*本記事はこちらの記事を和訳したものです。
はじめに
YOLOv3は物体検出手法シリーズYOLO(You Only Look Once)の一つです。v2と比較して精度が良くなり、特に小さいものの検出が効果的。本記事はYOLOv3における改善点について解説していきます。
YOLOv3アルゴリズム
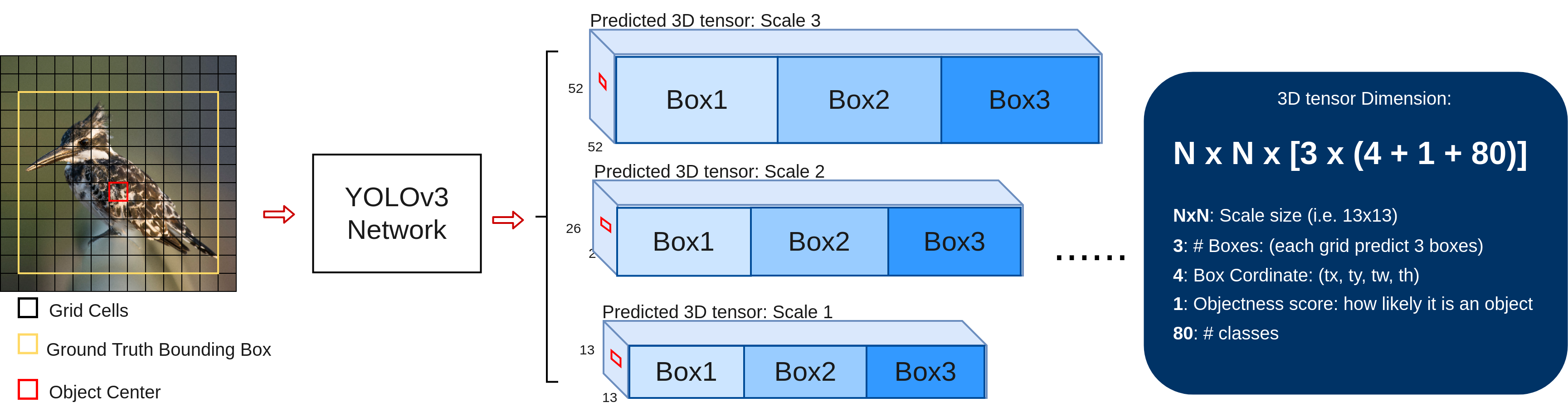
上の図のように、学習時において、学習データ(画像)ごとに異なるスケールに対応する3つの3D tensorを予測します。13x13のスケールを例にして説明します。まず、スケールが13x13だから、入力画像を13x13のgrid cellに分けます。すると、入力画像における、各grid cellの予測結果が3D tensorの中の1x1x255のvoxelになります。各grid cellには、3サイズのbounding box, 各boxに、4つの座標と、検出対象かどうかを表すobjectness scoreと、ラベルの確信が格納されています。よって、(3x(4+1+80))=255。
もしground truthのboxの中心があるgrid cellの中にあった場合(例えば鳥の画像の赤いbox)、該当する物体のboxの予測はこのgrid cellがやります。すると、このgrid cellは、鳥のboxを予測することになるので、objectness scoreが1に、ほかのgrid cellは0になります。