LIBIN LIU, DeepMotion Inc., USA
JESSICA HODGINS, Carnegie Mellon University, USA
ACM Transactions on Graphics (August 2018)
pdf, video, project page
前提知識と英語力の無さから理解が困難だった...
ここのまとめを参考にさせていただきました.
どんなもの?
バスケットボールというスポーツは動きが激しく,細かなボールのコントロールが要求され,そのシミュレーションは難しい.
この論文では,モーションキャプチャのデータからドリブルのスキルを強化学習を用いて学習する.
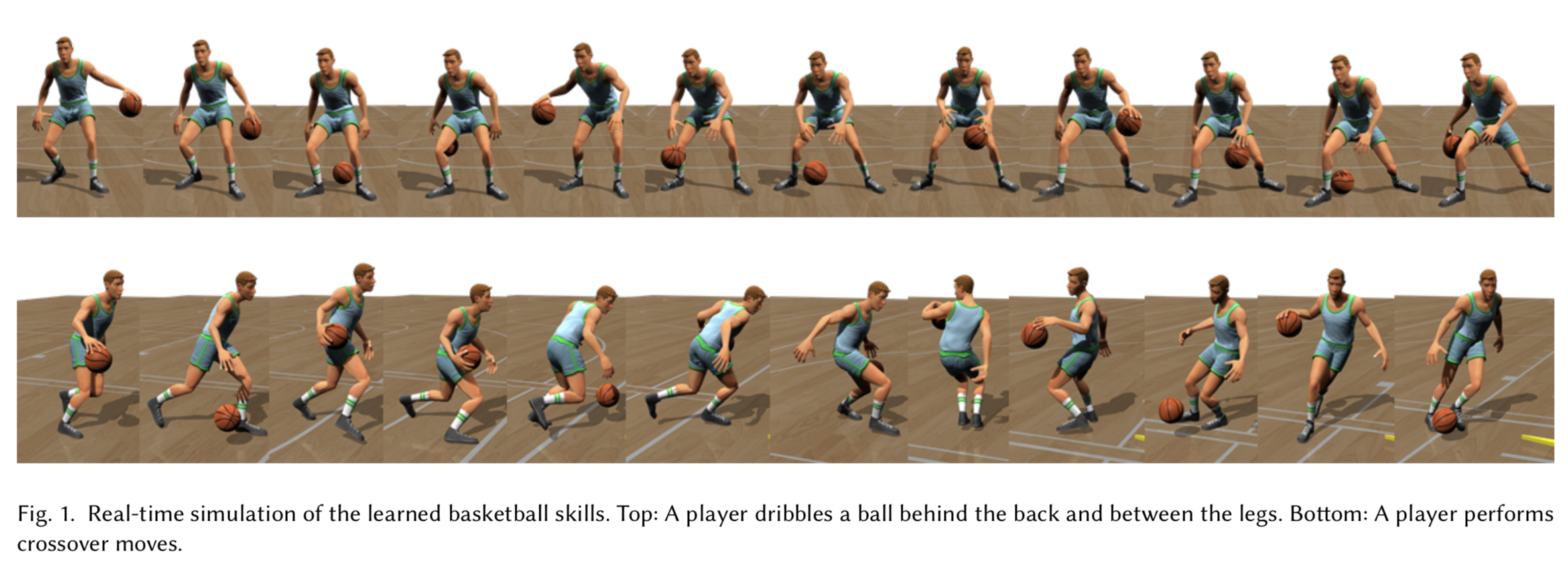
先行研究との差分
- リアルタイムなバスケットボールの制御を実現
- 入力のモーションキャプチャにボールの動きは不要
- 深層強化学習を適用することで非線形な腕の動きを学習可能に
技術や手法のキモ
以下の図は提案手法の概要図.
移動の制御"Locomotion Control"と腕の制御"Arm Control"は別々に最適化を行う.
