mechanizeで404や500のようなMechanize::ResponseCodeErrorをはいた時に404や500エラーのページを取得したかったという話
考慮されたWebサービスなら404はこんな感じのレスポンスを返すはずです。
Not Found
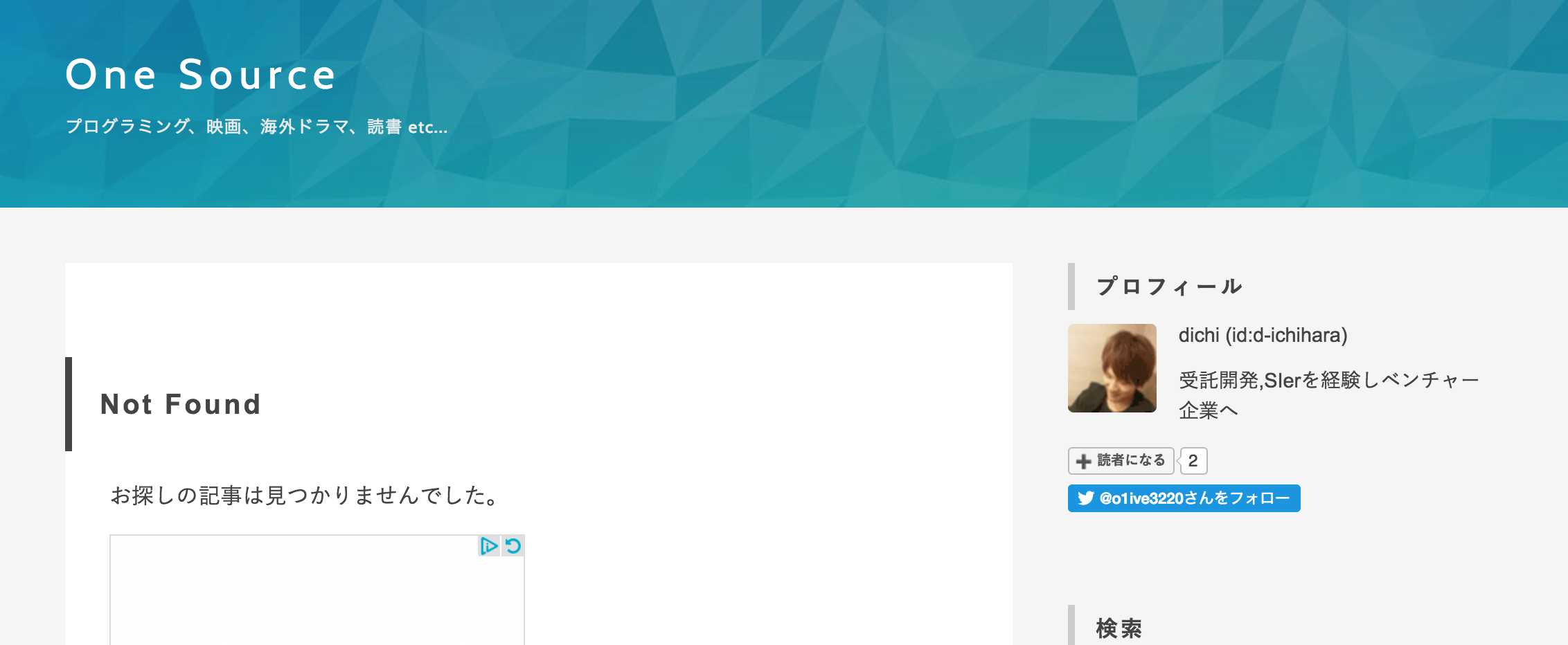
このページを取得して404の際の例外処理をしたかった。
ということで下記のstack orverflowを参考に進めてみました。
http://stackoverflow.com/questions/31408547/ruby-httpnotfound-error-with-mechanize
上記stack overflowで掲載されていたのは下記のようなコード
require 'mechanize'
require 'httparty'
@client = Mechanize.new()
url = 'http://d-ichihara.hatenablog.com/'
begin
result = @client.get(url)
rescue Mechanize::ResponseCodeError => e
redirect_url = HTTParty.get(url).request.last_uri.to_s
result = @client.get(redirect_url)
end
ただこちらのstack overflowに関して言うと僕のやりたいことと前提が異なるようです。
404の例外処理を行いたいのは同じですが、どうやらページは存在するのにたまに404ってでるからどうしよう?と言った感じでした。
なので簡単に言うと、再度URLを取得してmechanizeで取得し直せばいいじゃん?ということでした。
じゃあ404ページを取得したい自分はどうすればいいの?
結論
rescueしたeにすべて持っていました。
ということで修正し直したコードが下記
故意に404ページへとばすためurlを/testとしてあります。
require 'mechanize'
@client = Mechanize.new()
url = 'http://d-ichihara.hatenablog.com/test'
begin
result = @client.get(url)
rescue Mechanize::ResponseCodeError => e
puts e.page.body
end
取得結果
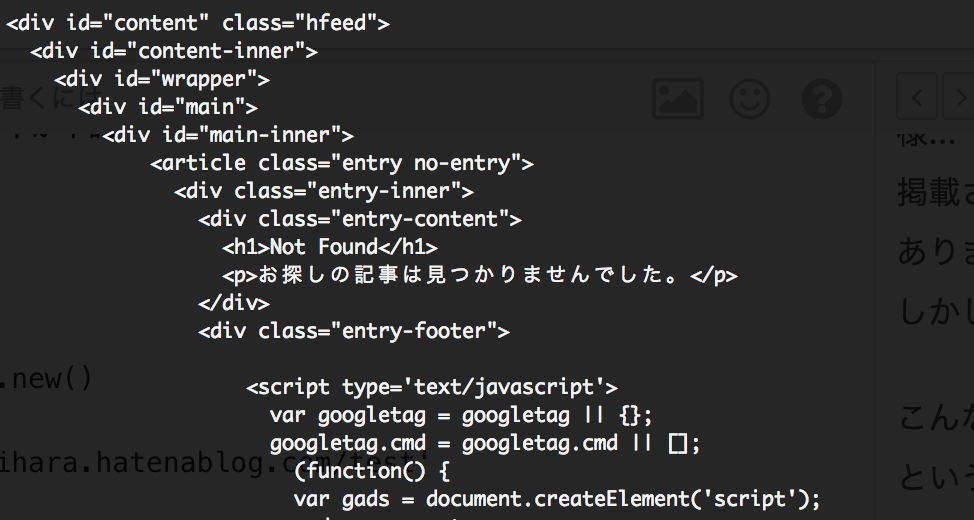
うまくNot Foundのページが取得されました。
あとは、e.page.codeやe.response_codeでコード毎に分けたり、e.page.bodyの文字列を参照するなりしてうまく例外処理できれば解決です。
冷静に考えてみれば、Mechanize::ResponseCodeErrorでrescueしているのだからeにresponseを持っていることはすぐに分かるはずでした...