各grid cellは予めサイズの異なるprior boxを3つアサインされているので、ground truthとサイズが一番近いものを選んで更に座標オフセットの調整を行っていきます。3つのサイズの中、最適なのはどれかというのが疑問ですが、論文の作者によると、ground truthのbounding boxと重なった面積が(IOU)が一番大きいprior boxを選ぶという。
上記の3つのprior boxは一体どのようにゲットしたかというと、学習前にK-means clusteringを利用してCOCOデータセットにある全てのbboxを9個に分類します。スケールが3なので、3スケールx3個=9個。こういう先験情報を利用して学習はより高速に収束し、オフセット・座標もより正確に予測できると期待できます。
ネットワークアーキテクチャ
YOLOv3のアーキテクチャは下記の図に示します。このネットワークは主に75層の畳み込み層からなり、物体の特徴量を抽出します。Fully connected層を使わないので入力画像のサイズが任意です。また、pooling layerの代わりにstride=2の畳み込み層を用いることで特徴マップをダウンサンプリングし、スケール不変な特徴量を次の層までへ伝播可能。このほか、YOLOv3では、ResNetとFPN構造を利用して検出精度を更に向上。ResNet及びFPNに関しては後述します。
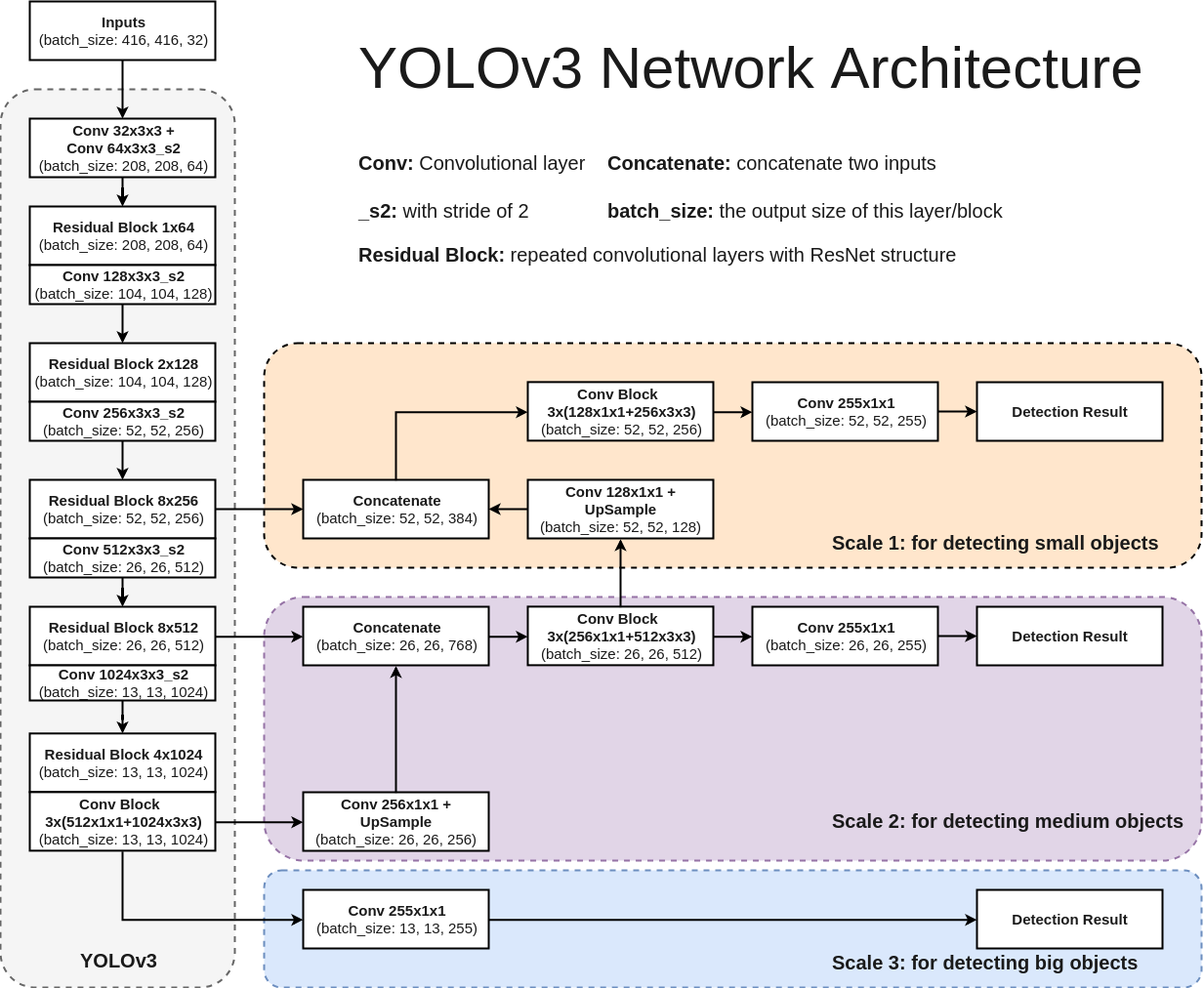
3 Scales: 異なるスケールに対応
