GeoHash、いいですよね。
地図で検索したいけど座標が緯度経度の二変数で表されるせいで範囲検索難しいぜ!を、一つの文字列として表す事で、範囲検索できるぜ!に変えてくれるアレです。
今回はそんなgeoHashの基礎原理とちょっと面白い応用について書いていきまっす!!
geoHashってなんだぜ? な方は [特徴] から
geoHash、あーアレか。 な方は [原理]から
はいはい二進数二進数。 な方は [喜び]を読んでいただけたらなと思います。
特徴
まず実例をみてみます。
| xn76utyn |
|---|
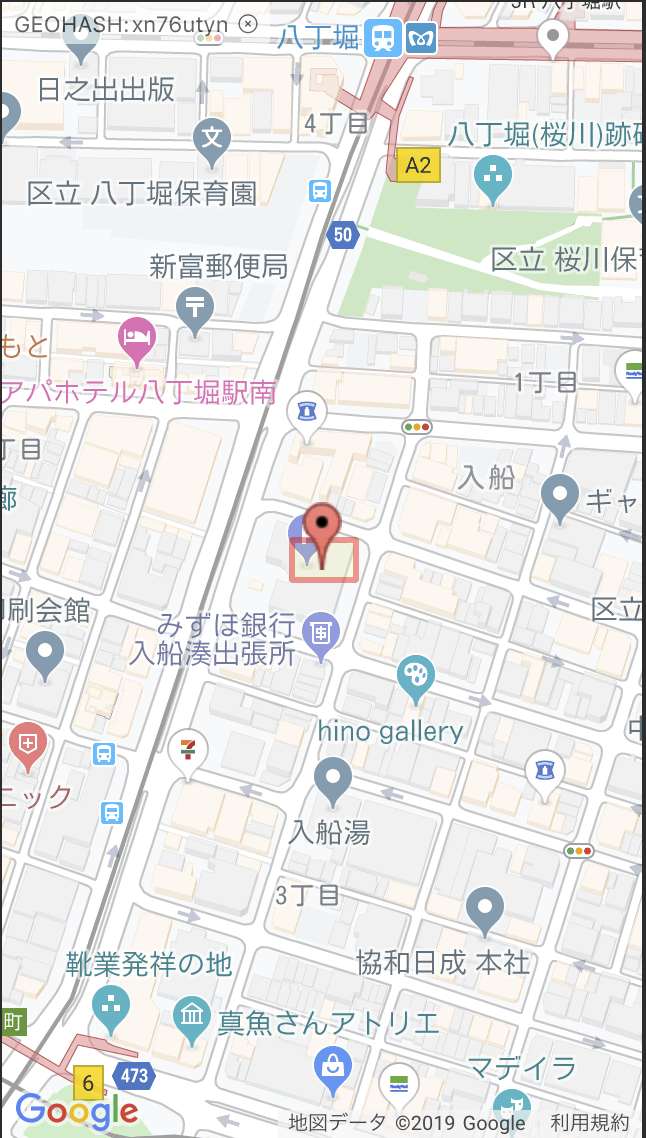 |
こんな感じで、 数字とアルファベットの組み合わせ(xn76utyn)が、ある一定の範囲を示します 。
文字列であらわすことで、DBにて文字列検索をするだけで範囲検索が可能になります。
英数字の桁数が範囲の細かさを表しており、末尾の桁を一つなくすと32倍になります。
実際に、末尾の文字を1、2こ消したものは下のようになります。
| xn76uty | xn76ut |
|---|---|
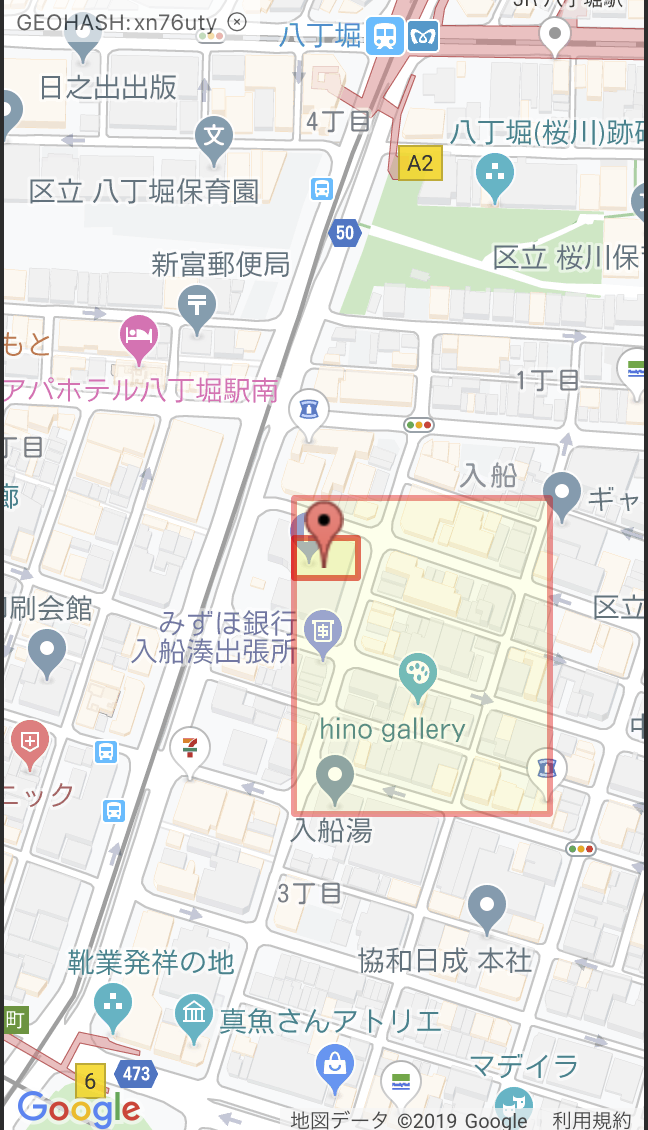 |
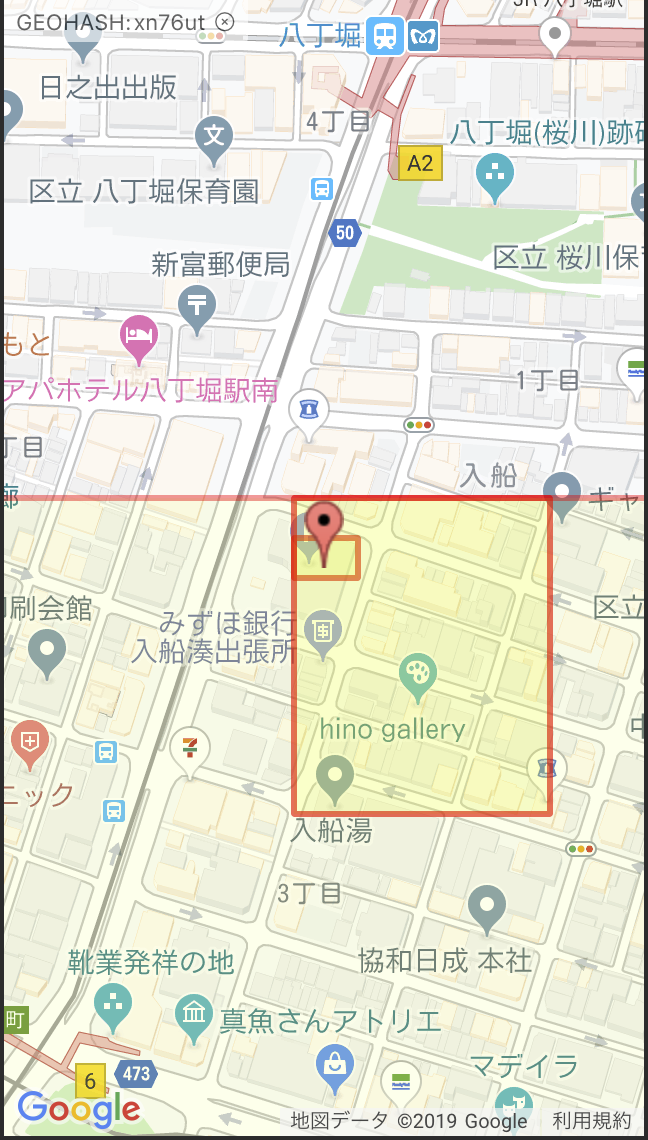 |