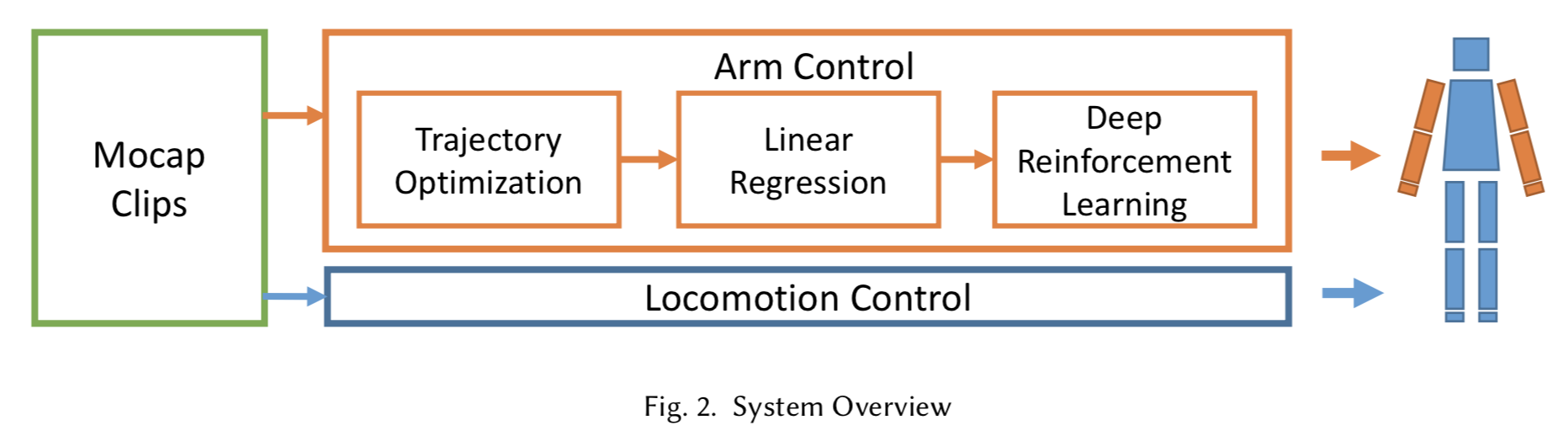
LEARNING OF LOCOMOTION CONTROL
この論文に詳細は書かれていない.
[Liu et al. 2016]で学習する.
ここではボールの位置情報は使用せず,モーションキャプチャのデータだけを使用して学習する.
LEARNING OF ARM CONTROL
Trajectory Optimizationで線形回帰のための教師データの作成,
Learning of the Linear Control Policyで線形回帰で方策関数を獲得,
Deep Reinforcement Learningで深層強化学習で非線形な方策関数を獲得する.
Trajectory Optimization
後の線形回帰のためのデータ(腕データ)を作成する.
