Zorah L ̈ahner, Daniel Cremers, Tony Tung
Facebook Reality Labs, USA, Technical University Munich, Germany
ECCV2018
arXiv, project page, video
どんなもの?
現実世界のデータから正確で現実的な衣服の変形(シワ)を生成する手法,Deep wrinklesを提案.
Deep wrinklesの目標は,観測可能な全ての幾何学的な詳細を復元すること.

先行研究との差分
- 3次元表面の幾何学的なrefinementに対してdeep neural networkを初めて適用
- 法線マップの生成にConditional GANを使用
- 異なる体型や姿勢にretarget可能
- 時間的な一貫性も考慮
技術や手法のキモ
紫色が入力,シアン色が学習モデル.
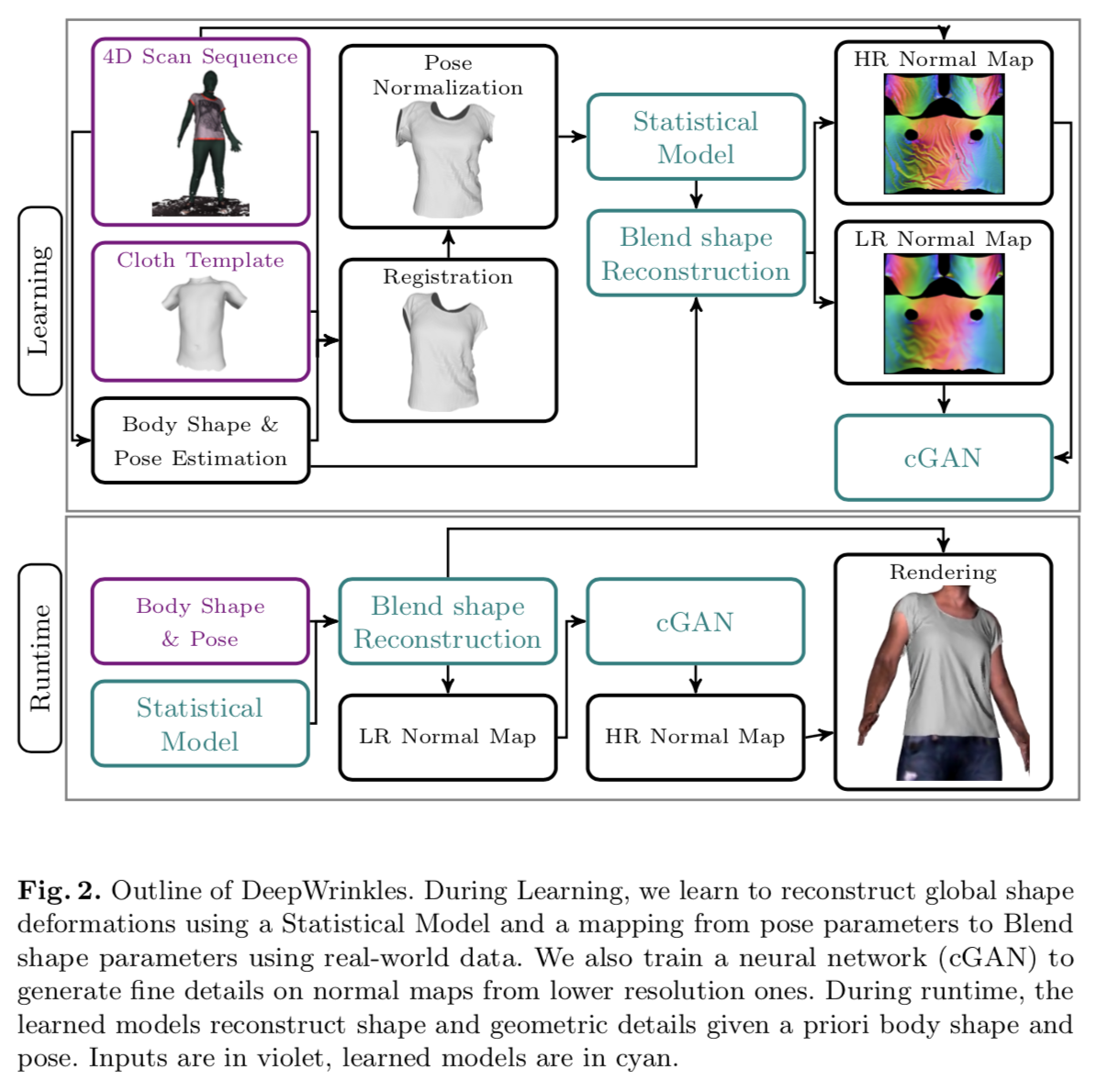
Data preparation
- それぞれのタイプの衣服について60fpsで4D スキャン
- 200kの頂点で構成される3Dメッシュが得られる
- 得られたデータは非剛体レジストレーション(non-rigid registrations).
