUeNMTs',
'https://www.youtube.com/watch?v=pU3iGpwKxKc',
'https://www.youtube.com/watch?v=6TdtxElNCtI',
'https://www.youtube.com/watch?v=lL74n-Vr91k',
'https://www.youtube.com/watch?v=oAuOjG4L1Ng',] # Kizuna AI
links1 = ['https://www.youtube.com/watch?v=0V1vk83iV-o',
'https://www.youtube.com/watch?v=TwMkoEuQNAk',
'https://www.youtube.com/watch?v=b_SEEnVq_GM',
'https://www.youtube.com/watch?v=ce7Xy8wvMzI',
'https://www.youtube.com/watch?v=2L7X1UQFWgI'] # Mirai Akari
links2 = ['https://www.youtube.com/watch?v=TeKTVFgw1hM',
'https://www.youtube.com/watch?v=dzEk6wZ4Xuc',
'https://www.youtube.com/watch?v=zdneuijW_70',
'https://www.youtube.com/watch?v=GG7nBgIHmKw',
'https://www.youtube.com/watch?v=ZJinxt-wui0'] # Kaguya Luna
links3 = ['https://www.youtube.com/watch?v=fLC5TE_KYcw',
'https://www.youtube.com/watch?v=KmfGNTbMNBk',
'https://www.youtube.com/watch?v=t1V8O7q0bA8',
'https://www.youtube.com/watch?v=lqUQWwK3Xag',
'https://www.youtube.com/watch?v=vcxW5AcyAWU'] # Siro
links4 = ['https://www.youtube.com/watch?v=cqncAh_28Es',
'https://www.youtube.com/watch?v=DoVh4Fc43Bo',
'https://www.youtube.com/watch?v=0q4CQEw60IM',
'https://www.youtube.com/watch?v=L5sy3wgNwaI',
'https://www.youtube.com/watch?v=QDWKOzum6F8'] # Neko Mas
links_all = [links0, links1, links2, links3, links4]
save_dirs = ['./video/KizunaAI',
'./video/MiraiAkari',
'./video/KaguyaLuna',
'./video/Siro',
'./video/NekoMas']
for (links, dir) in zip(links_all, save_dirs):
for link in links:
download_video(link, dir)
videos = glob.glob(os.path.join(dir, '*.mp4'))
for (n, video) in enumerate(videos):
os.rename(video, os.path.join(dir, 'video-{:02}.mp4'.format(n)))
顔画像の切り出し
動画から顔画像を切り出します.
方針は
- OpenCVとlbpcascade_animefaceを使用して,動画からアニメ顔の切り出し
- 128x128にリサイズして保存
- その後,誤検出画像を除去
lbpcascade_animefaceからダウンロードした.xmlファイルはVTuber_recognitionディレクトリ下に置きます.以下のmovie2image.pyを実行することで,faceディレクトリ下に検出した顔画像を保存します.その後,手作業で誤検出画像を除去します.
+ VTuber_recognition
+ download_videos.py
+ movie2face.py
+ video
+ image
+ KizunaAI
+ ...
+ face
+ KizunaAI
+ ...
+ lbpcascade_animeface.xml
import cv2
import glob
import os
def movie_to_image(video_paths, out_image_path, num_cut=10):
img_count = 0
for video_path in video_paths:
print(video_path)
capture = cv2.VideoCapture(video_path)
frame_count = 0
while(capture.isOpened()):
ret, frame = capture.read()
if ret == False:
break
if frame_count % num_cut == 0:
img_file_name = os.path.join(out_image_path, '{:05d}.jpg'.format(img_count))
cv2.imwrite(img_file_name, frame)
img_count += 1
frame_count += 1
capture.release()
def face_detect(out_face_path, img_list):
xml_path = './lbpcascade_animeface.xml'
classifier = cv2.CascadeClassifier(xml_path)
img_count = 0
for img_path in img_list:
org_img = cv2.imread(img_path, cv2.IMREAD_COLOR)
gray_img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
face_points = classifier.detectMultiScale(gray_img,
scaleFactor=1.1,
minNeighbors=2,
minSize=(30,30))
for points in face_points:
x, y, width, height = points
dst_img = org_img[y:y+height, x:x+width]
face_img = cv2.resize(dst_img, (128,128))
new_img_name = os.path.join(out_face_path, '{:05d}.jpg'.format(img_count))
cv2.imwrite(new_img_name, face_img)
img_count += 1
if __name__ == '__main__':
VTubers = ['KizunaAI', 'MiraiAkari', 'KaguyaLuna', 'Siro', 'NekoMas']
for VTuber in VTubers:
print(VTuber)
video_dir = os.path.join('./video', VTuber)
video_paths = glob.glob(os.path.join(video_dir, '*.mp4'))
out_image_path = os.path.join('./image/', VTuber) # './image/KizunaAI'
out_face_path = os.path.join('./face/', VTuber) # './face/KizunaAI'
print('Movie to image ...')