肩,肘,手首のモーションキャプチャデータからのオフセット,手(指?)の開き具合(腕データ)を求める.
これらは非常にパラメータが多いのでsliding window scheme [Al Borno et al. 2013; Liu et al. 2006]を使って最適化を進める.
以下がsliding window schemeを図示したもの(よく分からない...).
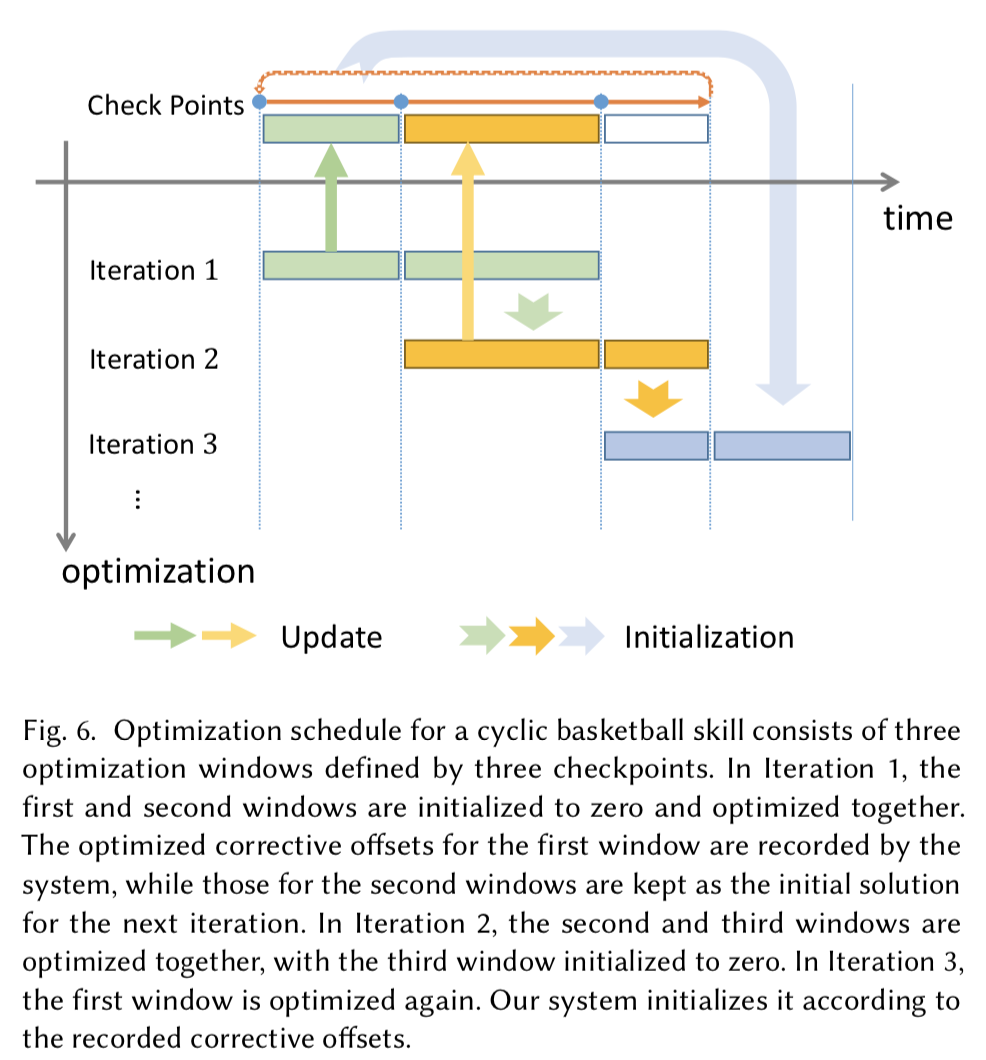
パラメータの最適化には,Covariance Matrix Adaptation Evolution Strategy(CMA-ES, 共分散行列適応進化戦略)を使用する.
Learning of the Linear Control Policy
方策関数を線形回帰で求める.
