はじめに
F-ZERO GX は,私が最もハマったゲームの一つで,レースゲームである.ゲーム画面は下図のようで,画面右下にスピードメータがあるのがわかるだろう.このスクリーンショットでの指示値は 8860 km/h である.

さて,このスピードメータの指示値を1フレームずつ手で記録して,時系列変化をプロットし,マシンの挙動を分析する,といった研究を,十数年前はやっていた.当然指示値をテキストに変換する作業は単純かつ面倒なので,機械化したいところである.本ゲームのスピードメータは,数字の位置,フォント,色等が固定であり,比較的機械化が容易な対象であるといえる.
しかし,当時は私のスキルも未熟で,画像認識に置いて驚異的な性能を示して一気に普及したディープラーニングの開花前だったこともあり,機械化は実現しなかった.スピードメータの背景が透明であり,ゲーム中の背景そのものとなるという点がネックで,文字色に近い青白い背景となる場合があり,手作業での文字認識はそれなりに難しかったのである.
それから時は流れ,ディープラーニングを扱うライブラリも充実し,一般人が触ることも容易になった.今こそスピードメータの指示値をテキストに変換するプログラムを作ろうと再計画し,ようやく実現した.最終的な変換器の実装方式としては,AviUtl の出力プラグインが便利であろうということで,これを選択した.
以下では,完成したプラグインを紹介した後,実装の過程を語る.
プラグインの入手と使い方
インストール
プラグインはソースコードごと GitHubで公開 しているので,git clone または releases からダウンロードし,fzgx_smr_ks.auo を AviUtl のルートまたは plugins フォルダにコピーすればよい.
使い方
インストールできていれば AviUtl で F-ZERO GX のゲームプレイの録画データを開き,ファイル → プラグイン出力 → SMR for F-ZERO GX と選択し,出力テキストファイル名を入力して「保存」すれば,スピードメータを読み取ったテキストを出力する.
入力の動画としては,録画したままの 720x480 の映像であり,「ワイド画面 (16:9)」用であることを想定している.インターレース映像であれば,このスクリプト などでインターレース解除してから1プラグイン出力をするとよい.
4:3 用の出力映像を録画した場合や,拡縮を掛けてしまった後の動画のスピードメータを読み取りたい場合は,スピードメータ部分の画像サイズが 16:9 用の 720x480 の映像と同じになるように拡縮し,後述のウィンドウ位置を適切に設定する必要がある.
設定等
プラグイン出力のファイル名入力ダイアログで「ビデオ圧縮」ボタンを押すと,下図のようなコンフィグダイアログが現れる.
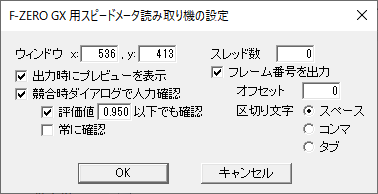
「ウィンドウ」はスピードメータの数字部分の左上の座標である.「出力時にプレビューを表示」にチェックを入れると,正しく数字部分を切り取れているかどうかをチェックするためのダイアログを使い,確認するとともに,必要に応じてこの座標値を調整することができる.「競合時ダイアログで人力確認」にチェックを入れると,複数のモデルの推定結果が異なる場合に,人の目で正しい指示値を入力するためのダイアログを出す.「評価値x以下でも確認」にチェックを入れると,評価値(確信度)が入力した数値以下の場合にも同様に確認ダイアログを出す.「常に確認」にチェックを入れると,評価状況に関わらず常に確認ダイアログを出す.「スレッド数」にはマルチスレッド処理に使うスレッド数を指定する.0以下なら指定値+論理コア数を代わりに用いる.「フレーム番号を出力」にチェックを入れると,出力ファイルの 1 行を「フレーム番号 スピードメータ指示値」のようにする.「オフセット」は出力範囲の最初のフレームのフレーム番号を指定し,「区切り文字」ではフレーム番号とスピードメータ指示値の間の文字をスペース,コンマ,タブのいずれかから選択する.コンマにすると csv ファイルとして適正なファイルを出力できる.
