RAGを弄っていて、Kendraから離れようとするとすぐにEmbedding(エンベディング)が付いて回るので、Amazon BedrockからTitan Embeddingsを弄ってみます。
Titan Embeddingsとは
Bedrockから使用可能な、文章をEmbedding(ベクトル化)する基盤モデルです。8000トークンまでの文章を1536次元のベクトル(1536個の数値表現)に変換します。
コサイン類似度とは?
2つのベクトルについて、コサイン類似度が1.0に近いほど文章が類似していると判定します。つまり、「コサイン類似度が近いか」≒「文章が類似しているか」の判定(判定を繰り返す事で、検索)を行う事が出来ます。
ライブラリの追加
コサイン類似度の計算の為に以下をインストールします。
pip install -U scikit-learn
作ったもの
試しやすいようにStreamlitでガワを被せています。
from langchain.embeddings import BedrockEmbeddings
from sklearn.metrics.pairwise import cosine_similarity
import streamlit as st
st.title("コサイン類似度 測ルンです \n(Titan Embeddings)")
input_text_1 = st.text_area("文章1")
input_text_2 = st.text_area("文章2")
send_button = st.button("送信")
if send_button:
# 文章1,2のEmbedding
embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v1")
vector_1 = embeddings.embed_documents([input_text_1])
vector_2 = embeddings.embed_documents([input_text_2])
# コサイン類似度の計算
similarities = cosine_similarity(vector_1, vector_2).tolist()[0][0]
st.write("コサイン類似度: " + str(similarities))
st.text("文章1のVector: ")
st.write(vector_1)
st.text("文章2のVector: ")
st.write(vector_2)
実行
python -m streamlit run cos1_titan_embeddings.py
文章1に入力されたものと文章2に入力されたもののコサイン類似度を出力するプログラムです。
以下のデータセット(JGLUE:日本語言語理解ベンチマークのJSTSデータセット)から幾つかピックアップして、sentence1とsentence2のコサイン類似度を見てみます。
labelが0.0のものを幾つか試します。
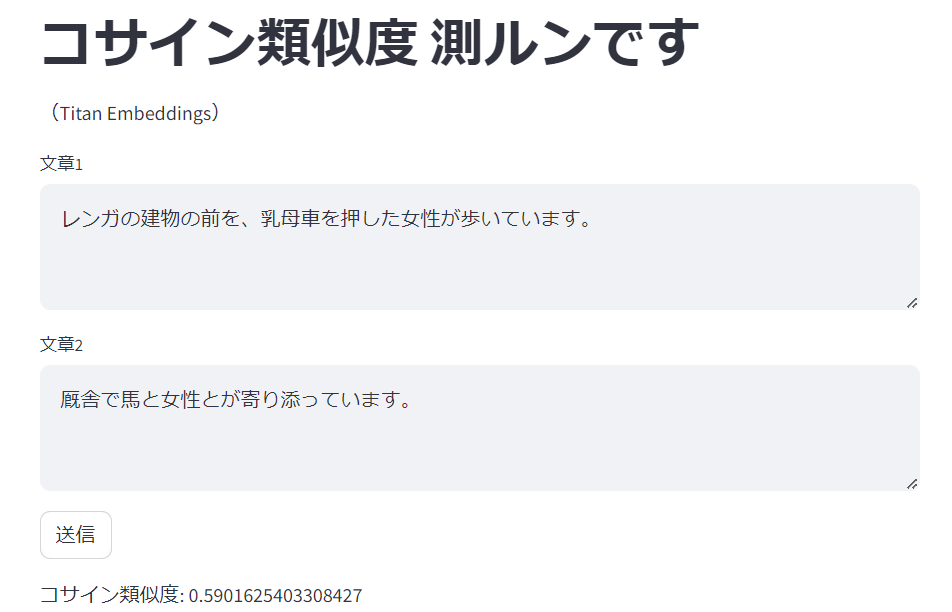
コサイン類似度: 0.5901625403308427
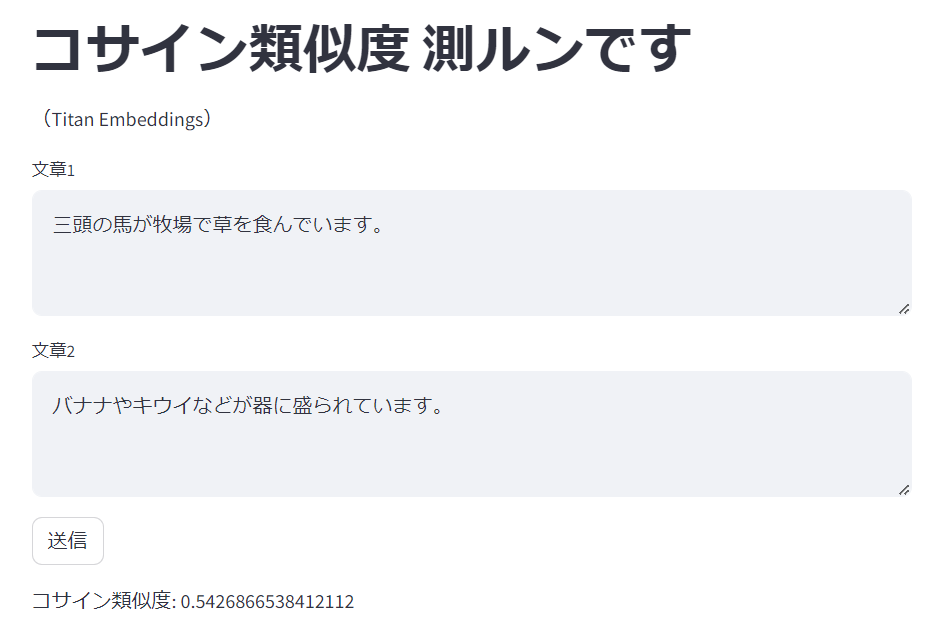
コサイン類似度: 0.5426866538412112
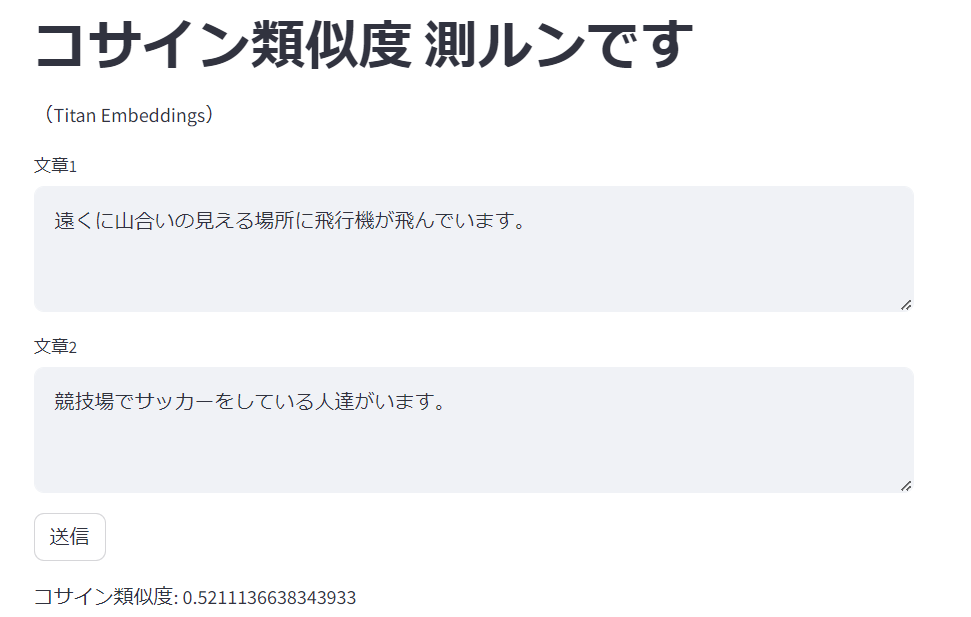
コサイン類似度: 0.5211136638343933
関係なさそうな文章のコサイン類似度は0.5程度になりました。