隣接したものは似た値になることが多いですが、全然異なることも多々あります。
xn76utynの右隣はxn76utypだけど、例えば兵庫県のある地域においては以下のように全然違うgeoHashが隣接しています。
| 兵庫県のどこか{ lat:34.82072648783, lng:134.99983199531 } |
|---|
 |
英数字で表す,一桁けすと32倍の範囲になる,近い場所は似た値になる
この三つがgeoHashの主な特徴です。
なぜこのような特徴になるのか、geoHashの原理を知り、考えていきたいと思います。
原理
一言で言うと、世界地図を緯度経度で2分割していき、北(東)を1,南(西)0を当てた二進数を32進数化したものです。
実際に一桁のgeoHashxを得るまでの流れをみていきます

世界地図を経度と緯度を順に分割していって、真ん中より値が大きいか小さいかで1 or 0 を当てていきます。
下の画像みたいな流れを行います。

得られた11101を二進数として、10進数に直してから、下の表を元に文字に変換します。
(変換の際に少し違う表を利用しているサイトもあります。以下の表はwikiったものです。base32です。)
| こんな | 感じ | に | 変換 |
|---|---|---|---|
| 0=>0 | 8=>8 | 16=>h | 24=>s |
| 1=>1 | 9=>9 | 17=>j | 25=>t |
| 2=>2 | 10=>b | 18=>k | 26=>u |
| 3=>3 | 11=>c | 19=>m | 27=>v |
| 4=>4 | 12=>d | 20=>n | 28=>w |
| 5=>5 | 13=>e | 21=>p | 29=>x |
| 6=>6 | 14=>f | 22=>q | 30=>y |
| 7=>7 | 15=>g | 23=>r | 31=>z |
11101(2) => 29 => x と得ることができました。
このように、アルファベット(英数字)一文字は2分割を五回行なった結果であるので、
geoHashの一文字増えるごとに2^5=32分割されるという特徴が自然と導かれます。
隣接した値が近くなる理由も、分割によって出現した二つの領域は末尾の0,1だけが異なることで説明され、
隣接した値が全然違うことになる理由も、分割していくはじめの方の段階で1,0が分かれてしまったら、得られる32進数も大きく変わるはずということで説明できます。
以上がgeoHashの原理です。
原理を知ったことで次から書く、喜びを得ることができます!