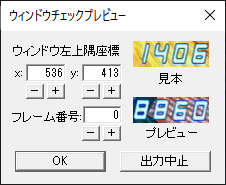
「出力時にプレビューを表示」で表示されるダイアログは上図のようである.「見本」と同じように4桁の数字が表示できるように「ウィンドウ左上隅座標」の数字を変更する.キーボード入力してもいいし,「+-」ボタンで変更してもいい.「フレーム番号」は「プレビュー」の表示に使うフレームの指定に用いる.「ウィンドウ左上隅座標」についてはこのダイアログで変更した値を用いて出力するが,「フレーム番号」は出力結果に影響しない.
ウィンドウ位置は多少ずれていても認識に支障はないように作っているが,できるだけ上図と同じような位置であるほうがよいため,録画環境等で微妙にずれている場合は調整することをおすすめする.4:3 用の動画を使う場合などには,リサイズとウィンドウ位置が適切かどうかはこのダイアログで判断してほしい.
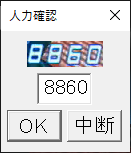
「競合時ダイアログで人力確認」で表示されるダイアログは上図のようである.機械的な推定値がデフォルト入力されているので,間違っている場合は人の手で正しい値を入力して「OK」を押すと,その文字を出力して次のフレームに移る.「常に確認」にチェックを入れて始めてしまったけど途中でやめたくなった場合などには「中断」を押すと出力を中断できる.
機械学習モデルの作成
学習データの準備
機械学習を行うためには,正解データとセットになったデータセットが必要である.このスピードメータでは,概ね一文字あたり 19x26 程度になることがわかったので,連番画像出力 で F-ZERO GX の動画ファイルを画像に変換した後,次のようなコードで numpy.ndarray に変換する.
from PIL import Image
import glob, random
import numpy as np
frames = 100000
n, width, height = frames*4, 19, 26
window_x, window_y = 536, 413
x_c = np.empty((n, height, width, 3), dtype='float16')
x_r = np.empty((n, height, width, 3), dtype='float16')
for i, file in enumerate(glob.iglob('./fig/*.png')):
img = Image.open(file)
for j in range(4):
x = window_x+width*j
xr, yr = random.randrange(-2, 2), random.randrange(-2, 2)
for k in range(width):
for l in range(height):
rgb = np.array(img.getpixel((x+k, window_y+l)))/256.0
x_c[i*4+j, l, k, :] = rgb
rgb = np.array(img.getpixel((x+xr+k, window_y+yr+l)))/256.0
x_r[i*4+j, l, k, :] = rgb
x_c がメインのデータで,x_r はウィンドウのズレにロバストなモデルを作るのに使う,わざとランダムにずらしたデータである.Image#getpixel では (横,縦) なのに対し,学習データでは一般的な (サンプル, 縦,横,色) の shape を使い,縦横の順が異なる点に注意したい.また,メモリを節約するために dtype は float16 としているが,256 で割っているため,もとの uint8 からの劣化はない2.uint8 のほうが必要なメモリは少ないが,学習時に浮動小数点数に変換する必要があるので,float16 としておくのが便利と思われる.これをファイルに保存する場合は,次のようにする.
import h5py
def h5_dump(obj, filename):
with h5py.File(filename, mode='w') as f:
dataset = f.create_dataset('data', data=obj, compression='gzip', compression_opts=9, shuffle=True)
def h5_load(filename):
with h5py.File(filename) as f:
return f['data'][...]
h5_dump(x_c, 'x.hdf5')
x_c = h5_load('x.hdf5') # ファイルからロードする時
圧縮前のファイルサイズが概ね 14GB を超えてくると pickle ではうまく保存できないようなので,HDF5 を使う.HDF5 はもっといろいろなこともできるのだが,とりあえず ndarray を保存したいだけなら上のようにするとよいだろう.
また,アノテーションの用途のために,一つ一つの画像をファイルにしたり,画面に画像を表示したい場合があるが,そのときは次のようにする.
import matplotlib.pyplot as plt
def save_image(npa, file):
width, height = 19, 26
img = Image.new('RGB', (width, height), (0, 0, 0))
for j in range(width):
for k in range(height):
rgb = tuple((npa[k, j, :]*256.0).astype('uint8'))
img.putpixel((j, k), rgb)
img.save(file)
def show_image(npa):
plt.tick_params(which='both', bottom=False, top=False, left=False, right=False, labelbottom=False, labelleft=False)
plt.imshow(npa)
save_image(x_c[0, :, :, :], './0.png')
show_image(x_c[0, :, :, :])
正解データの準備
正解データを作るには,最終的には人の目でのアノテーションが必要である.しかし,大量の画像データを分類するのは容易ではないため,ちょっとした補助がほしい.私が注目したのはオートエンコーダとクラスタリングである.実はここをやったのは2年位前で,詳細は忘れてしまったため,概要だけ紹介する.
