Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen
NVIDIA and Aalto University
Published as a conference paper at ICLR 2018
arXiv, pdf, GitHub, YouTube
前回読んだ論文の元となった論文.
どんなもの?
Progressive growing of GANsを用いることで,学習をより早く,また安定させることができ,高解像度の画像の生成も可能にした.
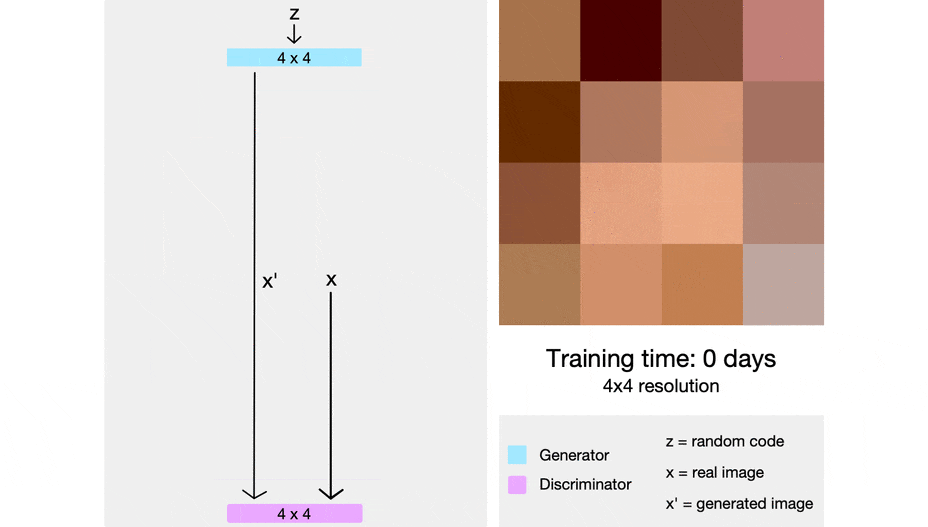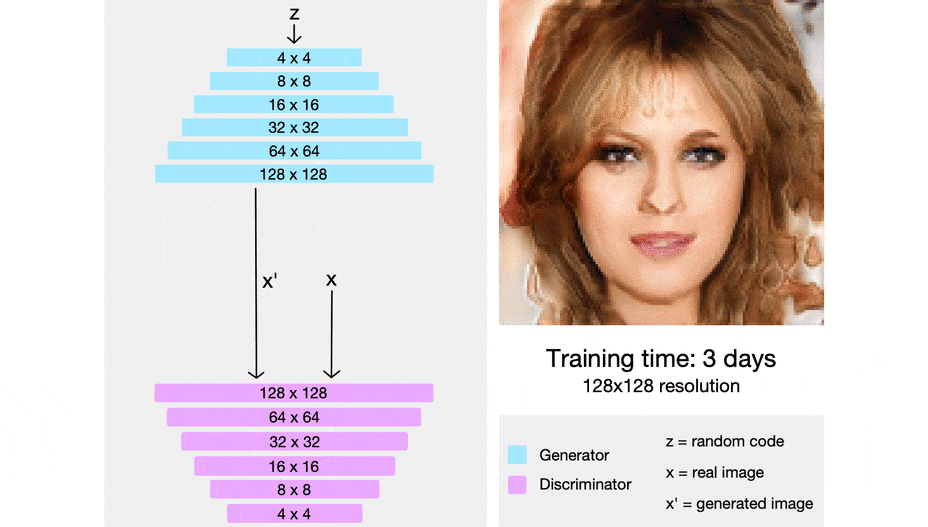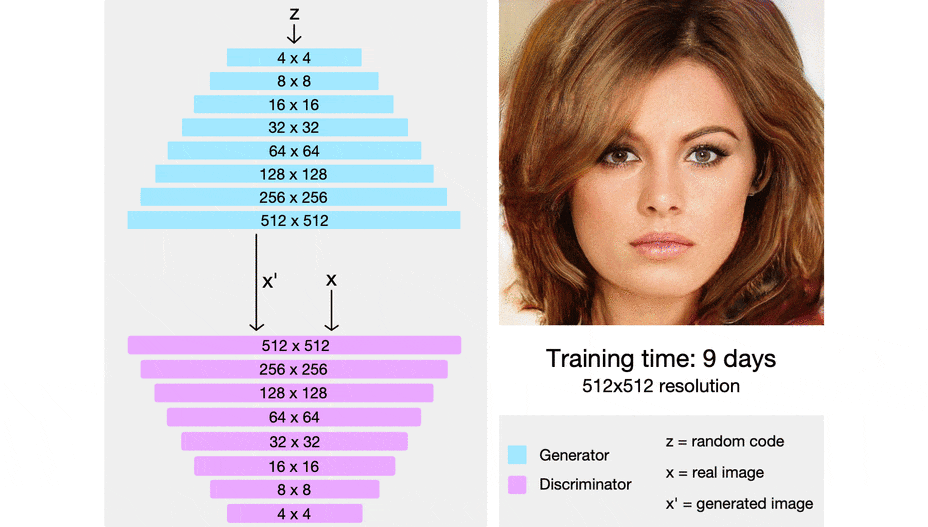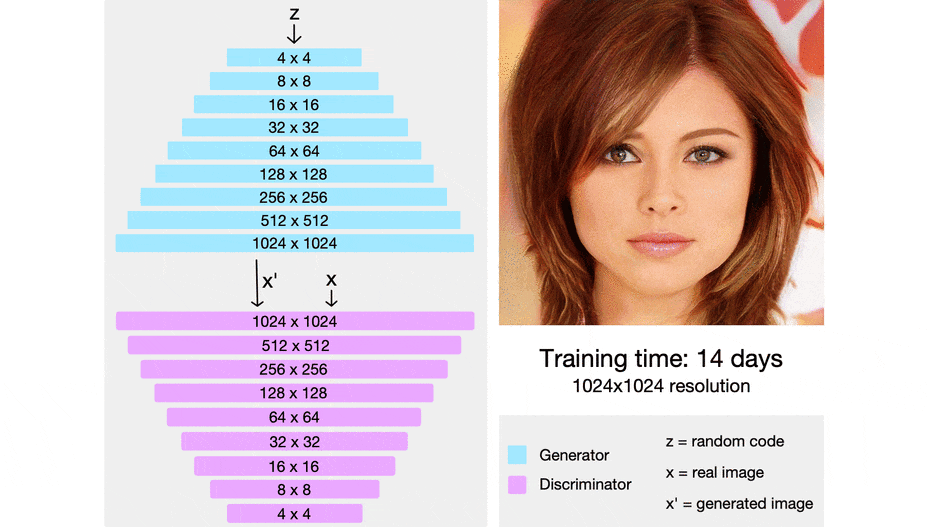
先行研究との差分
- Progressive growing of GANs
- Minibatch standard deviationを用いたvariation
- Equalized learning rate
- Pixelwise feature vector normalization
- 新たな評価指標sliced Wasserstein distance SWD
を提案
技術や手法のキモ
Progressive growing of GANs
以下の画像はProgressive growing of GANsの概要図.
低解像度の画像から学習し,学習が進むにつれて徐々に層を積み重ねる.

