はじめに
LangChainのYouTube DocumentLoaderがとても手軽に使えたので、これを使って動画の内容について質疑応答してみます。
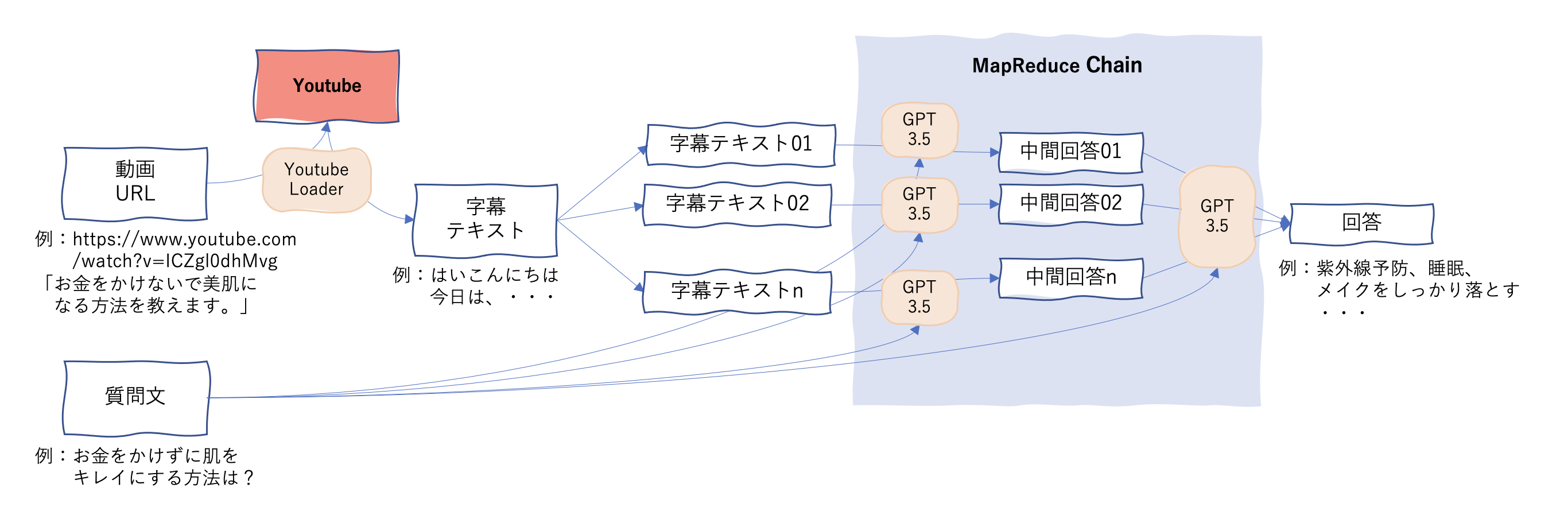
つくるもののイメージは以下のような感じです。
verson
langchain==0.0.157
youtube-transcript-api==0.5.0
pytube==12.1.3
add_video_infoは使用しない(できない)ためpytubeは不要ですが、一応メモしておきます。
3行まとめ
- YoutubeLoaderを使って字幕を取得しました。かなり楽です。
- 字幕のサイズがLLMの最大トークン数よりも大きかったため、適当に分割しました。
- MapReduce Chainを使って質問応答しました。かなり楽ですが、安定しなそうです。
手順
01.Document LoaderによるYoutube字幕の取得
LangChainにはいろいろなDocumentLoaderが準備されていて、お手軽にさまざまな情報源にアクセスできます。YoutubeLoaderはYoutubeの字幕を簡単に取得できます。APIキーも不要なので楽ちんですね。
以下のコードはYouTubeのURLを指定して、字幕を取得するコードです。
from langchain.document_loaders import YoutubeLoader
loader = YoutubeLoader.from_youtube_url(
youtube_url="https://www.youtube.com/watch?v=ICZgl0dhMvg",
language="ja"
)
docs = loader.load()
print(docs)
#>[Document(page_content='はいこんにちは 今日はインスタグラムフロー様から
# ... はいご視聴ありがとうございました ています', metadata={'source': 'ICZgl0dhMvg'})]
- 日本語字幕を取得する場合は
language="ja"と指定します。 -
continue_on_failure=Trueとすると、字幕がない場合のエラーは無視されます。 -
add_video_info=Trueとすると、タイトルや再生数も取得できたようなのですが、23/05/04時点では使用できないようです。そもそもpytubeが動かなくなっているようです。
02.MapReduceChainによるQA(質疑応答)
先ほど取得した字幕は美容外科医の高須幹弥さんの「お金をかけないで美肌になる方法を教えます。」という動画です。今回はこの動画を対象にしてみます。高須幹弥さんのYoutubeチャンネルは、ひとり語り系なのでLLMの外部情報ととして使うにはちょうど良いです。ただ専門用語も多いため、ひろゆきチャンネル等と比べると難易度は少し高いと思います。
02-01.トークン数の確認
まずは字幕のトークン数を数えます。
gpt-3.5-turboの最大トークン数は4096なので、入力(質問+字幕)と出力のトークン数が4000に収まりそうならば、字幕をすべてて入れてしまえば良いと思います。収まらない場合は分割するなり、質問に該当しそうな箇所だけ抜き出すなり何かしら工夫が必要です。
import tiktoken
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
tokens = encoding.encode(docs[0].page_content)
tokens_count = len(tokens)
print(f"{tokens_count}")
#> 5374
今回の字幕のトークン数は5374と最大トークン数よりも大きいため、何かしら工夫が必要です。
02-02.テキスト分割
次にプロンプトに収まるように字幕テキストを分割します。
特に根拠はないのですが、ひとつのテキストが1000文字を超えない程度に字幕を分割していきます。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 100,
length_function = len,
)
split_docs = text_splitter.create_documents([docs[0].page_content])
print(len(split_docs))
#> 6
字幕テキストは、6つに分割されました。
02-03.MapReduce ChainによるQA
最後に分割されたテキストを使ってQA(質疑応答)します。
