Wengling Chen, James Hays
CVPR2018
arXiv, pdf
どんなもの?
スケッチから(50クラスの)写真を生成するGAN, SketchyGANを提案.

先行研究との差分
- 従来の手法はスケッチから似ている写真を検索する方法が多かったが,提案手法ではスケッチから新たな写真を生成する
- スケッチのための自動でのデータ拡張手法も提案,有効性を確認
- 新たなロス関数と**Masked Residual Unit (MRU)**を提案

技術や手法のキモ
Sketchy Database Augmentation
Edges vs Sketches
- エッジ
- 物体の輪郭を必ずしも表さない
- 写真全体の情報を持つ(背景のエッジなど)
- スケッチ
- 物体の輪郭をはっきりと表す傾向
- メインの物体の情報しか持たない(猫しか描かない)
- 物体の象徴となる特徴が含まれる(猫に虎の縞模様を描く)
→ エッジはデータ拡張に有効なのでは

Data Collection
Flickrから各カテゴリーで10万枚の画像を取得.
- Inception-ResNet-v2を用いたフィルタリング
- 38カテゴリー(ImageNet $\cap$ Sketchy Database),各カテゴリー平均で46265枚取得
- Single Shot MultiBox Detectorを用いたフィルタリング
- 18カテゴリー(COCO $\cap$ Sketchy Database),各カテゴリー平均で61365枚取得
- 人物がメインで映る6カテゴリー(violin, umbrella, trumpetなど)を除外(38 + 18 - 6 = 50)
Edge Map Creation
エッジを検出,二値化,縮小などして作成.
5.1. Experiment settingsで"Both sketches and edge maps are converted into distance fields."とあることから,スケッチ画像とエッジ画像をdistance fieldに変換したもので学習か.