通常画像にある物体のサイズがさまざまですが、一回の処理で全ての物体をもれなく検出できるのが望ましいです。なので、何らかの手段で異なるサイズへの対応が必要とされています。何故かというと、特徴マップがネットワークの深さとともに縮小していきますから、小さい物体の検出は層につれて難易度が上がります。直感的に大きさによって異なる段階で物体を検出するのが理想的。この仕組みはSSDで実装されています。
しかしながら、各特徴マップにおける特徴量が深さによって変化しているものです。どういうことかというと、最初はローレベルな特徴量(エッジ、カラー、物体の大まかな位置など)を学習していますが、層の深さにつれて、ハイレベルな特徴量(意味的な物体情報:犬、猫、車など)に変わっていきます。ものを検出するのにやはりハイレベルな特徴量が必要です。従って異なる特徴マップで異なるスケールの検出はできなくはないのだが、実際に精度はそんなに高くない。
そこで、YOLOv3では、スケール対策としてFPN構造を用いる。
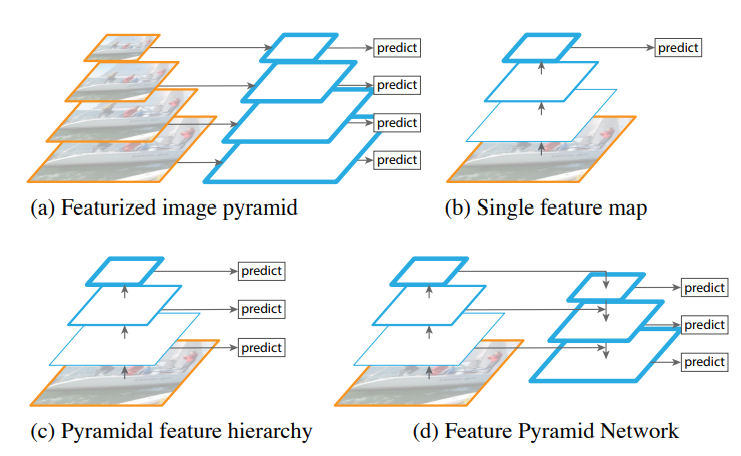
スケール対策としては、主に下記の4つが考えられます。
(a) 一番単純な手法。画像ピラミッドを構築し、レベルごとにCNNで物体を検出。異なるスケールで違うネットワークを用いることで一応検出可能。だが、一枚の画像に対して複数のネットワークで処理しなければならないので処理時間が長い
(b) 最後の特徴マップで物体検出を行う。異なるスケールに対応不可。
(c) 異なる特徴マップで物体検出を行う。SSDに採用されている構造です。しかし、検出はその特徴マップまでに取得した情報しか利用できず、それ以降の特徴マップは活用されていない。