複数のテキストから情報を取得し回答する方法はいくつかあるのですが、今回はMapReduce Chainというものを使ってみます。これは、分割されたテキストに同じ質問をして、各回答を最後に結合するものになります。他にも、分割されたテキストを頭から順番に読んでいくRefine Chainというものや、分割された文書をベクトル化して質問と類似する文書だけ引っ張ってきて回答するRetrievalQAといった方法もあります。
MapReduce Chainは並列に動かすので、Refine Chainと比べて時間はかかりませんが、テキストの順序は考慮できません。また分割されたテキストをすべてLLMに入れるため、RetrievalQAと比べて課金額が大きくなります。実際にはどれかひとつを選ぶのではなく、うまく組み合わせてうのだと思います。
以下がMapReduce Chainを使ったQAです。return_map_steps=Trueと指定することで、中間回答も出力されいます。intermediate_stepsが、分割されたテキストそれぞれに質問して得た中間回答で、output_textが最終的な回答です。
from langchain.chat_models import ChatOpenAI
from langchain.chains.question_answering import load_qa_chain
chatmodel = ChatOpenAI(model_name='gpt-3.5-turbo',temperature=0)
chain = load_qa_chain(chatmodel, chain_type="map_reduce", return_map_steps=True)
query='お金をかけずに肌をキレイにする方法はなんですか?'
chain({"input_documents": split_docs, "question": query}, return_only_outputs=True)
#{'intermediate_steps': [
# 'そうねえと、お金をかけずに肌を綺麗にする方法はたくさんありますよね。遺伝によって左右される部分もありますが、普段のケアや努力によって改善できる部分もあります。皮膚の厚さや皮脂の分泌量などによっても左右されますが、食事やケアによって改善できることもあります。ケアや努力はとても大事なので、遺伝的にキレイな肌でもケアが怠るとどんどん老化してしまうこともあるので注意が必要です。',
# 'まあ本当にいっぱいあって今紫外線予防とか睡眠とかメイクをしっかり落とすとかタバコとかアルコール取らないとかまた栄養をしっかり取るとかねあとまあオーバーカロリーになってね太らないとかねやっぱりたくさん食べて太ってしまうとそれだけ皮脂の分泌が多くなるとかですねニキビができやすくなるとかそういうのもあるのでやっぱり食べスピットのも良くないわけなんですけれどまずで順番にお花しようと思うんですけどやっぱり一番大事なのね一番というねまぁすごく大事なのはね紫外線予防ですよね紫外線はですねやっぱり肌当たるとシミシワもできますはいコラーゲンが破壊されて皮膚がたるんですよく開始は細かいシワができるというのもあるしメラニン色素を産生してそれによってシミ',
# '該当するテキストはありません。',
# 'あとはタバコとねある交流これで絶対ダメですね秒食いにいくか言われる方でもねあのタバコ吸ってる方よくいらっしゃるんですよタバコ吸うと 末梢の音 if の末梢の血流がですね 疎外されるんですよ血管が収縮されるので 2位て皮膚の回復力が落ちたりとかターン オーバーが落ちたりとかこちらが増えたり とかのシミができやすくなったりというの はありますしあとでアルコールもねぇあの やっぱりよくないですまあ特にの3府議が 良くないんですけれど アルコールってね基本的に体にとって得な ので僕はもう一匹ものはないんですよ でアルコール飲むとねある程度肝臓に負担 がかかってしまってねそれによって タンパク質の合成が落ちて肌ってタンパク 質でできてますのでしっかりタンパク質 つくるっていうことがね裏の張りのある肌 を作るのに大事なんですけどアルコール 言語とするのが阻害されるというのがあり ます あとはねやっぱり栄養ですねもっと200 ねバランスのとれたね食事を取るというの が大事です',
# 'この文書には、この質問に関する情報は含まれていません。',
# 'まぁお金をかけなくても美肌になるための方法ってねこんな感じでたくさんありますのでよかったら実践してみてください。すいませんあと補足なんですけれどあのお肌をねきれいにするためにはストレスをためたいっていうこともねすごい大事なんですね。ストレス貯めないというのもすごい大事なことです。'],
#'output_text':
