Vulkan における同期プリミティブ、とりわけ描画中に利用されるものについて、パフォーマンスの違いがあるのかどうか気になったので調べてみました。
Vulkan の同期プリミティブは、
- VkEvent
- VkSemaphore
- VkFence
の3つが存在しますが、この記事では VkEvent は扱いません。
コマンドバッファにセットして使うもののようなので、描画ループの同期機構において使うことはないでしょう。
計測用のコードは作成しましたが公開してないです。申し訳ありません。
したがってポエムとしてお楽しみください。
なお筆者の開発環境は前回から変更なしです。
また計測結果は VK_LAYER_KHRONOS_validation と VK_EXT_debug_utils を有効にした状態で計測していることにご留意ください。
Vulkan の描画ループ
個人的な趣味によりVulkan-Hpp RAIIを使用しています。
auto [result, imageIndex] = swapchain.acquireNextImage(UINT64_MAX, XXXXX, YYYYY);
// 中略
vk::SubmitInfo submitInfo;
queue.submit(submitInfo, ZZZZZ);
vk::PresentInfoKHR presentInfo;
queue.presentKHR(presentInfo);
基本的には描画ループの最初にインデックス取得、描画コマンドの Submit、最後に Present となるでしょうか。
これらの実行順の制御のために同期プリミティブを使用する必要があります。
同期機構を4パターン用意してそのパフォーマンス(FPS)を比較してみました。
- VkFence のみ
- VkSemaphore のみ(CPU同期に
vkDeviceQueueWaitIdle()を使用) - VkSemaphore + VkFence
- VkSemaphore + VkFence をバックバッファ毎に用意
なお、描画内容は共通して単に画面を灰色(0.5, 0.5, 0.5)でクリアするだけのものです。
VkFence で同期
まずは VkFence だけで同期をします。
同期箇所は二か所で、vkAcquireNextImageKHR() と vkQueueSubmit() です。
vkQueueSubmit() の待機は Present 処理の後に行うことに注意してください。
+auto [result, imageIndex] = swapchain.acquireNextImage(UINT64_MAX, VK_NULL_HANDLE, *acquireNextImageWaitFence);
+device.waitForFences(*acquireNextImageWaitFence, VK_TRUE, UINT64_MAX);
// 中略
vk::SubmitInfo submitInfo;
+queue.submit(submitInfo, *submitWaitFence);
vk::PresentInfoKHR presentInfo;
queue.presentKHR(presentInfo);
+device.waitForFences(*submitWaitFence, VK_TRUE, UINT64_MAX);
+device.resetFences(*submitWaitFence);
VkSemaphore で同期
続いて VkSemaphore (とvkDeviceQueueWaitIdle())で同期を試します。
こちらの方法は有名な Vulkan サンプルを提供している SaschaWillems 氏のコードを参考にしました。
しかしながら、vkDeviceQueueWaitIdle()は重い処理で、CPUとGPUの処理を並列に実行させるという点では最適ではない、と注意書きがされています。
なので、別のブランチで同期機構を作り直しているそうです。
その割には更新が無いんですよねこのブランチ・・・
+auto [result, imageIndex] = swapchain.acquireNextImage(UINT64_MAX, *presentCompleteSemaphore, VK_NULL_HANDLE);
// 中略
+vk::PipelineStageFlags waitStage = vk::PipelineStageFlagBits::eColorAttachmentOutput;
vk::SubmitInfo submitInfo;
+submitInfo
+ .setWaitDstStageMask(waitStage)
+ .setWaitSemaphores(*presentCompleteSemaphore)
+ .setSignalSemaphores(*renderCompleteSemaphore)
+ ;
queue.submit(submitInfo, VK_NULL_HANDLE);
vk::PresentInfoKHR presentInfo;
+presentInfo
+ .setWaitSemaphores(*renderCompleteSemaphore)
+ ;
queue.presentKHR(presentInfo);
+queue.waitIdle();
VkFence と VkSemaphore で同期
同期プリミティブ両方を使いますが、単純に両方のコードを合わせるわけではありません。
VkSemaphore で vkDeviceQueueWaitIdle() を使用して同期していたところを VkFence で同期するようにします。
auto [result, imageIndex] = swapchain.acquireNextImage(UINT64_MAX, *presentCompleteSemaphore, VK_NULL_HANDLE);
// 中略
vk::PipelineStageFlags waitStage = vk::PipelineStageFlagBits::eColorAttachmentOutput;
vk::SubmitInfo submitInfo;
submitInfo