movie_to_image(video_paths, out_image_path, num_cut=10) # save image every 10 frame
print('Save %s faces ...' %(VTuber))
face_detect(out_face_path, images) # save face images
顔画像は
- キズナアイ:2948枚
- ミライアカリ:4430枚
- 輝夜月:3799枚
- シロ:4690枚
- ねこます:2651枚
集まりました.画像にノイズが少ないので簡単に識別できそうです.





TFRecords形式で保存
画像と正解ラベルの対を,TFRecords形式で保存します.直接画像を読み込むよりも,TFRecords形式に変換したものを使用する方が高速に処理できるようです.
以下のmake_tfrecords.pyを実行することで,TFRecords形式で訓練データ,テストデータを保存します.各VTuberの顔画像の9割を訓練に,1割をテストに使用します.
+ VTuber_recognition
+ download_videos.py
+ movie2face.py
+ make_tfrecords.py
+ video
+ image
+ face
+ train_tfrecords
+ ***.tfrecords
+ ...
+ test_tfrecords
+ ***.tfrecords
+ ...
+ lbpcascade_animeface.xml
from PIL import Image
import os
import numpy as np
import tensorflow as tf
import glob
import random
OUTPUT_TRAIN_TFRECORD_DIR = './train_tfrecords'
OUTPUT_TEST_TFRECORD_DIR = './test_tfrecords'
# https://www.tdi.co.jp/miso/tensorflow-tfrecord-01
def make_tfrecords(file, label, base, outdir):
print(base)
tfrecords_filename = os.path.join(outdir, '{}.tfrecords'.format(base))
writer = tf.python_io.TFRecordWriter(tfrecords_filename)
with Image.open(file) as image_object: # (128x128x3) image
image = np.array(image_object)
height = image.shape[0]
width = image.shape[1]
dim = image.shape[2]
example = tf.train.Example(features=tf.train.Features(feature={
"height": tf.train.Feature(int64_list=tf.train.Int64List(value=[height])),
"width" : tf.train.Feature(int64_list=tf.train.Int64List(value=[width])),
"dim" : tf.train.Feature(int64_list=tf.train.Int64List(value=[dim])),
"label" : tf.train.Feature(int64_list=tf.train.Int64List(value=[label])),
"image" : tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_object.tobytes()]))
}))
writer.write(example.SerializeToString())
writer.close()
def divide_train_test(face, train_ratio):
face_num = len(face)
divide_idx = int(face_num * train_ratio)
train, test = face[:divide_idx], face[divide_idx:]
return train, test
random.seed(1)
KizunaAI_face = glob.glob('./face/KizunaAI/*.jpg')
random.shuffle(KizunaAI_face)
print('Num of KizunaAI faces : %d' %(len(KizunaAI_face)))
KizunaAI_train, KizunaAI_test = divide_train_test(KizunaAI_face, train_ratio=0.9)
MiraiAkari_face = glob.glob('./face/MiraiAkari/*.jpg')
random.shuffle(MiraiAkari_face)
print('Num of MiraiAkari faces : %d' %(len(MiraiAkari_face)))
MiraiAkari_train, MiraiAkari_test = divide_train_test(MiraiAkari_face, train_ratio=0.9)
KaguyaLuna_face = glob.glob('./face/KaguyaLuna/*.jpg')
random.shuffle(KaguyaLuna_face)
print('Num of KaguyaLuna faces : %d' %(len(KaguyaLuna_face)))
KaguyaLuna_train, KaguyaLuna_test = divide_train_test(KaguyaLuna_face, train_ratio=0.9)
Siro_face = glob.glob('./face/Siro/*.jpg')
random.shuffle(Siro_face)
print('Num of Siro faces : %d' %(len(Siro_face)))
Siro_train, Siro_test = divide_train_test(Siro_face, train_ratio=0.9)
NekoMas_face = glob.glob('./face/NekoMas/*.jpg')
random.shuffle(NekoMas_face)
print('Num of NekoMas faces : %d' %(len(NekoMas_face)))
NekoMas_train, NekoMas_test = divide_train_test(NekoMas_face, train_ratio=0.9)