- 非剛体の位置合わせ
Statistical model
統計的モデルは、PCAによる線形部分空間分解(SMPL)[31] を用いて計算

※ 画像は [31] から引用
Fine Wrinkle Generation
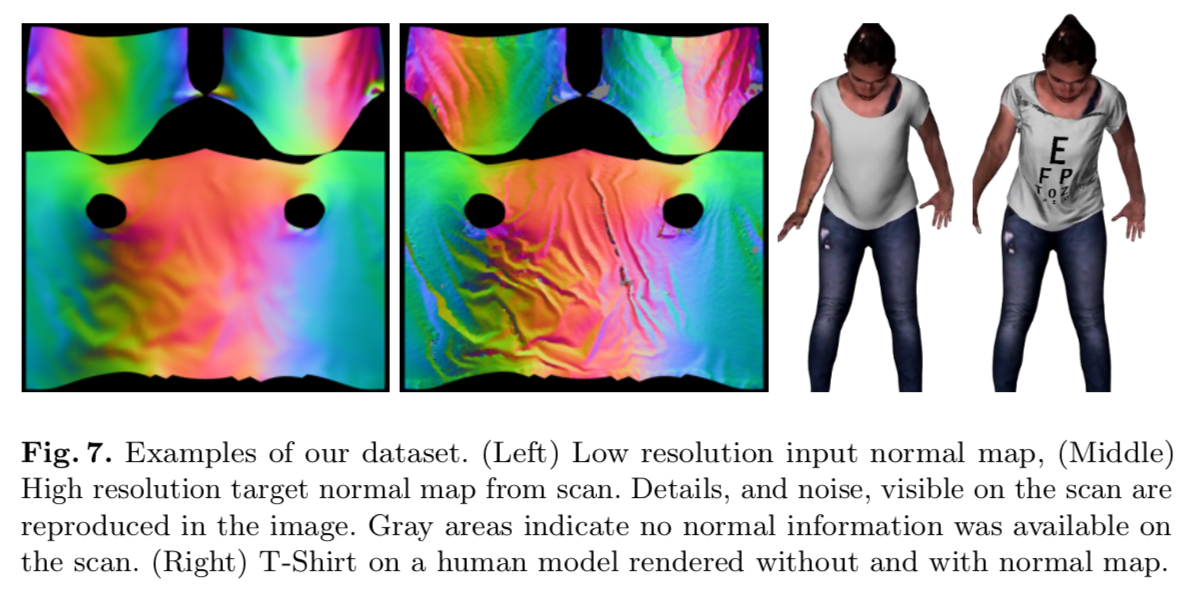
下の図のようにlow resolution (LR) 法線マップとConditional GANで得られたhigh resolution (HR) 法線マップを使用して衣服の詳細なシワを再現する.

low resolution (LR) 法線マップは blend shape reconstructionによって得られる.
high resolution (HR) 法線マップはスキャンによって得られる.