.setWaitDstStageMask(waitStage)
.setWaitSemaphores(*presentCompleteSemaphore)
.setSignalSemaphores(*renderCompleteSemaphore)
;
+queue.submit(submitInfo, *submitWaitFence);
vk::PresentInfoKHR presentInfo;
presentInfo
.setWaitSemaphores(*renderCompleteSemaphore)
;
queue.presentKHR(presentInfo);
+device.waitForFences(*submitWaitFence, VK_TRUE, UINT64_MAX);
+device.resetFences(*submitWaitFence);
VkFence と VkSemaphore をバックバッファ毎に用意
サンプルでよく見る形のやつです。
バックバッファ毎に同期プリミティブを用意するやりかたです。
vkAcquireNextImageKHR() で取得するインデックスとは別に同期プリミティブのインデックスを管理しないといけません。
+static uint32_t syncResourceIndex = 0;
+auto [result, imageIndex] = swapchain.acquireNextImage(UINT64_MAX, *frameResources[syncResourceIndex].presentCompleteSemaphore, VK_NULL_HANDLE);
// 中略
vk::PipelineStageFlags waitStage = vk::PipelineStageFlagBits::eColorAttachmentOutput;
vk::SubmitInfo submitInfo;
submitInfo
.setWaitDstStageMask(waitStage)
+ .setWaitSemaphores(*frameResources[syncResourceIndex].presentCompleteSemaphore)
+ .setSignalSemaphores(*frameResources[syncResourceIndex].renderCompleteSemaphore)
;
+queue.submit(submitInfo, *frameResources[syncResourceIndex].submitWaitFence);
vk::PresentInfoKHR presentInfo;
presentInfo
+ .setWaitSemaphores(*frameResources[syncResourceIndex].renderCompleteSemaphore)
;
queue.presentKHR(presentInfo);
+device.waitForFences(*frameResources[syncResourceIndex].submitWaitFence, VK_TRUE, UINT64_MAX);
+device.resetFences(*frameResources[syncResourceIndex].submitWaitFence);
+syncResourceIndex++;
+syncResourceIndex %= frameResources.size();
実行結果
上記4パターンで30秒間実行し、FPSを計測しました。
アプリケーション起動から30秒間の推移をグラフ化したものが以下です(縦単位:FPS、横単位:秒)。
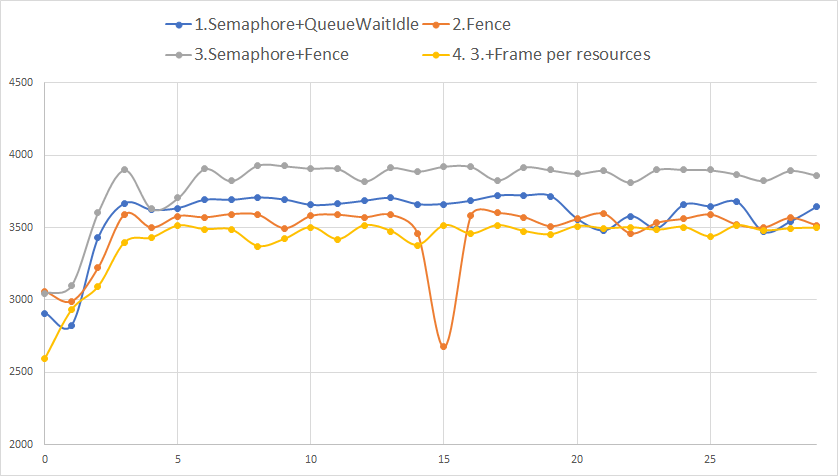
一部妙な値が入っちゃってますが・・・
結構はっきりと違いが出てますね。
パフォーマンスがいい順に
- VkSemaphore + VkFence
- VkSemaphore のみ(CPU同期に
vkDeviceQueueWaitIdle()を使用) - VkFence のみ
- VkSemaphore + VkFence をバックバッファ毎に用意
となります(筆者環境)。
てっきりバックバッファ毎に同期プリミティブを用意したものが最もパフォーマンスがよいと思ってたので驚いてます。
まあ早いからいいってもんでもないと思いますが・・・
考察
(エラー値っぽいのも含まれてますが) 平均FPSは以下のようになりました。
| 項目 | 平均FPS | 1フレーム当たりの処理時間(ミリ秒) |
|---|---|---|
| VkSemaphore + VkFence | 3806.8 | 0.262687822 |
| VkSemaphore のみ | 3583.133333 | 0.279085344 |
| VkFence のみ | 3476.733333 | 0.287626316 |
| VkSemaphore + VkFence (複数) | 3411.3 | 0.293143376 |
1フレーム当たりの処理時間に注目すると、最大で 0.030455554 ミリ秒差があります。
この差は同期するために余分にかかった待機時間ということになります。
この余分な待機時間は描画内容に関係なく常に支払っているコストとも言えます。
とはいえ一般的にはゲームを60FPSで動かす場合、1フレームにかかる時間は16.666...ミリ秒ですから、0.030455554 ミリ秒というのは1フレームのうちのたったの0.18%です。
あと0.18%の処理時間が欲しい!なんてことでもない限りは気にする差ではないかもしれません。
まとめ
今回は描画ループにおける同期プリミティブの使い方を変えて、それぞれのパフォーマンスを比べてみました。
筆者環境におけるパフォーマンスは VkSemaphore と VkFence を組み合わせた形が最もよく、しかしそれをバックバッファ毎に用意するとかえってパフォーマンスが出ないという結果になりました。
筆者は単純な作りが好みなのでバックバッファ毎に用意しなくてもいいかな、という感想でしたが、どれを採用するかはターゲットプラットフォームによって異なりますし、今あるものをあえて崩すほどの違いかどうか、検討することをお勧めします。