喜び
便宜上、geoHashの元となった二進数をgeoBinaryと呼ぶことにします。(かっこいい名前あったら教えてください)
精度
geoHashは一桁追加するだけで1/32の面積に絞りこんじゃってました。
日本全体で検索して、少し絞って東日本を検索しようとしたら、一気に東京・埼玉まで絞りこんじゃったみたいな感じです。嫌ですね。
でもgeoBinaryなら1/2の絞り込みだから、東日本の検索ができます。
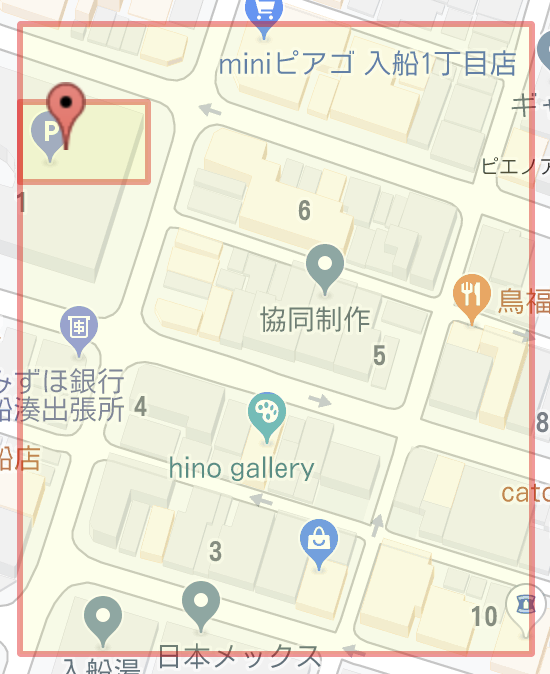
ヘイシャ周りをgeoBinaryとgeoHashで表し、比較してみました。
geoHash: `xn76utyn`と1文字消去
geoBinary: `1110110100001110011011010110011111010100`から1~5文字消去
| geoHash | geoBinary |
|---|---|
 |
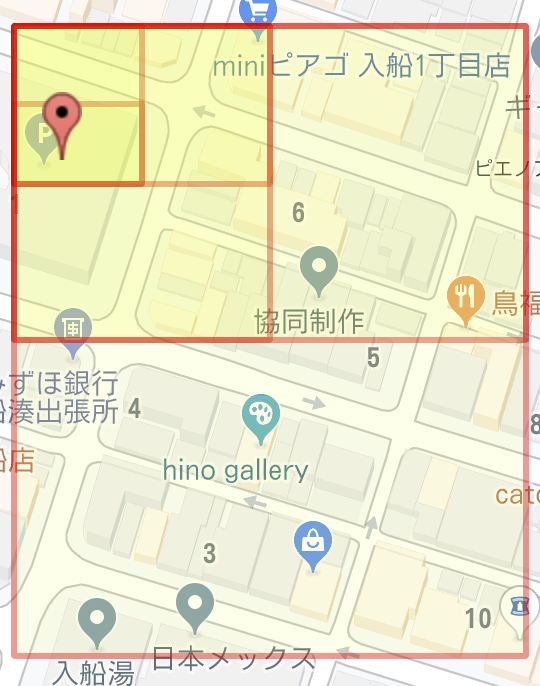 |
大分精度が向上していることが明らかですね。
隣接
隣接した領域を調べることも。geoBinaryだったら簡単にできます。
geoBinaryは経度緯度を交互に分割する、即ち経度は奇数桁、緯度は偶数桁に対応することになります。
あるgeoBainary001011があったとして、経度011、緯度001に分けられる。
右(東)側に行けば行くほど経度に関するbit列は大きく、上(北)に行けば行くほど緯度に関するbit列は大きくなるはず。
帰納的に考えると、経度011の一つ右は1を足して100、一つ左は1を引いて010
つまり、下のような隣接した範囲が簡単に計算できます。

これによって、ある領域の近傍に存在する領域を容易に求めることができます。
検索
・伸縮
検索方法も面白いことができます。
DBへの保存の際に、各桁をそれぞれのカラムに保存する設計にすると、次のコードのように、ある桁を飛ばした検索ができるようになります。
geoBinary: {
digit_1: 0,
digit_2: 1,
digit_3: 0,
digit_4: 0,
......