# 'お金をかけずに肌をキレイにする方法は、紫外線予防、睡眠、メイクをしっかり落とす、タバコやアルコール取らない、栄養をしっかり取る、オーバーカロリーにならないように食事をするなどがあります。ただし、遺伝的な要因もあるため、努力やケアが必要です。また、ストレスをためないことも大切です。'}
まず 「お金をかけずに肌をキレイにする方法」を聞いてみました。
わりとうまく動いています。ただ中間回答の口調や形式が安定していないですね。字幕をそのまま抜き出してる感があります。
query='肌がキレイな人としてどのような人が紹介されていますか?'
chain({"input_documents": split_docs, "question": query}, return_only_outputs=True)
#{'intermediate_steps': [
# '文中には、肌がきれいか綺麗じゃないかっていうのはだいたいねぇ半分くらいは遺伝によって左右されるんですね残りの半分は普段のケアポカラ努力によって左右されるんですねやっぱり遺伝っていうのがね半分ぐらいやってまという記述があります。つまり、遺伝的な要因と普段のケアや努力によって肌がきれいになる人がいるということが言及されています。',
# 'There is no specific person being introduced as having beautiful skin in the given text. The text discusses the importance of skincare and efforts to maintain healthy skin, as well as various methods of skincare including those done at beauty clinics and those that can be done at home without spending money. It also mentions the importance of UV protection, proper sleep, makeup removal, avoiding tobacco and alcohol, and maintaining a healthy diet to prevent skin aging and other issues.',
# '睡眠不足の人よりも、比較的綺麗な肌を持つ人が多いとされています。',
# '引きこもりの人が肌がきれいな人として紹介されています。外に出ないため、メイクをしないことで炎症が起きないためです。',
# 'There is no relevant text to answer this question in the given portion of the document.',
# "I'm sorry, I cannot answer that question as the given text does not provide information about a specific person or group of people who have beautiful skin."],
# 'output_text':
# '与えられたテキストには、特定の人物が美しい肌を持っていると紹介されているわけではありません。テキストは、スキンケアや健康的な肌を維持するための努力の重要性、美容クリニックで行われる方法やお金をかけずに自宅で行える方法など、さまざまなスキンケア方法について説明しています。また、肌の老化やその他の問題を防ぐために、UV保護、適切な睡眠、メイク落とし、タバコやアルコールの回避、健康的な食生活の維持の重要性についても言及しています。'}
次に、「肌がキレイな人はどのような人か」を聞きました。
こちらの質問では、中間回答が英語になってますね。MapReduceのプロンプトが英語で書かれているためだと思います。また中間回答では「引きこもりの人が肌がきれいな人として紹介されています。」と質問の回答を正しく取得できているのに、最終回答ではその情報がなくなっていますね。あまりうまく動いていないように思います。
まとめ・感想
YoutubeLoaderとMapReduce Chainをつかって 、Youtubeの字幕テキストに質疑応答してみました。
とてもお手軽に使えますが、MapReduceは日本語文書を入れる場合はプロンプトが英語のままでいいの?とか思いました。