Ziyu Wang, Tom Schaul, Matteo Hessel, Hado van Hasselt, Marc Lanctot, Nando de Freitas
ICML2016 Best paper
arXiv, pdf
どんなもの?
Dueling Network Architectureを提案.
Double DQN(DDQN)とDueling Network Architectureを組み合わせることで,Atari gamesのスコアが向上することを確認.
また,Prioritized Experience Replayも組み合わせることで,さらにスコアが向上することを確認
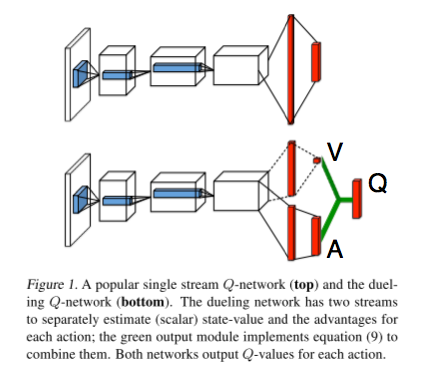
先行研究との差分
advantage functionをQ関数に加えることで,ネットワークの構造に変更を加えた.
技術や手法のキモ
ゲーム中にはどんな行動を選択しても,スコアに影響しない場面が多く存在する.
そのため行動の重要度を表すadvantage function $A^{\pi}(s, a)$を導入した.
Q function $Q^{\pi}(s, a)$からvalue function $V^{\pi}(s)$を引くことで相対的な行動の重要度が得られるみたい.
The advantage function subtracts the value of the state from the Q function to obtain a relative measure of the importance of each action.
A^{\pi}(s, a) = Q^{\pi}(s, a) - V^{\pi}(s)
以下はvalue functionとadvantage functionのsaliency maps.
上のフレームにおいて,value functionは新たな敵の車が現れる地平線の部分やスコアの部分に注目しているが,advantage functionは特にどこにも注意を配っていない.これは,目の前に敵の車がいないときに行動の選択がスコアに影響を与えないことを知っているから.
一方で下のフレームにおいて,advantage functionは目の前の敵の車に注意を配っている.これは敵の車が行動の選択に大きく影響を与えるため.

前半の畳み込み層のパラメータを$\theta$,後半の全結合層のパラメータをそれぞれ$\alpha, \beta$とすると以下のように書ける.
Q(s, a; \theta, \alpha, \beta) = V(s; \theta, \beta) + A(s, a; \theta, \alpha)
しかしながら,これをそのまま実装してしまうとノイズの影響で誤ったQを学習してしまうみたい.
given Q we cannot recover V and A uniquely. To see this, add a constant to V(s; θ, β) and subtract the same constant from A(s, a; θ, α). This constant cancels out resulting in the same Q value. This lack of identifiability is mirrored by poor practical performance when this equation is used directly.
これを解決するために以下のように書き換える.分母は行動数.
Q(s, a; \theta, \alpha, \beta) = V(s; \theta, \beta) + \Bigl(A(s, a; \theta, \alpha) - \frac{1}{|A|}\sum_{a^{\prime}}A(s, a^{\prime}; \theta, \alpha)\Bigr)
どうやって有効性を検証したか
57種類のAtari gamesに対してテストを行い,そのスコアを比較.
Double DQNにDueling Network Architectureを組み合わせたものと従来Double DQNを比較.
Duel Clip : gradient clippingで再学習したDDQN+Dueling architecture
Single Clip : gradient clippingで再学習したDDQN
Single : オリジナルのDDQNモデル[van Hasselt+ 2015]
Nature DQN : DQN[Mnih+ 2015]
Prior. X : XにPrioritized Experience Replayを付け加えたもの
Human Starts : 30 no-ops metricsだとゲーム特有の地点からのスタートらしく,これだとただ行動のシーケンスを覚えているだけかもしれない.これを解消するために,人間(エキスパート)のプレイした軌跡からサンプルした点からゲームをスタートして,評価する.
Figure 4はオリジナルのDDQNからの改善をグラフにしたもの.右に伸びるグラフがDuel Clipの改善を表している.
Table 1は全ての結果をまとめたもの.人間(エキスパート)を100%としている.30
30 no-opsにおいて,Duel Clip, Prior. Duel Clipがより良い結果を出していることが分かる.Duel Clipは,75.4%のゲームでSingle Clipを上回り,80.7%のゲームでSingleを上回っているらしい.
Human Startsにおいても同様.
Prioritized Experience Replayと組み合わせることで,より良い結果になっていることが分かる.
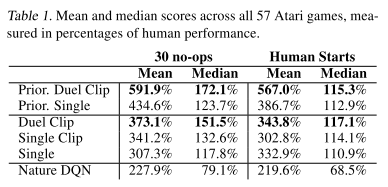
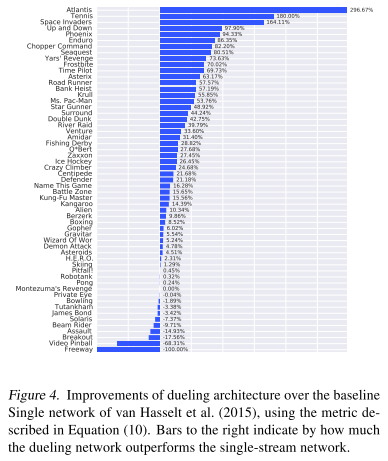
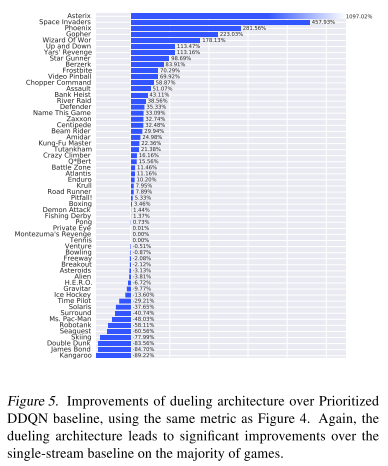
Figure 5はオリジナルのDDQNからの改善をグラフにしたもの(Prioritized Experience Replay有り).右に伸びるグラフがDuel Clipの改善を表している.
議論はあるか
Dueling architectureによってstate-value functionを効率よく学習することができる.これはQが更新されるたびにVも更新されるから?
また,ある状態におけるQ valueの差が小さくなる(例えば,Q valueの差が0.04,一方でstate valueの差は15).これは更新時のノイズの小ささに繋がっており,そのおかげでよりグリーディな方策の獲得に繋がっている(よく分かっていない...).