# for train data
if not os.path.exists(OUTPUT_TRAIN_TFRECORD_DIR):
os.makedirs(OUTPUT_TRAIN_TFRECORD_DIR)
num = 0
for (label, files) in enumerate([KizunaAI_train, MiraiAkari_train, KaguyaLuna_train, Siro_train, NekoMas_train]):
print(label, len(files))
for file in files:
base = '{:05}'.format(num)
make_tfrecords(file, label, base, outdir=OUTPUT_TRAIN_TFRECORD_DIR)
num += 1
# for test data
if not os.path.exists(OUTPUT_TEST_TFRECORD_DIR):
os.makedirs(OUTPUT_TEST_TFRECORD_DIR)
num = 0
for (label, files) in enumerate([KizunaAI_test, MiraiAkari_test, KaguyaLuna_test, Siro_test, NekoMas_test]):
print(label, len(files))
for file in files:
base = '{:05}'.format(num)
make_tfrecords(file, label, base, outdir=OUTPUT_TEST_TFRECORD_DIR)
num += 1
訓練データ,テストデータをそれぞれ1つのTFRecordsファイルに保存できればよかったのですが,うまくいきませんでした(アドバイス頂きたいです...).これらのサイト[1][2]を参考にするとうまく作れるかも.
CNNモデル構築,訓練・テスト
最終的なディレクトリの構造は以下のようになります.
+ VTuber_recognition
+ download_videos.py
+ movie2face.py
+ make_tfrecords.py
+ model.py
+ train.py
+ test.py
+ video
+ image
+ face
+ RESULT
+ logdir
+ train_tfrecords
+ test_tfrecords
+ lbpcascade_animeface.xml
CNNモデル
畳み込み4層,プーリング4層,全結合2層のシンプルなネットワークを使用します.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
def weight_variable(shape, name):
"""weight_variable generates a weight variable of a given shape."""
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name=name)
def bias_variable(shape, name):
"""bias_variable generates a bias variable of a given shape."""
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial, name=name)
def conv2d(x, receptive_field, channels, name):
kernel_shape = receptive_field + channels
bias_shape = [channels[-1]]
W = weight_variable(kernel_shape, name+'-W')
b = bias_variable(bias_shape, name+'-b')
conv = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
conv_bias = tf.nn.bias_add(conv, b)
return tf.nn.relu(conv_bias)
def inference(input, batch_size, is_training=True):
# 3x128x128
print("input ", input.shape)
with tf.name_scope('conv1'): # conv 5x5
h_conv1 = conv2d(input, [5, 5], [3, 16], 'conv1')
print("h_conv1 ", h_conv1.shape)
# 16x128x128
with tf.name_scope('pool1'): # pooling 3x3
h_pool1 = tf.nn.max_pool(h_conv1,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1], padding='SAME')
print("h_pool1 ", h_pool1.shape)
# 16x64x64
with tf.name_scope('conv2'): # conv 5x5
h_conv2 = conv2d(h_pool1, [5, 5], [16, 32], 'conv2')
print("h_conv2 ", h_conv2.shape)
# 32x64x64
with tf.name_scope('pool2'): # pooling 3x3
h_pool2 = tf.nn.max_pool(h_conv2,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1], padding='SAME')
print("h_pool2 ", h_pool2.shape)
# 32x32x32
with tf.name_scope('conv3'): # conv 3x3
h_conv3 = conv2d(h_pool2, [3, 3], [32, 64], 'conv3')
print("h_conv3 ", h_conv3.shape)
# 64x32x32
with tf.name_scope('pool3'): # pooling 3x3
h_pool3 = tf.nn.max_pool(h_conv3,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1], padding='SAME')
print("h_pool3 ", h_pool3.shape)
# 64x16x16
with tf.name_scope('conv4'): # conv 3x3
h_conv4 = conv2d(h_pool3, [3, 3], [64, 128], 'conv4')
print("h_conv4 ", h_conv4.shape)
# 128x16x16
with tf.name_scope('pool4'): # pooling 3x3