}
where('digit_1 = 0').where('digit_2 = 1').where('digit_4 = 0')
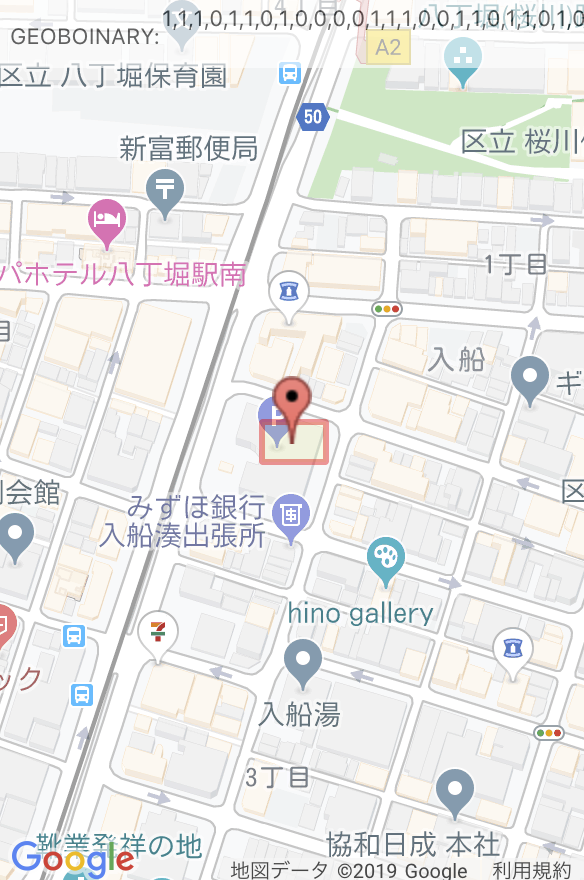
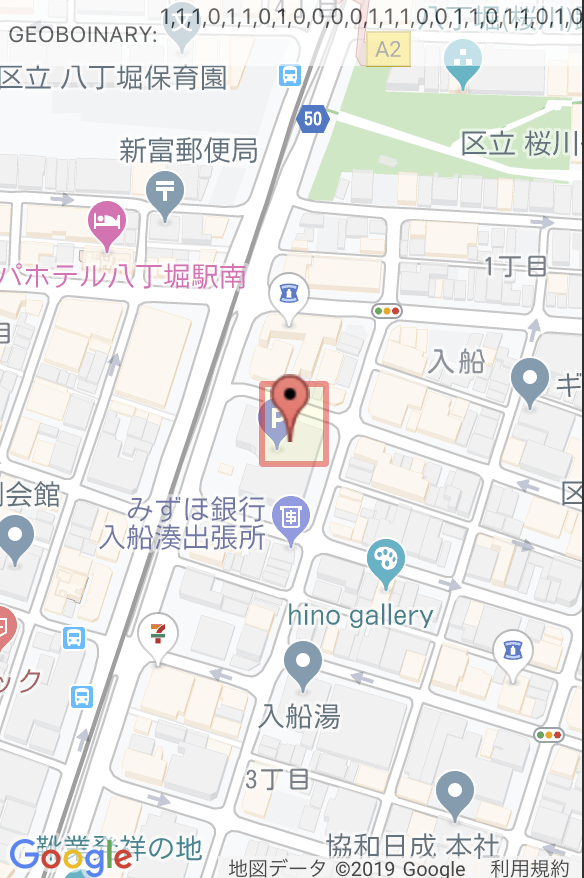
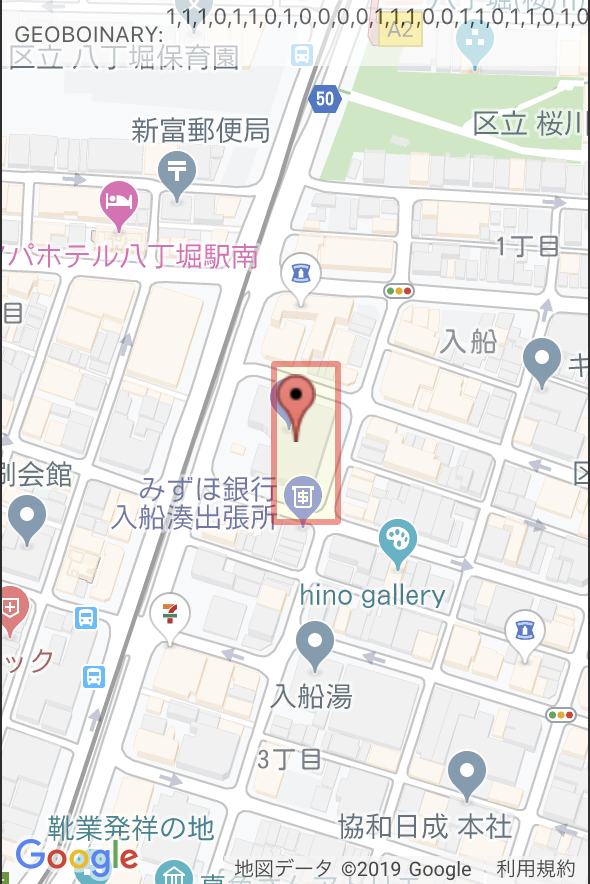
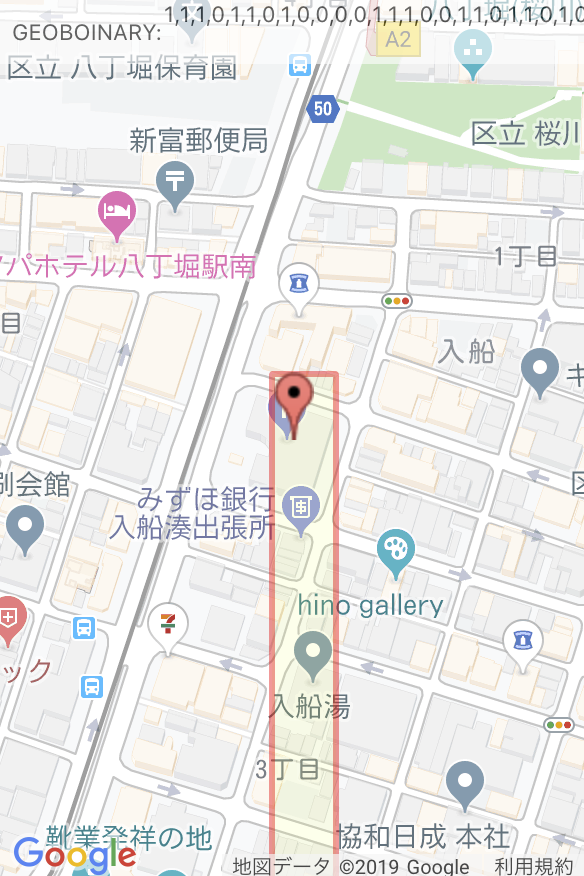
whereを飛ばした桁においては分割を無視しているという事を意味し、下図のように奇数or偶数桁の末尾を何個か飛ばして検索する事で、geoHashでは実現できなかった、細長い領域の検索を一つのクエリで行えます。(※活用法は不明)
(省略しますが、飛ばす桁を変える事でブラインド模様や市松模様でも検索できます。(※活用法は不明))
1: [1,1,1,0,1,1,0,1,0,0,0,0,1,1,1,0,0,1,1,0,1,1,0,1,0,1,1,0,0,1,1,1,1,1,0,1,0,1,0,0]