(d) (c)によく似ていますが、現在の特徴マップは、それ以降の特徴マップをアップサンプリングしてマージすることによって、より意味のある情報を取得できて、精度の向上に役立ちます。
ResNet:特徴量を上手に学習するため
YOLOv3では、ResNet構造(上記の図ではResidual Block)を使用しています。Residual Blockとは、従来のネットワークアーキテクチャにshortcut pathを加える形です。
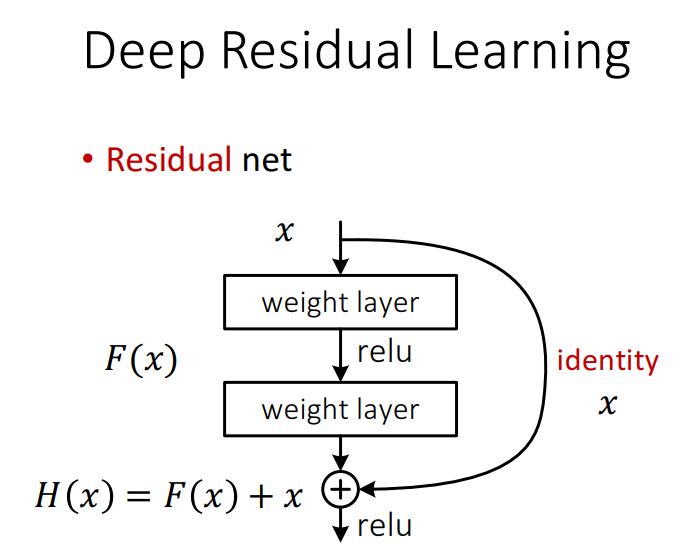
本来、層が深くなると、学習が難しくなるのですが、shortcut pathを加えることによって、「ある層で求める最適な出力を学習するのではなく、前層の入力を参照した残差関数を学習する」ことで特徴量の学習をしやすくしています。そうすると、もともと複雑な特徴量H(x)は、古い特徴量xに新しく学習した残差F(x)を足し合わせれば済む。それによって学習の難易度が下がるので、層の深度の限界を押し上げることができ、精度向上を果たすことができました。
Softmax層の禁止:多重分類への対応
分類問題において出力が一つのラベルのみ属する場合は、Softmaxが多く使用されてきましたが、分類数が多くなるとラベルが重なることがあります。例えば、womanとperson。そのような場合は精度の改善に相応しくありませんので、代わりにlogistic関数を使うと良い。
Demo GIFs
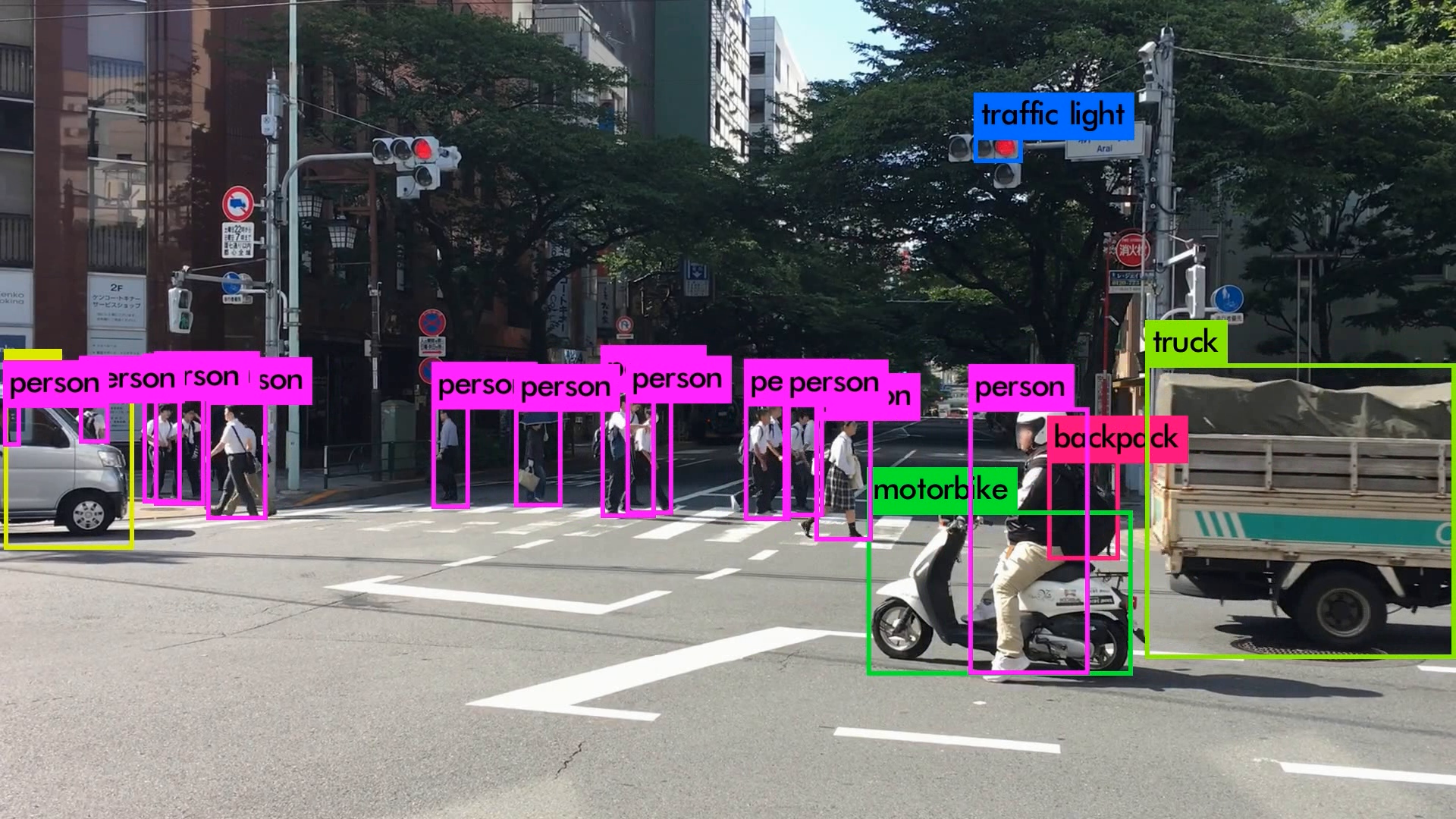
