
*DeepLearningを用いた物体検出アルゴリズムはいくつかありますが、本記事はSingle Shot Multibox Detector(SSD)についていくつかのポイントを解説します。*本記事はこちらの記事を和訳したものです。
最近Convolutional-Neural-Networkを用いた物体検出アルゴリズムは、「何」が「どこ」にあるかという2つの情報を同時に識別できるようになっています。更に精度 (mAP:mean Average Precision)も年々上がっています。特にYOLOモデルが提案されてから検出がより高速になり、リアルタイム処理が可能となりました。2016年に提案されたSSDは、mAPもFPSもさらにYOLOを上回って、注目されています。しかし、精度に関しては、その後提案されたYOLOv2 (YOLO9000) に負けてはい
ますが、物体検出で画期的なアルゴリズムの一つとして、研究する価値が大です。
SSD demo on PC
PC版のデモです。

実装:SSD Tensorflow
データセット:Pascal VOC 2007+2012
クラス数:20
入力動画:こちらよりダウンロード
FPS: 20FPS
CPU: i7-7700 3.6GHz
GPU: NVidia 1050Ti
OS: Ubuntu 16.04
SSD demo on FPGA
PCではほぼリアルタイムで動くことを実現していますが、物体検出自体はPCベースだけではなくて、モバイルデバイスやエンベデッドシステム上で動作することが常に求められています。しかし、モバイルデバイスですと、CPUの処理能力がネットとなりますので、CPUだけではリアルタイム性を実現するのが困難です。
下記のデモはcaffeやkerasなどの主流のDeepLearningフレームワークをサポートしているAI accelerator DV500/DV700 を使用してFPGAでリアルタイムに動くことが可能です。

評価環境: ZYNC ZC706@70MHz
FPS: 19.8
Single Shot Multibox Detector Overview
SSDと他のアルゴリズムとの比較は下記の図に示します。
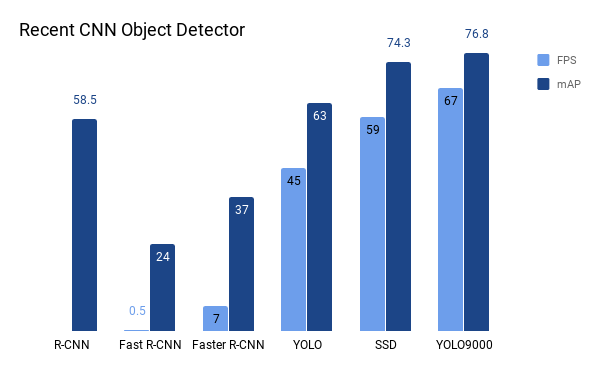
SSDは他とはどう違うか、や、なぜ高速かなど、他のアルゴリズムより優れているところを解説していきます。更に詳しいチュートリアルについてはこちらをご参照ください。
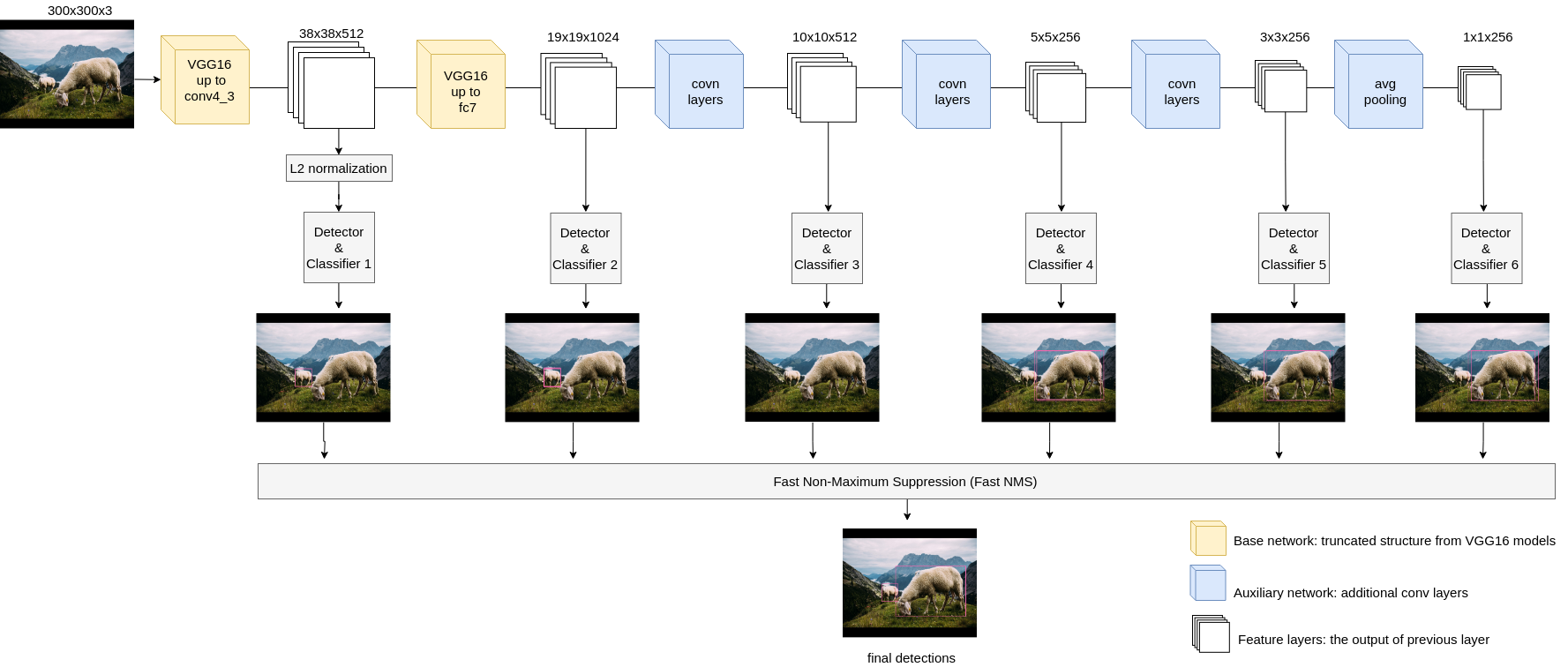