2: [1,1,1,0,1,1,0,1,0,0,0,0,1,1,1,0,0,1,1,0,1,1,0,1,0,1,1,0,0,1,1,1,1,1,0,1,0,1,0, ]
3: [1,1,1,0,1,1,0,1,0,0,0,0,1,1,1,0,0,1,1,0,1,1,0,1,0,1,1,0,0,1,1,1,1,1,0,1,0, ,0, ]
4: [1,1,1,0,1,1,0,1,0,0,0,0,1,1,1,0,0,1,1,0,1,1,0,1,0,1,1,0,0,1,1,1,1,1,0, ,0, ,0, ]
5: [1,1,1,0,1,1,0,1,0,0,0,0,1,1,1,0,0,1,1,0,1,1,0,1,0,1,1,0,0,1,1,1,1, ,0, ,0, ,0, ]
| 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
 |
 |
 |
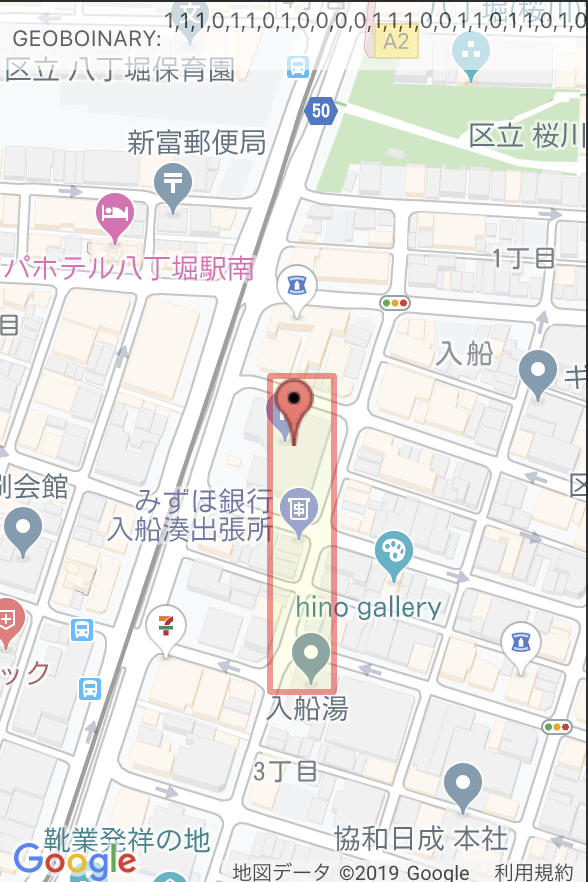 |
 |
・結合
できるだけ少ないクエリで検索を行えるよう計算することも比較的容易です。