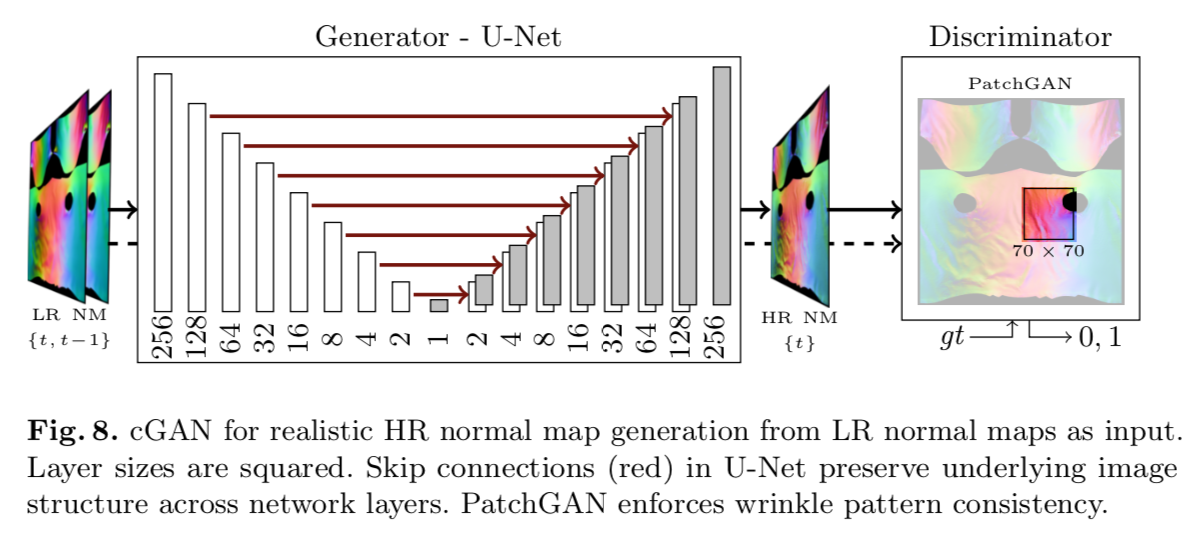
以下が提案手法のConditional GAN.
GeneratorはU-Net構造,Discriminatorは70x70のPatchGANで法線マップの一貫性を強制する.
low resolution (LR) 法線マップから本物らしいhigh resolution (HR) 法線マップの生成を目指す.
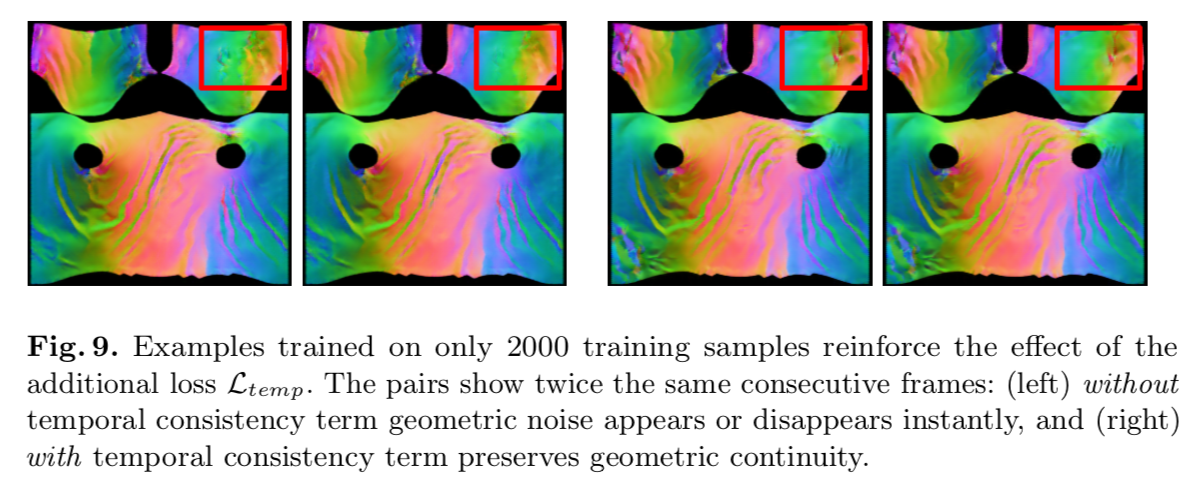
法線マップの時間的な一貫性を保つために,以下のロスを追加する.
$L_{data}$は真値に近いマップを生成するためのロス.
$L_{temp}$は1時刻前の真値画像に近いマップを生成するためのロス.
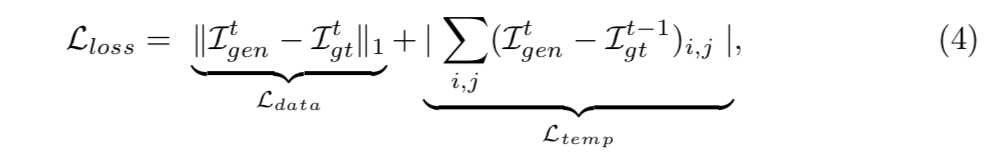
連続する2フレームの結果を見ると,このロスが無い場合はノイズが入り,一貫性が無くなってしまう.