Training Adaptation from Edges to Sketches
学習の初めはエッジマップとペアの画像で学習し,徐々にスケッチとペアの画像で学習するようにスケジューリング.
こうすることで,エッジマップでpre-trainする必要が無くなる.
ちなみにInception scoreで6.73 vs 7.90 (pre-train and fine-tuning vs unified).
SketchyGAN
Masked Residual Unit (MRU)
前の層の特徴マップ($x_i$)と比較して,新たな特徴量($y_i$)を入力画像($I$)から抽出する.
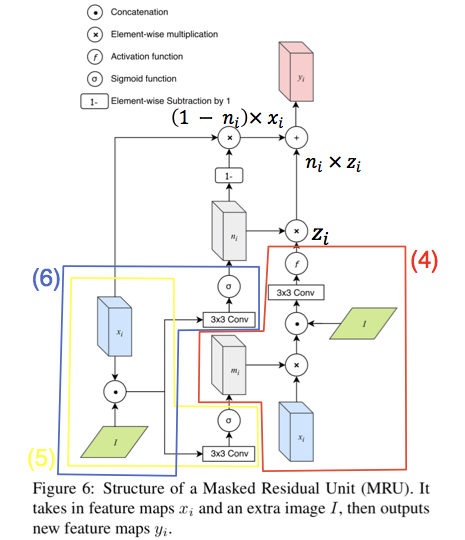
※ 論文中Figure 6を加工
z_i = f(Conv([m_i \odot x_i, I])) (4)
m_i = \sigma(Conv([x_i, I])) (5)
n_i = \sigma(Conv([x_i, I])) (6)
$m_i$は入力の特徴マップに対するマスク,$n_i$は入力の特徴マップと新たな特徴マップを統合するためのマスク.
最終的な出力は
y_i = (1 - n_i) \odot x_i + n_i \odot z_i (7)
論文中の式(7)は,$y_i = (1 - n_i) \odot z_i + n_i \odot x_i$だが,Figure 7的にはこうだと思う.
Network Structure
ネットワークの全体図(再掲).
generator部分では,スケールの異なるスケッチ画像をMRUに入力している.
エンコーダ部分とデコーダ部分を繋ぐSkip connectionが存在.
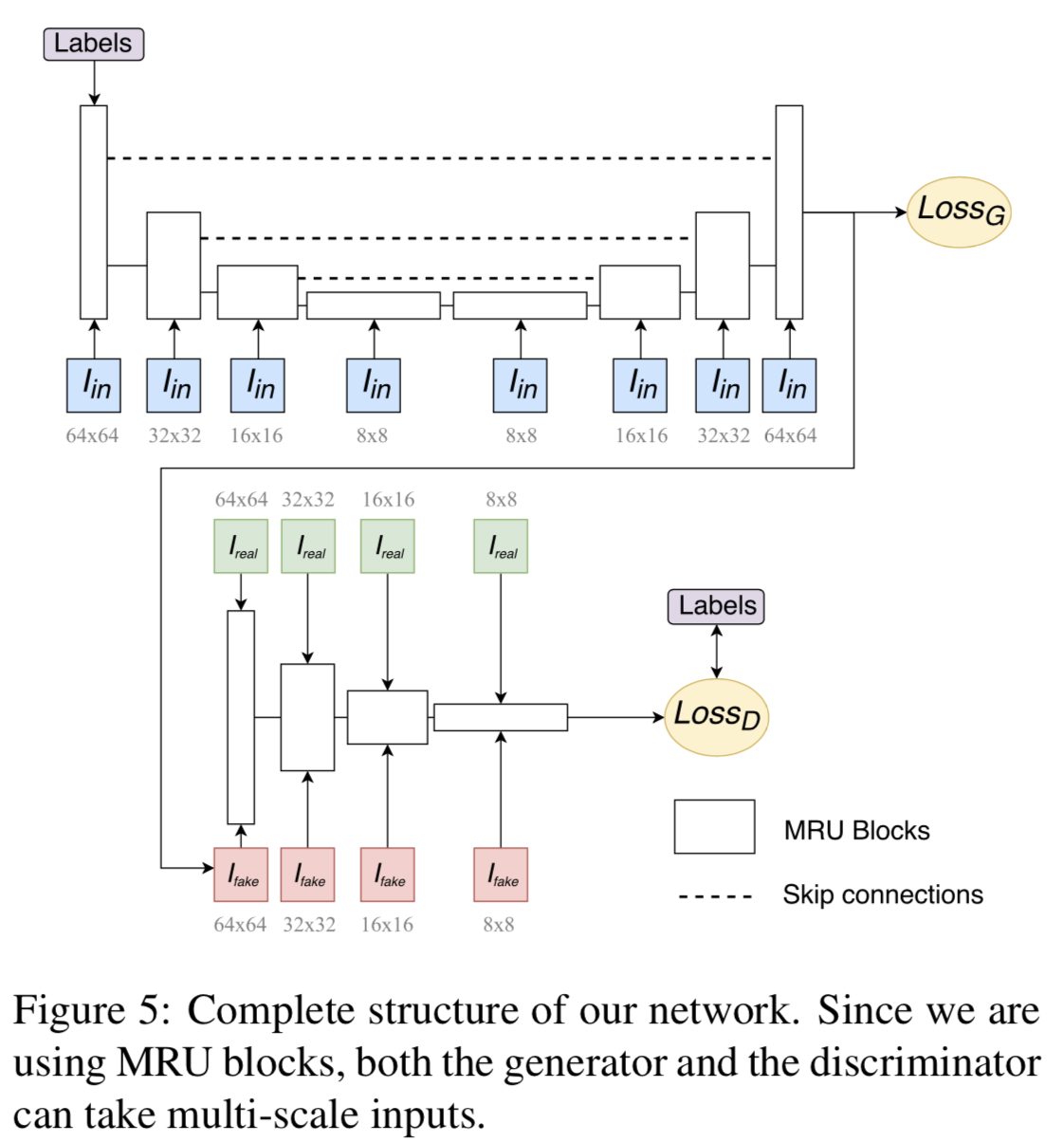
Objective Function
一般的なロス関数の他に,出力画像に多様性を持たせるためのロス関数を2つ追加.
- 生成画像と真値写真画像の,Inception-V4の出力を比較したもの
- 異なる2つのガウシアンノイズをのせて生成した画像を比較したもの