入力状態はボール位置,ボール速度,体の各部位の位置,速度,ボールと手の距離,体の質量中心の位置,速度,プレイヤーの角運動量.
出力は肩,肘,手首,手の開き具合などの腕データ.
教師データはTrajectory Optimizationで得られた腕データ.
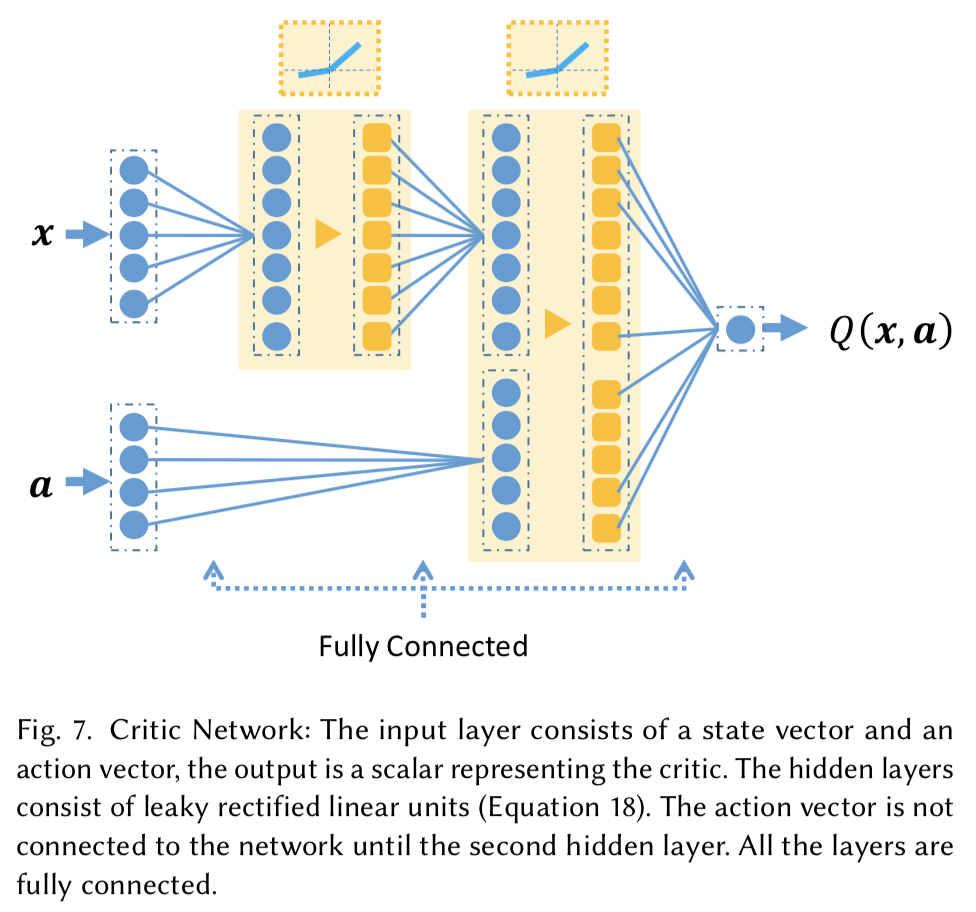
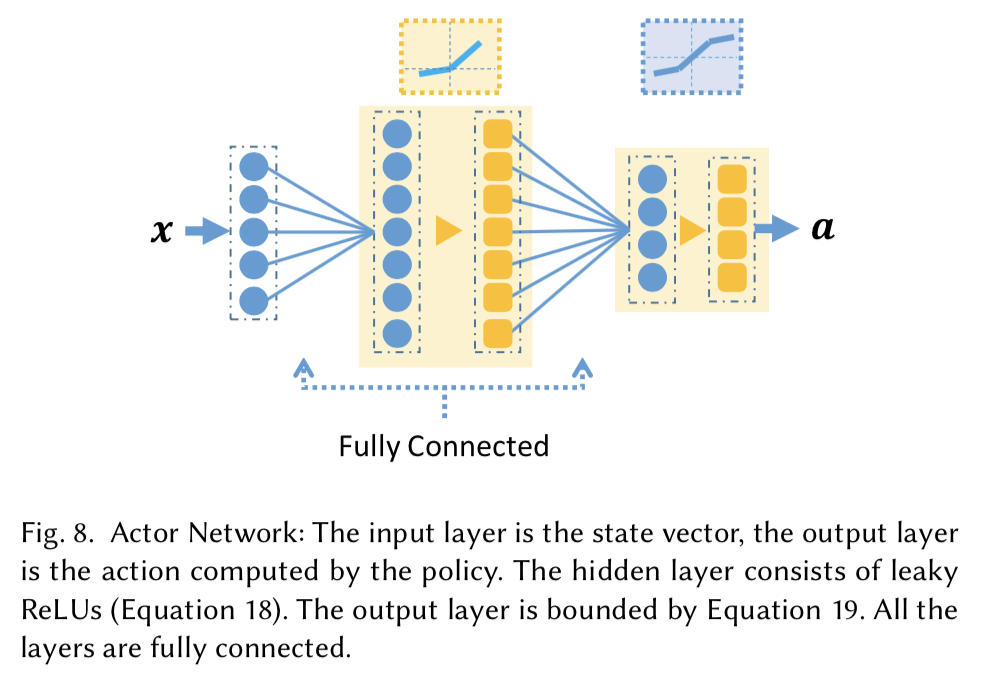
Deep Reinforcement Learning
深層強化学習で非線形な方策関数を学習する.
Deep Deterministic Policy Gradient (DDPG) algorithm (Actor-CriticのDeep版?)で学習する.
方策関数は,線形回帰で求めた方策関数で初期化することが重要だったよう.