まず、表示している範囲内を一定の精度のgeoBinaryで埋めてみたものを考えます。
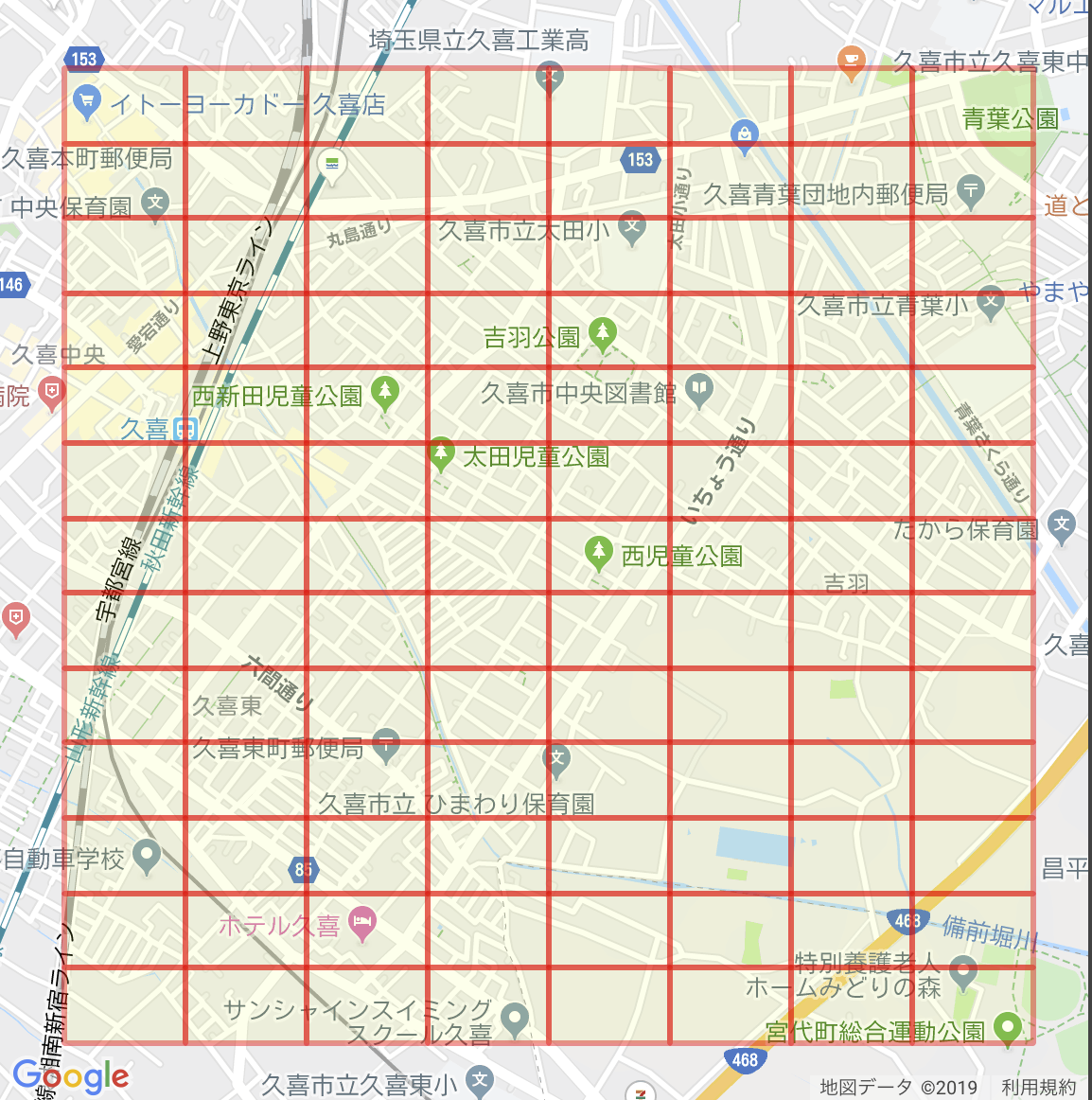
この範囲全てを検索するには、13 * 8 = 114個のor検索が必要になりますが、一部DB(firestoreなど)では、一回に行えるor検索の数が10個以下などに制限されているため、非常に検索の効率が悪い。
ここで隣り合うgeoBinaryを結合を試みます。
[ソート => 連続した二つのgeoBainaryが、最後の桁以外一緒だった場合、最後の桁を消して一つにまとめる]と言う手順を繰り返せば、無駄に細かい領域に分けずに済みます。
例えば、[1110100, 1110101, 1110110, 1110111]の四つの範囲があったとして、
[111010, 111011]=>[11101]と、一つの範囲にまとめることができます。
実際に先ほどの分割領域を結合していったものは下のようになります。
(※下図は繰り返しの中の1手順の中で結合が10回以下しか行われなかった場合は繰り返しを止めています。)

検索すべき対象領域が少なくなりました。
(利用するDBによって、利点か否かが変わってくると思いますが、例えば僕が使っているfirestoreでは、12回の検索が必要だったものが、3回で完了できるようになっており、大きなコスト削減ができています。)
変換
geoBinaryはただのbit列なので、geoHashだけでなく他の形式への変換が非常に容易です。
例えばwhats3wordsのような位置情報を単語で示すといったサービスも、単語リストとgeoBinaryを一定の桁をまとめて数値化したものとを結びつけることで容易に実装できます。
終わりに
最後の方は書きたい事を書きなぐってしまいました。。。
もし、geoHashを使って他にこういう面白いこともできるよ!みたいなことあったらぜひ教えてください!
駄文、乱文、乱文、乱文失礼しました。 ありがとうございました。 ![]()
参考
https://qiita.com/yabooun/items/da59e47d61ddff141f0c
http://saibara.sakura.ne.jp/map/convgeo.cgi