h_pool4 = tf.nn.max_pool(h_conv4,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1], padding='SAME')
print("h_pool4 ", h_pool4.shape)
# 128x8x8 = 8192
with tf.name_scope('fc1'):
h_pool4_flat = tf.reshape(h_pool4, [batch_size, -1])
dim = h_pool4_flat.get_shape()[1].value
W_fc1 = weight_variable([dim, 1024], 'fc1-W')
b_fc1 = bias_variable([1024], 'fc1-b')
h_fc1 = tf.nn.relu(tf.matmul(h_pool4_flat, W_fc1) + b_fc1)
print("h_fc1 ", h_fc1.shape)
with tf.name_scope('dropout1'):
h_fc1_drop = tf.layers.dropout(h_fc1, rate=0.2, training=is_training) rate=drop rate
# 1024
with tf.name_scope('fc2'):
W_fc2 = weight_variable([1024, 5], 'fc2-W')
b_fc2 = bias_variable([5], 'fc2-b')
h_fc2 = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
print("h_fc2 ", h_fc2.shape)
return h_fc2
訓練
先ほどのモデルファイルをインポートして使用します.訓練にはSupervisorクラスを使用します.変数(save_sumaries_secs, save_model_secs)を指定するだけで,何秒ごとにサマリーやモデルを出力するか設定できて便利です.
read_and_decodeでTFRecordsから画像へ変換し,inputsで画像とラベルのミニバッチを出力します.
また,100ステップごとに識別結果を出力します(が,これをやるとキューからデータを取ってきてしまい,訓練をキッチリNUM_EPOCHS分できない...).
import numpy as np
import tensorflow as tf
import time
import model
from tensorflow import gfile
from tensorflow import logging
from datetime import datetime
BATCH_SIZE = 100
NUM_EPOCHS = 10
LEARNING_RATE = 0.001
LOGDIR = './logdir/'
IMAGE_WIDTH = 128
IMAGE_HEIGHT = 128
IMAGE_CHANNE = 3
TARGET_SIZE = 5
INPUT_TRAIN_TFRECORD = './train_tfrecords/*.tfrecords'
def read_and_decode(filename_queue):
reader = tf.TFRecordReader()
key, value = reader.read(filename_queue)
features = tf.parse_single_example(
value,
features={'label' : tf.FixedLenFeature([], tf.int64, default_value=0),
'image' : tf.FixedLenFeature([], tf.string, default_value=""),
'height' : tf.FixedLenFeature([], tf.int64, default_value=0),
'width' : tf.FixedLenFeature([], tf.int64, default_value=0),
'dim' : tf.FixedLenFeature([], tf.int64, default_value=0)
})
label = tf.cast(features['label'], tf.int32)
label = tf.one_hot(label, TARGET_SIZE)
height = tf.cast(features['height'], tf.int32)
width = tf.cast(features['width'], tf.int32)
dim = tf.cast(features['dim'], tf.int32)
image = tf.decode_raw(features['image'], tf.uint8)
image = tf.cast(image, tf.float32)
image = image / 255 # 0~1
image = tf.reshape(image, [IMAGE_HEIGHT, IMAGE_WIDTH, IMAGE_CHANNE])
return image, label
def inputs(batch_size, num_epochs, input_tfrecord):
if not num_epochs:
num_epochs = None
with tf.name_scope('input'):
files = gfile.Glob(input_tfrecord)
files = sorted(files)
print("files num : ", len(files))
if not files:
raise IOError("Unable to find training files. data_pattern='" +
input_tfrecord + "'.")
logging.info("Number of training files: %s.", str(len(files)))
filename_queue = tf.train.string_input_producer(files,
num_epochs=num_epochs,
shuffle=True)
image, label = read_and_decode(filename_queue)
print("image :", image.shape)
print("label :", label.shape)
image_batch, label_batch = tf.train.shuffle_batch(
[image, label],
batch_size=batch_size,
num_threads=10,
capacity=10000 + 15 * batch_size,
min_after_dequeue=10000,
allow_smaller_final_batch=False # True --> error ...