(左がロス無しの連続する2フレーム,右がロス有りの連続する2フレーム)
どうやって有効性を検証したか
2種類のシャツ(男性用と女性用)について学習.
9213枚の連続した画像データセットを使用(The first 8000 for train, the next 1000 for test, the remaining 213 for validation.)
Comparison of approaches
以下は異なるアプローチとの比較結果.
- Physics-based simulation done by a 3D artist using MarvelousDesigner [32]
- A linear subspace reconstruction with 50 coefficients

Importance of reconstruction details in input
以下の表は時間的な追加した$L_{loss}$を変えた結果(左)と学習データを変えた結果(右).
(左)$L_1$距離で定義した方が良く,$L_{temp}$だけでなく$L_{data}$も必要であることが分かる.
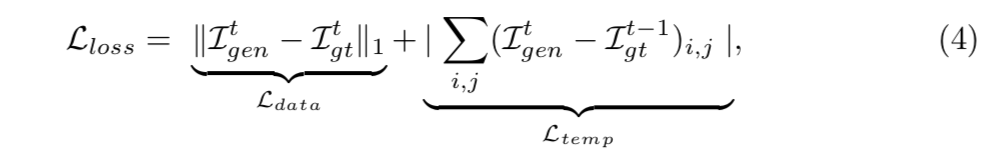
(右)registrationが最も良い.

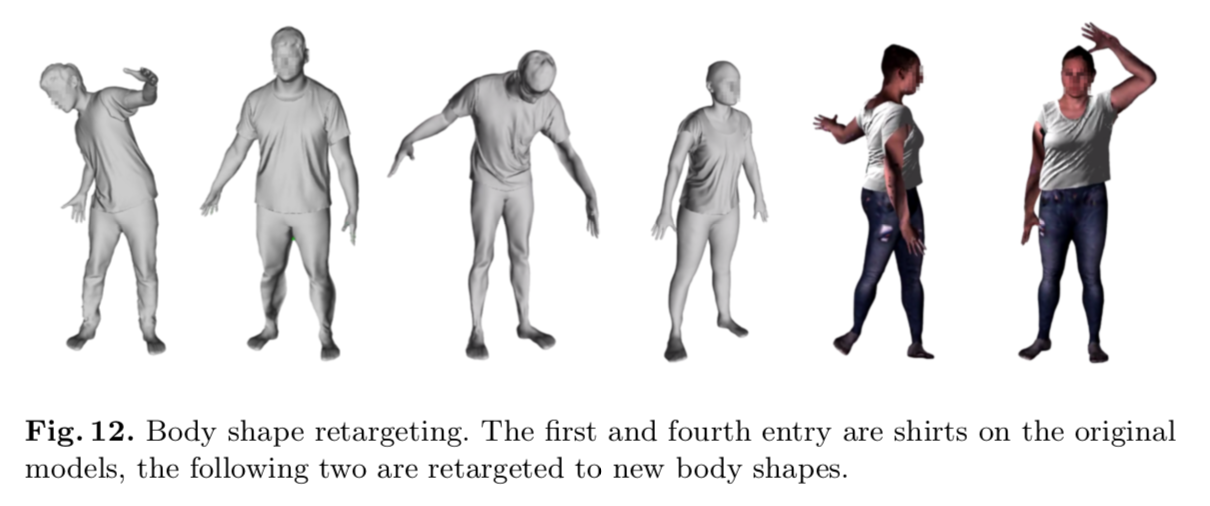
Retargeting
human templateを変えることで,異なる体型へのretargetが可能.
議論はあるか
-
衣服の動きを捉え,再構築するフレームワーク,DeepWrinklesを提案
-
Conditional GANでhigh resolution (HR) 法線マップを生成
-
時間的な一貫性を保つためのロスを提案
-
high resolution 法線マップは、脇の下領域などのカメラには見られない領域の情報が欠けている可能性がある
-
様々な種類の衣服,アクセサリー(コートやスカーフなど)へ応用したい
次に読む論文
pix2pixならぬvid2vid
Video-to-Video Synthesis