まず,Keras を使ってオートエンコーダを実装する.Conv2Dで小さくした後でFlattenし,更にDenseで 4次元くらいまで圧縮した後,GaussianNoise,Dense,Reshape,Conv2DTranspose を経てもとのサイズにする.ノイズレイヤーを通してもとの画像に戻るようにしているので,ある程度文字ごとに分離してくれることを期待している.
次に,オートエンコーダでエンコードした 4 次元データを,クラスタリングでクラスタに分割する.確か scikit-learn の AgglomerativeClustering で 16 クラスタぐらいに分割したと思う.クラスタごとにフォルダを分けて,上に示した save_image で各画像を保存して,アノテーションの準備が完了する.
オートエンコーダとクラスタリングである程度似た画像同士に分けられているものの,「背景の多い1と背景のみの画像」とか「2と5」「5と6」「8と9」のように似た文字は混ざったクラスタになってしまっているため,人の手によるアノテーションでなんとかするしかない.分けたいクラスは 0 ~ 9 と「背景のみ」の 11 クラスである.11 個のフォルダに人の手で分類していった後,フォルダに格納されているファイル名で人の手で決めたクラスを求めることになる.似た画像にまとめられているため,一度に多数のファイルを同じフォルダに投入できるため,完全に人の手で分類するよりはだいぶ楽に分類できたが,最終的にはまあ力技である.
ところで,何しろ大量の画像を分類する必要があったため,どうしてもヒューマンエラーは排除できない.そのため,分類したデータに基づいて機械学習による推定を行い,間違えた画像を確認し,分類の修正を行っていく.これを繰り返すと信頼性の高い正解データを作ることができる.
また,追加のデータを投入するときは,既存のデータで作成した機械学習モデルで分類したあと,人の目でチェックを入れ,さらに機械学習による推定と間違えた画像の確認により修正していく.
最終モデルの作成
テキトーにモデルをいじって良さそうなモデルを探し,最終的には次のようなモデルを使うことにした.
import keras
from keras import layers
from keras.models import Model
input_layer = layers.Input(shape=(26, 19, 3,), name='input')
nw = input_layer
nw = layers.Conv2D(16, (6, 3), padding='valid', activation='relu', data_format='channels_last', name='conv0')(nw)
nw = layers.Conv2D(32, (6, 2), padding='valid', activation='relu', data_format='channels_last', name='conv1')(nw)
nw = layers.Dropout(0.125)(nw)
nw = layers.MaxPooling2D(pool_size=(2, 2), padding='valid', data_format='channels_last', name='pooling')(nw)
nw = layers.Conv2D(16, (2, 2), strides=(2, 2), padding='valid', activation='relu', data_format='channels_last', name='conv2')(nw)
nw = layers.Flatten()(nw)
nw = layers.Dense(32, activation='relu', name='dense0')(nw)
output_layer = layers.Dense(11, activation='softmax', name='output')(nw)
clf = Model(input_layer, output_layer)
clf.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
x_, y_ = h5_load('./x.hdf5'), h5_load('./y.hdf5')
idx = np.not_equal(y_, 11)
x, y = x_[idx], keras.utils.to_categorical(y_[idx], 11)
clf.fit(x, y, batch_size=256, epochs=8)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input (InputLayer) (None, 26, 19, 3) 0
_________________________________________________________________
conv0 (Conv2D) (None, 21, 17, 16) 880
_________________________________________________________________
conv1 (Conv2D) (None, 16, 16, 32) 6176
_________________________________________________________________
dropout_1 (Dropout) (None, 16, 16, 32) 0
_________________________________________________________________
pooling (MaxPooling2D) (None, 8, 8, 32) 0
_________________________________________________________________
conv2 (Conv2D) (None, 4, 4, 16) 2064
_________________________________________________________________
flatten_1 (Flatten) (None, 256) 0
_________________________________________________________________
dense0 (Dense) (None, 32) 8224
_________________________________________________________________
output (Dense) (None, 11) 363
=================================================================
Total params: 17,707
Trainable params: 17,707
Non-trainable params: 0
_________________________________________________________________
Conv2D 2 段で 16x16 にした後,Dropout,MaxPooling2D でロバスト性を担保し,Dense の前に weighted average pooling + Dense のイメージで strides=kernel_shape な Conv2D をはさみ,Flatten,Dense,Dense で 11 カテゴリに.activation は,最後はもちろん softmax で,中間は単純に全部 relu とした.loss は分類で標準的な categorical_crossentropy,optimizer は adam とした.バッチサイズとエポック数は根拠なし.最終的なデータ数は 829,165.