どうやって有効性を検証したか
- Dataset
- Sketchy
- Augmented Sketchy
- テストはSketchyデータセットのものを使用
- Inception Scoresで評価
- Baselines
- pix2pix on Sketchy
- pix2pix on Augmented Sketchy
- Label-Supervised pix2pix on Augmented Sketchy,ラベル情報も付与できるように拡張
Comparison to Baselines


以下のことが分かる.
- pix2pixはedge-to-imageな手法.スコアからsketch-to-imageが如何に困難か分かる
- pix2pixの結果から,データ拡張が有効であることが分かる
- ラベル情報を付与することでスコアは上がったが,ぼけやアーティファクトが見られる
- 提案手法のスコアが高く,最もリアルでカラフルな画像が生成される
Component Analysis
ロス関数を減らすと,画像の質が下がる(-GAN, -P, -DIV),色付けのミスが発生(-L-AC).

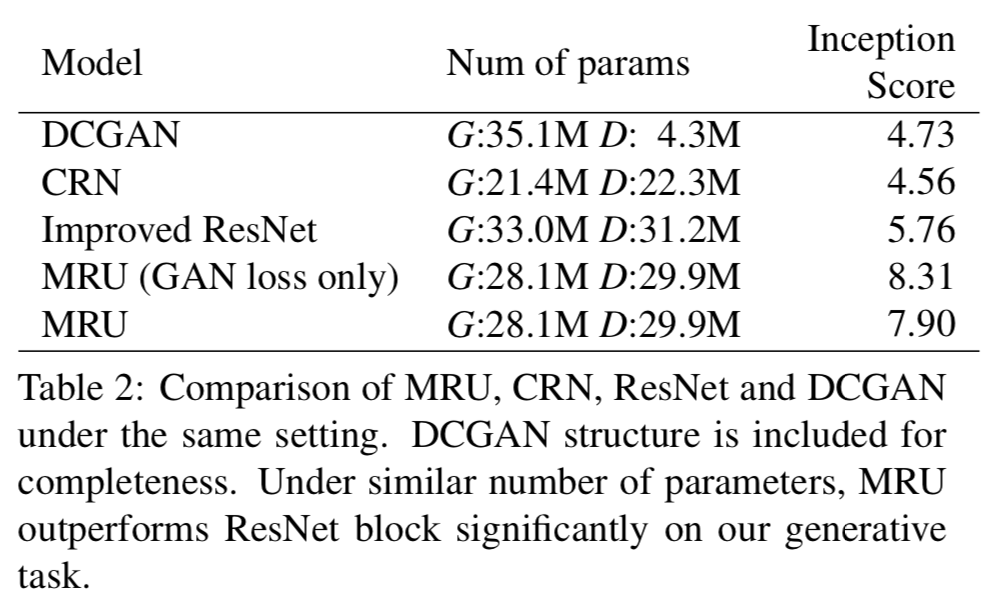
Comparison between MRU and other structures
MRUと他の構造(ResNet, Cascaded Refinement Network, DCGAN)を比較.
提案手法が最もスコアが高く,パラメータ数の近いResNetと比較しても良い結果.
提案手法はMRUによって,写真に写るメインの物体の質が高い.
スコア的にはGAN lossだけの提案手法が最も良い.

Human Evaluation of Realism and Faithfulness
- faithful test
- 人間に同じカテゴリに属する9枚のスケッチを見せる
- 生成画像がどのスケッチから作られたものかを当ててもらう
- このスコアが高い方が"faithful"
- Baselines : pix2pix, 1-nearest-neighbor retrieval
- realism test
- pix2pixとSketchyGANの出力と,入力のスケッチを見せる
- どちらの方が"realistic"か答えてもらう

faithfulスコアがpix2pixより低い理由は,pix2pixが入力画像のエッジを正確に出力していたから.
最後に提案手法のbest output.

議論はあるか
スケッチから写真を生成するGAN, SketchyGANを提案.
スケッチのためのデータ拡張手法を提案し,従来手法をInception Scoreで上回った.
- スケッチ中の物体の姿勢や位置は出力画像に反映できているが,リアルな画像を生成するのは難しい
- 人間の意図をスケッチから汲みとり,学習することは難しい
次に読むべき論文
GANを用いた手法