新たに層を積み重ねるときには学習済みの層へのsudden shocksを回避するために,下図のように$\alpha$を0~1へと線形に増やす.

Increase variation using minibatch standard deviation
出力画像に多様性を持たせる方法の一つにminibatch discriminationがある.
これを簡略化した以下のようなテクニックをdiscriminatorの最終層で使用する.
- ミニバッチの画像間の標準偏差を計算(B x H x W x C → H x W x C)
- 空間的な位置ごとに平均をとる(H x W x 1)
- 平均をとったものを各画像にconcatenate
Equalized learning rate
重みの更新を工夫する.
重みの初期化は$\it{N} (0, 1)$で初期化するが,重みの更新は
\hat{\omega_i} = \omega_i / c
とする.
$c$はHeらの初期化で得られるper-layer normalization constant.
これによって通常,RMSProp, Adamなどはダイナミックレンジが大きいパラメータは学習により多くの時間がかかるが,この正則化によってスケールを考慮したパラメータの更新ができ,学習のスピードを上げることができる.
Pixelwise feature vector normalization
学習でそれぞれのネットワークが,制御不可能な値をとるようになることを防ぐために,generatorの各畳み込み層の後にチャンネル方向の正規化を加える.
b _ { x , y } = \frac{a _ { x , y }}{\sqrt { \frac { 1 } { N } \sum _ { j = 0 } ^ { N - 1 } \left( a _ { x , y } ^ { j } \right) ^ { 2 } + \epsilon }}
$\epsilon = 10^{-8}$,$N$は特徴マップの数で$a_{x, y}, b_{x, y}$はそれぞれオリジナルと正規化後の特徴ベクトルの要素$(x, y)$の値.
sliced Wasserstein distance SWD
既存の評価指標であるMS-SSIMは大きなmode collapsesには敏感だが,色やテクスチャの多様性のような小さな効果はスコアに影響しにくく,生成した画像とtraining setの類似度を評価してもいない.
そのため新たにLaplacian pyramidによって得られた局所特徴を用いる評価指標,sliced Wasserstein distance SWDを提案.
しているのですが,理解が及ばない...
何か生成画像とtraining set中の画像を比較し,各層のごとのsliced Wasserstein distanceを求めている.
どうやって有効性を検証したか
下の表はCELEBA,LSUN BEDROOMでの評価.
Baseline (WGAN-GP) の手法に,提案した要素を順に追加している.
要素を追加するほどより良いスコアを得ている.

また,各段階での生成画像を比較すると (h) が最も良いがMS-SSIMがそれを反映していないことから,提案した評価指標の方が好ましい.

下の図中 (a), (b) はWGAN-GPと提案手法の訓練時間ごとのSWD.
提案手法の方がSWDが下がっており,収束するまでの時間も短い.
また提案手法では低解像度の層を学習したのちに上層を積み重ねているため,学習が安定している.
(c)は経過時間に対する学習に使用した画像枚数のグラフ.
提案手法では序盤は層が浅く,処理が軽いため多くの画像を使用できている.
提案手法では学習が収束するまでに合計で640万枚の画像を96時間掛けて処理したが,従来手法が同じ枚数処理するには520時間掛かってしまう(提案手法が5.4倍高速化できている).

以下の画像はCELEBA-HQを用いた時の生成結果.
画像サイズは1024x1024で,学習には8 Tesla V100 GPUsで4日掛かった.

以下はこの時のネットワーク.

以下はその他のデータセットを使用した場合の結果.


議論はあるか
- 段階的に層を積み重ねながら学習を進めるProgressive growingを提案
- 生成画像に多様性を持たせ,学習を安定に,高速に行うための工夫を提案
- 画像中のより微細な構造の部分については改善の余地がある
次に読む論文
考え中...