)
tf.summary.image('input', image_batch)
return image_batch, label_batch
if __name__ == "__main__":
with tf.Graph().as_default():
print('Reading batches...')
image_batch, label_batch = inputs(batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
input_tfrecord=INPUT_TRAIN_TFRECORD)
print('build models...')
y_conv = model.inference(image_batch, BATCH_SIZE, is_training=True)
with tf.name_scope('train'):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y_conv, labels=label_batch))
tf.summary.scalar('loss', loss)
global_step = tf.Variable(0, trainable=False)
k = 100 * 10**3 # 100k steps
learning_rate = tf.train.inverse_time_decay(LEARNING_RATE, global_step, k, 1, staircase=True)
train_step = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss, global_step=global_step)
# calculate accuracy
with tf.name_scope('test'):
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(label_batch, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sv = tf.train.Supervisor(logdir=LOGDIR,
global_step=global_step,
save_summaries_secs=10,
save_model_secs=120)
with sv.managed_session(config=config) as sess:
print('start loop...' + datetime.now().strftime("%Y%m%d-%H%M%S"))
try:
step = 0
while not sv.should_stop():
start_time = time.time()
_, loss_value, g_step = sess.run([train_step, loss, global_step])
duration = time.time() - start_time
print('Step train %04d : loss = %07.4f (%02.3f sec)' % (g_step,
loss_value,
duration))
if step % 100 == 0:
est_accuracy, est_y, gt_y = sess.run([accuracy, y_conv, label_batch])
print("Accuracy (for test data): {:5.2f}".format(est_accuracy))
print("True Label:", np.argmax(gt_y[0:15,], 1))
print("Est Label :", np.argmax(est_y[0:15, ], 1))
step += 1
except tf.errors.OutOfRangeError:
print('Done training for %d epochs, %d steps.' %
(NUM_EPOCHS, step))
sv.Stop()
print('End loop...' + datetime.now().strftime("%Y%m%d-%H%M%S"))
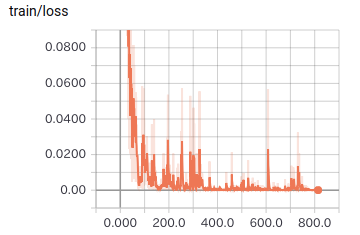
以下が訓練ロスと正解率です.正解率は「訓練データに対する正解率」です.訓練が進むにつれて正解率が上がっていることが分かります.

テスト
訓練で保存されたモデルパラメータをlogdirからロードしてテストします.Supervisorクラスを使用すると,勝手にlogdir内の最新のモデルをロードしてくれるみたいです.
テスト時には,画像にクラス事後確率を書き込んでRESULTフォルダに保存します(save_result).
import numpy as np
import tensorflow as tf
import time
import model
from tensorflow import gfile
from tensorflow import logging
from datetime import datetime
from PIL import Image, ImageDraw, ImageFont
from operator import itemgetter
BATCH_SIZE = 100
NUM_EPOCHS = 1
LOGDIR = './logdir/'
IMAGE_WIDTH = 128
IMAGE_HEIGHT = 128
IMAGE_CHANNE = 3
TARGET_SIZE = 5
INPUT_TEST_TFRECORD = './test_tfrecords/*.tfrecords'
def read_and_decode(filename_queue):
reader = tf.TFRecordReader()
key, value = reader.read(filename_queue)
features = tf.parse_single_example(
value,
features={'label': tf.FixedLenFeature([], tf.int64, default_value=0),
'image': tf.FixedLenFeature([], tf.string, default_value="")
})
label = tf.cast(features['label'], tf.int32)
label = tf.one_hot(label, TARGET_SIZE)
image = tf.decode_raw(features['image'], tf.uint8)
image = tf.cast(image, tf.float32)
image = image / 255 # 0~1
image = tf.reshape(image, [IMAGE_HEIGHT,IMAGE_WIDTH,IMAGE_CHANNE])
return image, label
def inputs(batch_size, num_epochs, input_tfrecord):
if not num_epochs:
num_epochs = None
with tf.name_scope('input'):
files = gfile.Glob(input_tfrecord)
files = sorted(files)
print("files num : ", len(files))
if not files:
raise IOError("Unable to find training files. data_pattern='" +
input_tfrecord + "'.")