なお,上のコードで np.not_equal(y_, 11) としているのは,ちょっと学習データに使わないほうがいいかなというデータ3を 12 個目のカテゴリとしていて,これを外したものである.
C++ へのデプロイに向けた重みの出力
さて,上記で Keras のモデルは作れたわけであるが,AviUtl の出力プラグインとして実装するためには,もう一手必要である.AviUtl から Keras を使えるようにするのは面倒であるが,幸いそれほど複雑なモデルではないので,重みをテキストで出力して,推定器を C++ で実装してしまおう.というわけで,重みをリテラルで表した C++ のコードに変換するために,次のようなコードを使う.
def node2d(varname, shape, file):
print('float %s[%d][%d][%d];' % (varname, shape[1], shape[2], shape[3]), file=file)
def node0d(varname, dim, file):
print('float %s[%d];' % (varname, dim), file=file)
def conv2d_kernel(varname, npa, file, scale=None):
height, width, in_ch, out_ch = npa.shape
print('constexpr static const float %s[%d][%d][%d][%d] = {' % (varname, height, width, in_ch, out_ch), end='\n\t', file=file)
for i in range(height):
print('{', end='\n\t\t', file=file)
for j in range(width):
print('{', file=file)
for k in range(in_ch):
print('\t\t\t{', end=' ', file=file)
for l in range(out_ch):
if scale is None:
val = npa[i, j, k, l]
else:
val = npa[i, j, k, l]*scale
print('%s%.7ef' % (('' if val<0 else ' '), val), end=(', ' if l<(out_ch-1) else ' '), file=file)
print('}', end=(',\n' if k<(in_ch-1) else '\n\t\t'), file=file)
print('}', end=(', ' if j<(width-1) else '\n\t'), file=file)
print('}', end=(', ' if i<(height-1) else '\n'), file=file)
print('};', file=file)
def bias(varname, npa, file):
n = npa.shape[0]
print('constexpr static const float %s[%d] = {' % (varname, n), end='\n\t', file=file)
for i in range(n):
print('%.7ef' % (npa[i],), end=(', ' if i<(n-1) else '\n'), file=file)
print('};', file=file)
def dense_kernel(varname, npa, file):
in_ch, out_ch = npa.shape
print('constexpr static const float %s[%d][%d] = {' % (varname, in_ch, out_ch), file=file)
for i in range(in_ch):
print('\t{', end=' ', file=file)
for j in range(out_ch):
val = npa[i, j]
print('%s%.7ef' % (('' if val<0 else ' '), val), end=(', ' if j<(out_ch-1) else ' '), file=file)
print('}', end=(',\n' if i<(in_ch-1) else '\n\t'), file=file)
print('};', file=file)
weights = clf.get_weights()
with open('./weights.cpp', 'w') as f:
# 中間層用のメンバ変数 (サイズをKerasのモデルに合わせて用意)
node2d('inter0', clf.get_layer('conv0').output_shape, f)
node2d('inter1', clf.get_layer('conv1').output_shape, f)
node2d('inter2', clf.get_layer('pooling').output_shape, f)
node2d('inter3', clf.get_layer('conv2').output_shape, f)
node0d('inter4', clf.get_layer('dense0').output_shape[1], f)
# 重み用の static const メンバ変数
conv2d_kernel('Conv0K', weights[0], f, 1.0/256.0)
bias('Conv0B', weights[1], f)
conv2d_kernel('Conv1K', weights[2], f)
bias('Conv1B', weights[3], f)
conv2d_kernel('Conv2K', weights[4], f)
bias('Conv2B', weights[5], f)
dense_kernel('Dense0K', weights[6], f)
bias('Dense0B', weights[7], f)
dense_kernel('Dense1K', weights[8], f)
bias('Dense1B', weights[9], f)
最初の Conv2D の重みは,画素値を 256 で割る分を織り込むため,ここで割っておく.FLT_EPSILON が約 1e-7 なので,%.7e でテキストにしておけばだいたいいいだろう.