以下にSSD処理の流れを示めします。
What makes it fast?
一つ大事なポイントとしてはSSDのネットワークのアーキテクチャです。
SSDでは画像の入力から、物体の位置を表すbounding box(bbox)と各クラスの確信度を表すclassification confidenceを出力するまでの一連の処理はこのネットワークでEnd-to-Endで行うものですのでコストが軽くて済む。それに対して、前世代のR-CNNではこの処理をいくつかのフェーズに分けて異なるネットワークで学習させるものなのでコストが高い。(例えば、region proposalとclassifierとはそれぞれ異なる工程で学習)
What improves the accuracy?
結論からいうと、物体のスケールに応じて検出を複数回行ったからです。
下記のflow diagramを見てみると、各feature layerはネットワークの深さとともにサイズが減っていき、feature layerが作成されるたびに検出も行う。最終的に複数の検出結果をまとめてFast NMS処理で重なったボックスをマージするという流れになっています。その理由としては、convolution layerは局所特徴を捉えることができるので、feature layerがどんどん減っていくから、小さいものは最初に、大きいものは最後に検出できるということから、feature layer単位で検出するようにすれば、異なるサイズの物体に対応可能だからです。したがって従来法より精度が良いと。
Bounding Box Proposal
R-CNN時代では、まずターゲットとなりうるobject candidatesを求めてから各クラスの確信度を計算するのに対して、SSDでは各feature layerにおけるbboxの場所、aspect ratio、スケールとサイズを予め定義しておきます。つまり、SSDでは、内容の異なる画像でもデフォルトbboxの数が変わらないということです。デフォルトbboxは、なるべく画像領域全体を網羅するように設置する。論文では一つのクラスに属するデフォルトのbboxの数は7308とされています。
検出時に、一つのbboxには全てのクラスとなりうる確信度が求められ、そのうち確信度が閾値 (i.e. 0.5) を超えるものの中から、上からN個分のbboxのみ採用します。その後Fast NMS処理によって、領域の重なったbboxがマージされ、最終的な一つの物体に対してはひとつのbboxを生成するという仕組みです。