いろんなシーンの映像を使用してYOLOv3を動かしてみました。小さい物体は見事に検出しています。さらに、人がバイクに乗っている場合、personとmotorcycleそれぞれ検出しているのは素晴らしいです。また、大量に集まる人間や鳥の群れなどもひとつのボックスとして検出するのはすごいです。
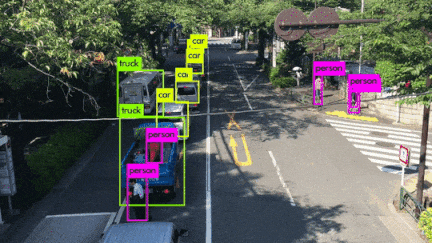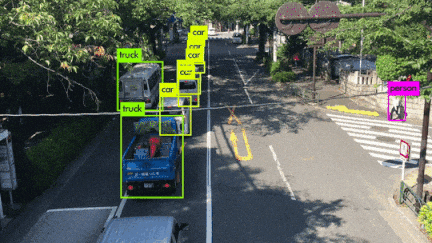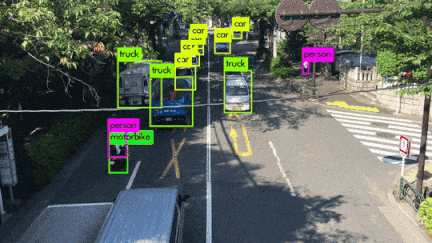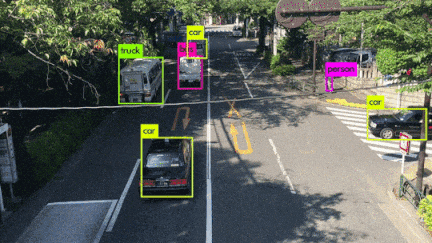

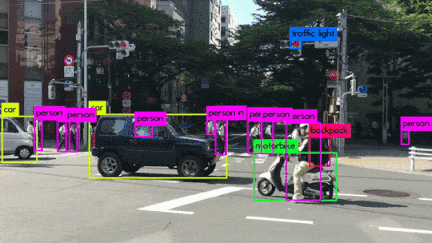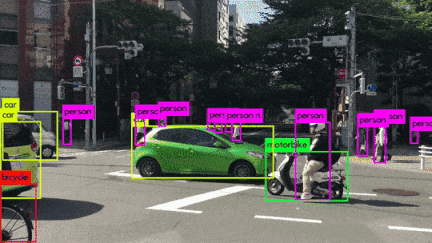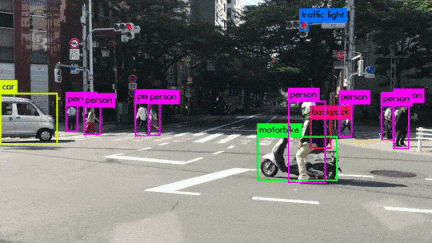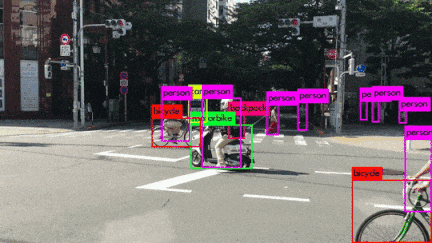
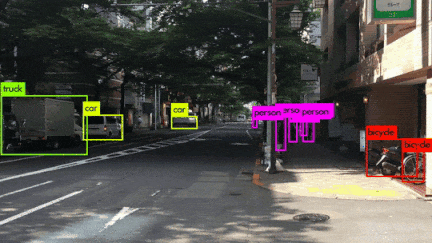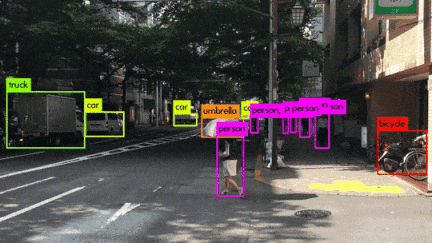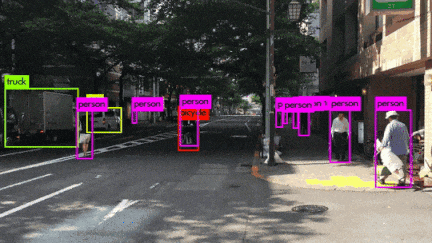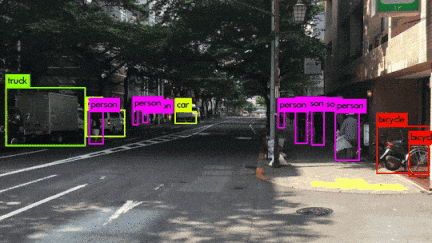

YOLOv3 Performance on Desktop PC
Tiny YOLOv3