ちなみに,今回は小さいモデルなのでこのようにテキストで出力して,C++ コンパイラでバイナリに戻すことを考えているが,大きなモデルの場合,テキストサイズが馬鹿にならないため,HDF5 等で保存し,C++ 側からも外部ファイルまたは埋め込みリソースとして HDF5 を読み込むといった実装にしたほうがよいだろう.
C++ による推定器の実装
ちょっとコピペコードでかっこ悪いが,次のように実装した.今回はサイズが小さいからいいようなものの,畳み込みは 6 重ループとなり,ナイーブな実装はかなり重くなるということがよく分かる.
constexpr static const int width = 19;
constexpr static const int height = 26;
class Cnn {
private:
# include "weights.cpp"
void
conv0(const unsigned char *src, int s)
{
for (std::size_t i=0; i<std::size(inter0); i++) {
for (std::size_t j=0; j<std::size(inter0[i]); j++) {
for (std::size_t k=0; k<std::size(inter0[i][j]); k++) {
inter0[i][j][k] = Conv0B[k];
for (std::size_t di=0; di<std::size(Conv0K); di++) {
for (std::size_t dj=0; dj<std::size(Conv0K[di]); dj++) {
for (std::size_t c=0; c<3; c++) {
inter0[i][j][k] += static_cast<float>(src[(height-i-di)*s+(j+dj)*3+2-static_cast<int>(c)])*Conv0K[di][dj][c][k];
}
}
}
if ( inter0[i][j][k] < 0.0f ) {
inter0[i][j][k] = 0.0f;
}
}
}
}
}
void
conv1()
{
for (std::size_t i=0; i<std::size(inter1); i++) {
for (std::size_t j=0; j<std::size(inter1[i]); j++) {
for (std::size_t k=0; k<std::size(inter1[i][j]); k++) {
inter1[i][j][k] = Conv1B[k];
for (std::size_t di=0; di<std::size(Conv1K); di++) {
for (std::size_t dj=0; dj<std::size(Conv1K[di]); dj++) {
for (std::size_t c=0; c<std::size(Conv1K[di][dj]); c++) {
inter1[i][j][k] += inter0[i+di][j+dj][c]*Conv1K[di][dj][c][k];
}
}
}
}
}
}
}
void
pooling()
{
for (std::size_t i=0; i<std::size(inter2); i++) {
for (std::size_t j=0; j<std::size(inter2[i]); j++) {
for (std::size_t k=0; k<std::size(inter2[i][j]); k++) {
inter2[i][j][k] = 0.0f;
for (std::size_t di=0; di<2; di++) {
for (std::size_t dj=0; dj<2; dj++) {
if ( inter2[i][j][k] < inter1[i*2+di][j*2+dj][k] ) {
inter2[i][j][k] = inter1[i*2+di][j*2+dj][k];
}
}
}
}
}
}
}
void
conv2()
{
for (std::size_t i=0; i<std::size(inter3); i++) {
for (std::size_t j=0; j<std::size(inter3[i]); j++) {
for (std::size_t k=0; k<std::size(inter3[i][j]); k++) {
inter3[i][j][k] = Conv2B[k];
for (std::size_t di=0; di<2; di++) {
for (std::size_t dj=0; dj<2; dj++) {
for (std::size_t c=0; c<std::size(Conv2K[di][dj]); c++) {
inter3[i][j][k] += inter2[i*2+di][j*2+dj][c]*Conv2K[di][dj][c][k];
}
}
}
if ( inter3[i][j][k] < 0.0f ) {
inter3[i][j][k] = 0.0f;
}
}
}
}
}
void
dense0()
{
for (std::size_t i=0; i<std::size(Dense0B); i++) {
inter4[i] = Dense0B[i];
std::size_t j=0;
for (std::size_t a=0; a<std::size(inter3); a++) {
for (std::size_t b=0; b<std::size(inter3[a]); b++) {
for (std::size_t c=0; c<std::size(inter3[a][b]); c++) {
inter4[i] += inter3[a][b][c]*Dense0K[j++][i];
}
}
}
if ( inter4[i] < 0.0f ) {
inter4[i] = 0.0f;
}
}
}
void
dense1()
{
float sum = 0.0f;
for (std::size_t i=0; i<11; i++) {
output[i] = Dense1B[i];
for (std::size_t j=0; j<std::size(Dense1K); j++) {
output[i] += inter4[j]*Dense1K[j][i];
}
output[i] = std::exp(output[i]);
sum += output[i];
}
for (auto& e : output) {
e /= sum;
}
}
public:
float output[11];
void
predict(const unsigned char *src, int dibw)
{
conv0(src, dibw);
conv1();
pooling();
conv2();
dense0();
dense1();
}
};
src として渡す画像データには,oip->func_get_video(frame) で取得するDIB形式の画像を使用する.DIB形式のデータ幅としてdibw=(oip->w*3+3)&(~3)を用いる.これは,幅が 4 の倍数でない場合,4 の倍数になるようにパディングが発生するというDIB形式の仕様によるもので,oip->w*3 以上の最小の 4 の倍数が dibw となる.