logging.info("Number of training files: %s.", str(len(files)))
filename_queue = tf.train.string_input_producer(files,
num_epochs=num_epochs,
shuffle=False)
image, label = read_and_decode(filename_queue)
print("image :", image.shape)
print("label :", label.shape)
image_batch, label_batch = tf.train.shuffle_batch(
[image, label],
batch_size=batch_size,
num_threads=10,
capacity=10000 + 15 * batch_size,
min_after_dequeue=10000,
allow_smaller_final_batch=False # True --> error ...
)
return image_batch, label_batch
def save_result(image_batch_step, softmax_step, step):
label = ['KizunaAI', 'MiraiAkari', 'KaguyaLuna', 'Siro', 'NekoMas']
for i, (image, softmax) in enumerate(zip(image_batch_step, softmax_step)):
label_tuples = []
for (l, s) in zip(label, softmax):
label_tuples.append((l, s))
label_tuples = sorted(label_tuples, key=itemgetter(1), reverse=True)
image = image * 255
image = Image.fromarray(np.uint8(image))
draw = ImageDraw.Draw(image)
font = ImageFont.truetype("/home/user/.fonts/Ubuntu-L.ttf", 10)
for (j, r) in enumerate(label_tuples):
l, s = r
draw.text((10, j * 10), l + ' : {:.3f}'.format(s), fill=(255, 0, 0), font=font)
image.save('./RESULT/' + str(step) + '-' + str(i) + '.jpg')
if __name__ == "__main__":
with tf.Graph().as_default():
print('Reading batches...')
image_batch, label_batch = inputs(batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
input_tfrecord=INPUT_TEST_TFRECORD)
print('build models...')
y_conv = model.inference(image_batch, BATCH_SIZE, is_training=False)
softmax = tf.nn.softmax(y_conv)
global_step = tf.Variable(0, trainable=False)
# calculate accuracy
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(label_batch, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sv = tf.train.Supervisor(logdir=LOGDIR,
global_step=global_step)
with sv.managed_session(config=config) as sess:
print('start loop...' + datetime.now().strftime("%Y%m%d-%H%M%S"))
try:
step = 0
accu_all = []
while not sv.should_stop():
start_time = time.time()
accu_step, softmax_step, image_batch_step, g_step \
= sess.run([accuracy, softmax, image_batch, global_step])
accu_all.append(accu_step)
print(softmax_step[:10])
save_result(image_batch_step, softmax_step, step)
duration = time.time() - start_time
print('Step test %04d: accu = %07.4f (%02.3f sec)' %(step,
accu_step,
duration))
step += 1
except tf.errors.OutOfRangeError:
print('Done testing for %d epochs, %d steps.' %
(NUM_EPOCHS, step))
accu_all_mean = np.array(accu_all).mean()
print("accu_all_mean : ", accu_all_mean)
sv.Stop()
print('End loop...' + datetime.now().strftime("%Y%m%d-%H%M%S"))
以下はRESULTフォルダの25枚の画像です.識別できているようです.

まとめ
YouTube動画から集めた画像データセットを用いて,CNNで識別してみました.画像中のノイズが少なく,それぞれのVTuberに見た目の個性があったからか,データ拡張をしなくてもほぼ100%識別できました.
まだまだ一般的な書き方(書き方の作法的な?)が分かっていないので,ご指摘,アドバイス等ありましたら,コメント頂きたいです m(_ _)m
今回使用したコードはこちらにアップしました.
参考サイト
- pytube
- 顔画像切り出し
- Supervisor
- その他