YOLOv3では速度を少し犠牲にして、精度を上げましたが、モバイルデバイスにしてはまだ重いです。でもありがたいことに、YOLOv3の軽量版であるTiny YOLOv3がリリースされたので、これを使うとFPGAでもリアルタイムで実行可能です。
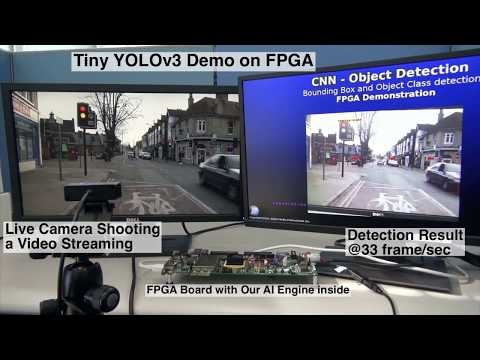
Tiny YOLOv3 Performance on FPGA
Platform: FPGA+DV500/DV700 AI accelerator
Board: ZYNC ZC706
Performance: 30 millisecond / frame
quality, which affects the detection accuracy a bit.
※リアルタイム性を示すために、あえてUSBカメラでモニタ画面を撮影してTinyYOLOv3を動かしたので、2台の画面にタイムラグが生じています。また、USBカメラでモニタ画面を撮ると、画質が悪くなって精度が若干落ちます。
Reference:
- YOLOv3 Tech Report: This report is fun to read.
- YOLOv3 Implementation: Easy to try. Just follow the instructions.
- Feature Pyramid Networks for Object Detection: The paper
- Deep Residual Learning: The presentation slides