また,DIB形式の画像データと,ndarray の画像データとは,高さ方向と色方向の順序が逆であるため,これに配慮して値を取得する必要がある.うっかり間違えていて,デバッグがかなり面倒だった.
出力プラグインとしての実装
使い勝手の向上のためになれないダイアログを作ったりとか,ダイアログ中にプレビュー画像を表示させたりとかにそこそこ苦労したが,これも実装はだいぶ昔で忘れてしまったので,素人作品ながら,ソースコードを見てくださいとだけ言っておきます.
全体としては,グローバル変数を使いすぎていて,よくないかなと思います.
分類問題としての考察
冒頭で述べたように,本問題は分類問題としては難しくない.というよりかなり容易なレベルで,少なくとも MNIST よりは簡単だろう.学習データにおける正答率は 0.9999 を超える.しかし,それでも間違えてしまう画像もあるにはある.正答の評価値が低い方から 18 番までの画像は,次のとおりである.

左上の「A(0.01):6(0.99)」は,左上のスリップゾーンのみ写っている画像の正解はA(背景のみ)であるが,このモデルでの評価値は 0.01 で,さらに (何故か) 0.99 もの確信度をもって 6 だと思っているという意味である.その右隣の,斜めに青いラインが入っている画像 (どこかわかるかな?4) を 1 と識別しにくいのはまあ仕方ないだろう.その他,ブースターの火花が「1」のように走ったものや,極端に中心がずれている文字の認識が難しいことがわかる.
このように,いくつか難しいケースもあるものの,概ね良好に認識できており,技術的に語るべきこともあまりないが,こうしたらもっといいかもなどの情報があればコメントいただけると幸いである.
また,この問題はさほど難しくないため,必ずしも CNN は必要ない.もとの $19\times 26\times 3$ 次元ベクトルからの Random Forest 等でもかなり高精度の分類が可能である.ファイアーフィールドに限定するなら,線形 SVC でも良好な分類器を構成できる.
ちなみに,十数年前は何をやっていたかというと,青白さ基準で2値化したあと細線化,その後トポロジー等を計算して文字種判別,ということをやろうとしていた.しかし,スリップゾーンはもとより,ブースターの火花がかかると2値化もままならないことが判明し,諦めるに至った.
おわりに
ようやく念願のスピードメータ自動読み取り機が完成したので,中途半端に止まっている F-ZERO GX のスピード周りの分析を再開したい.
-
スピードメータ読み取りの場合,「空間方向補間」でインターレース解除することをおすすめする.空間方向補間において生じる上下の揺れはメータ読み取りの支障にはならない一方で,時間方向の情報が入ってフォントが歪むと,正しい数字を読み取ることが難しくなる場合がある.そのため,失敗する可能性もある「動き適応型」よりも「空間方向補間」のほうが安全である.なお,F-ZERO GX はプログレッシブ出力が可能なソフトなので,プログレッシブで録画するのが一番よいのは言うまでもない. ↩
-
255で割る例も散見されるが,量子化誤差が生じるため,個人的には256で割るほうが好みである. ↩ -
うっかりインターレースで出力した映像があり,ちゃんとデインターレースできていなくてぐちゃぐちゃで文字が判別不能な画像が含まれていた.データから即外してしまうより,12 個目のカテゴリとして,後で見直しもできるようにしていたものである. ↩
-
サンドオーシャンのスターティンググリッドの横向きの線である.こんな風に写るのはわざとやらないとまず表れないので,まあ問題はないだろう. ↩