どうやって有効性を検証したか
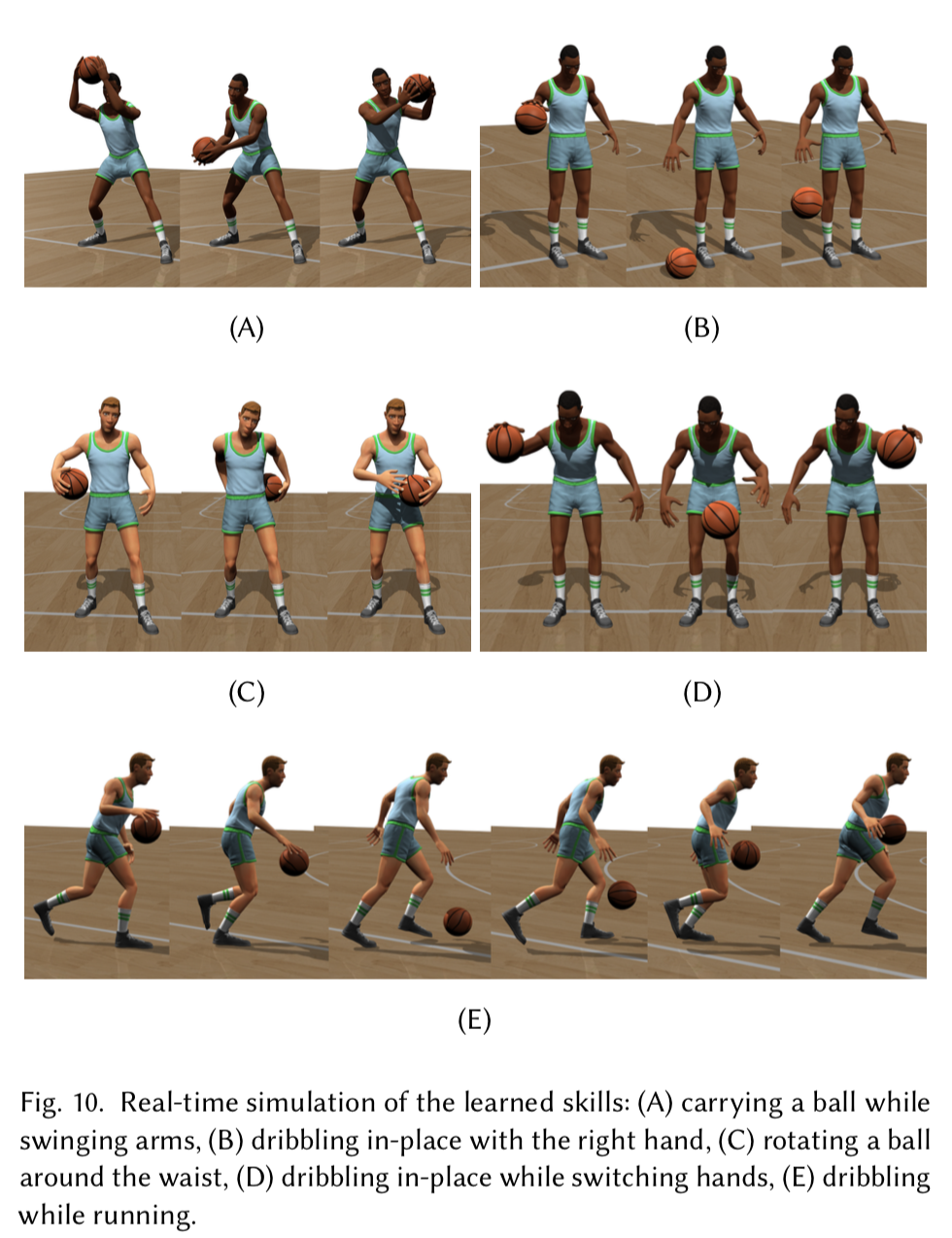
今回は5つのスキルを学習.
(A) carrying the ball while swinging arms
(B) dribbling in-place with the right hand
(C) rotating the ball around the waist
(D) dribbling in-place while switching hands
(E) dribbling while running
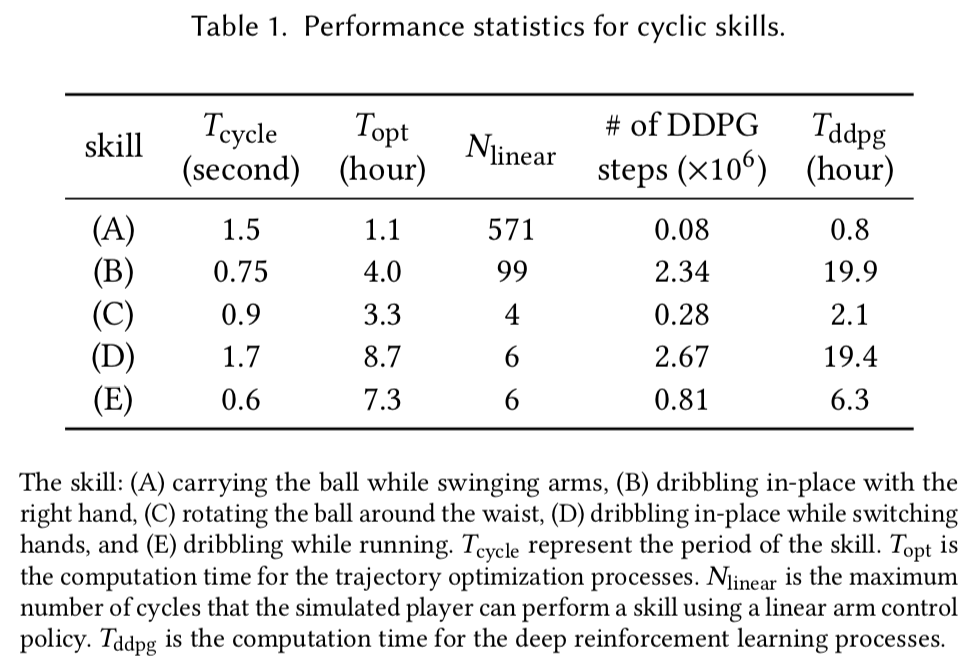
以下はそれぞれのスキルに関するデータ.
$T_{cycle}$はスキルの(発動)時間 (the period of the skill)
$T_{opt}$はそのスキルのtrajectory optimizationに要した時間
$N_{linear}$は線形な方策を使用して連続でスキルを行えた最大回数
$T_{ddpg}$は深層強化学習に要した時間
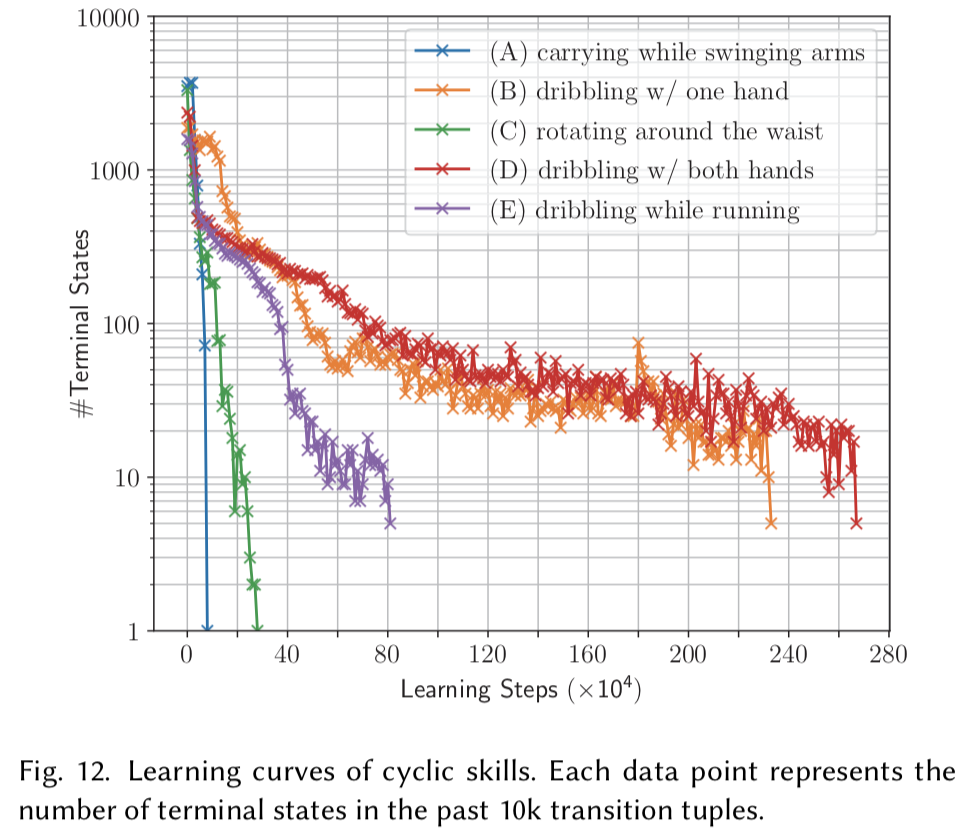
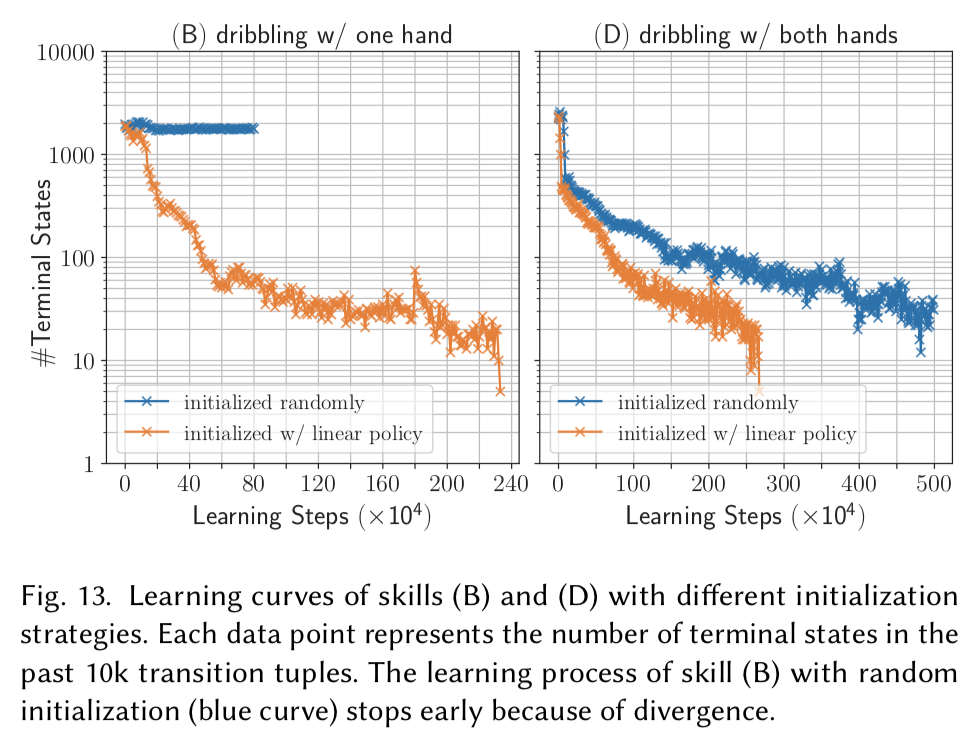
以下のグラフは10000回の試行の内,何回終点状態になったか(失敗したか).
スキルごとの難易度や,どれだけ方策がロバストかを表す.
学習を進めるにつれてその回数は減っている.
以下のグラフは深層強化学習の際に方策を「ランダムに初期化」したか,「線形回帰で獲得した方策で初期化」したかで比較したもの.
「線形回帰で獲得した方策で初期化」した方が安定で早く学習ができていることが分かる.
以下はスキルの成功確率を表にしたもの.
非常に成功確率が高い.

議論はあるか
- モーションキャプチャのデータから,効率良くバスケットボールの制御を学習する手法を提案
- Trajectory Optimization
- Linear Control Policy
- Deep Reinforcement Learning
- Linear Control Policyで深層強化学習の方策を初期化することで学習を効率よく進められた
- スキル間の遷移も学習
- 最終的にはスキルを10000回試行しても10回前後の失敗で抑えられるように
次に読むべき論文
次回もCG寄りの論文を読んでみる
服のシワを生成するGAN
DeepWrinkles: Accurate and Realistic Clothing Modeling