今度はlabelが4.xのものを幾つか試します。
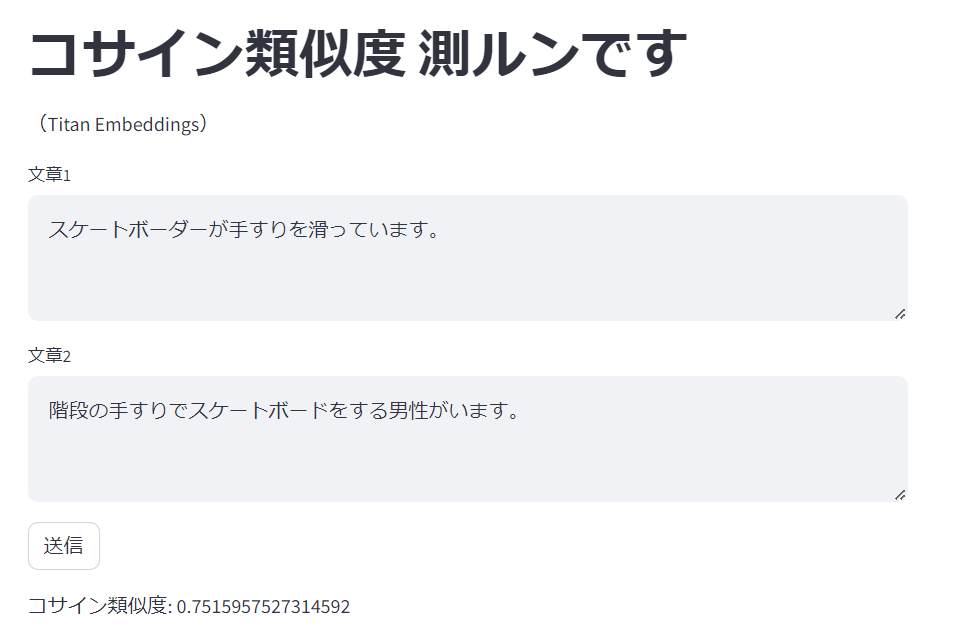
コサイン類似度: 0.7515957527314592
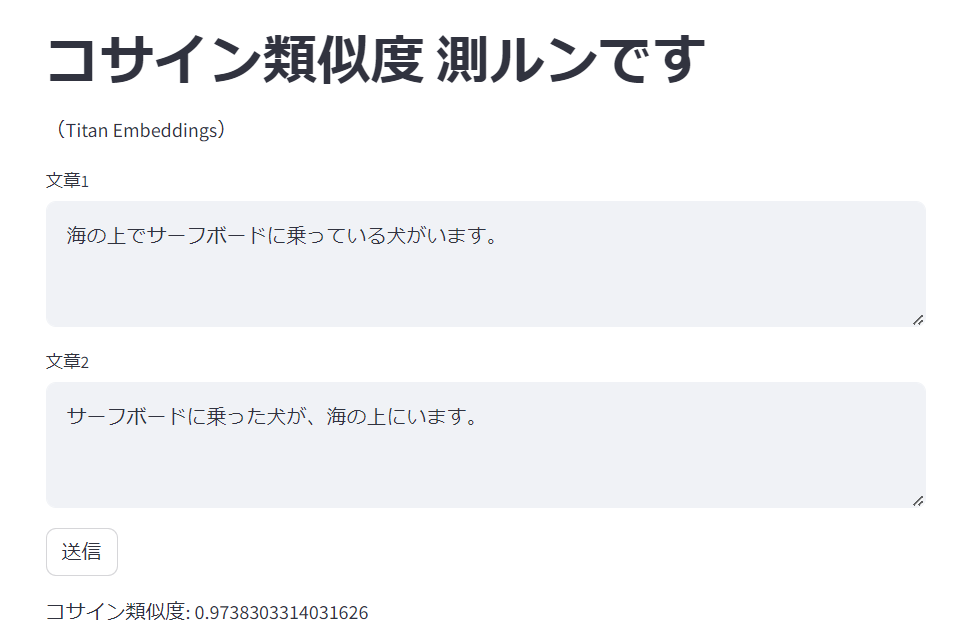
コサイン類似度: 0.9738303314031626
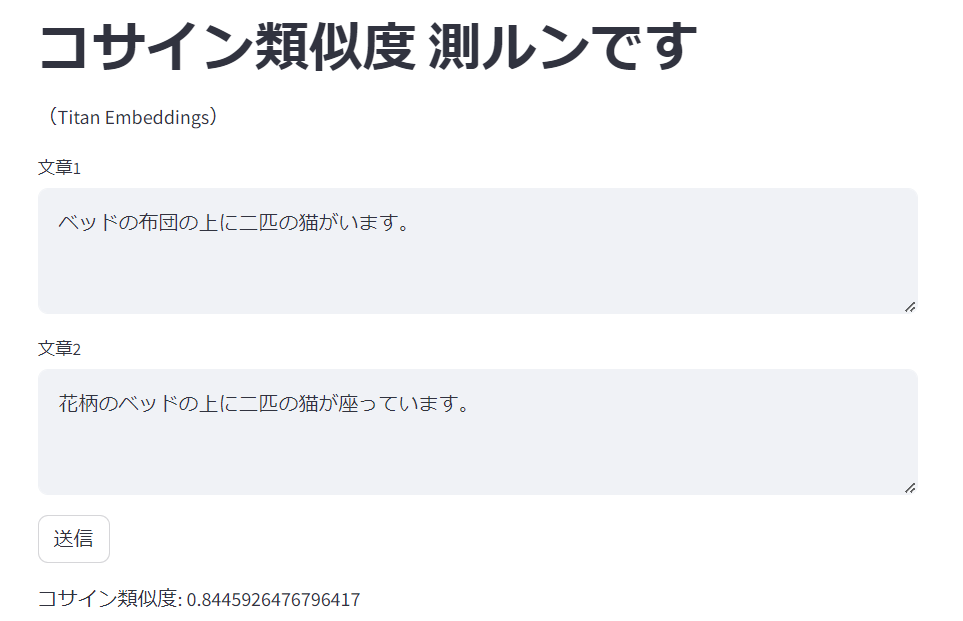
コサイン類似度: 0.8445926476796417
明らかに高い値になりました。
最後にlabelが3.0のものを試してみます。

コサイン類似度: 0.8151813631142061
上記のlabelが4.xのものの間に挟まってますが(スケートボーダーのものよりも類似していると判定している)、私はそんなに違和感を感じませんでした。
ちなみに画面下部にはTitan Embeddingsの1536次元のベクトル(1536個の数値表現)を表示しています。見ても何も分かりませんが、Titan Embeddingsではこんな数値に置き換えられているんだなという事は見れます。
データセット全量に対するスピアマン順位相関係数を求める
上述のデータセットには1457件のデータがあり、手作業では確認が出来ないので、テストプログラムを作ってTitan Embeddingsのコサイン類似度とデータセットのラベルについて相関係数を求めてみます。
スピアマン順位相関係数とは?
1に近いほど相関関係が強い、と判定できるらしいです。
ライブラリの追加
追加のライブラリをインストールします。
pip install -U sentence_transformers
実行
上述のデータセットをカレントディレクトリに保存し、以下を実行します。
(CodeWhispererにある程度書いてもらってから直しました)
from langchain.embeddings import BedrockEmbeddings
from sklearn.metrics.pairwise import cosine_similarity
import json
from scipy.stats import spearmanr
cosine_ary = []
label_ary = []
with open("valid-v1.1.json", encoding="utf-8") as f:
for line in f:
line = json.loads(line)
# 文章1,2のEmbedding
embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v1")
vector_1 = embeddings.embed_documents([line["sentence1"]])
vector_2 = embeddings.embed_documents([line["sentence2"]])
# コサイン類似度の計算
similarities = cosine_similarity(vector_1, vector_2).tolist()[0][0]
# 配列に追加
cosine_ary.append(similarities)
label = line["label"]
label_ary.append(label)
# スピアマン順位相関係数
correlation, pvalue = spearmanr(cosine_ary,label_ary)
print(correlation)
0.7293064575666538
スピアマン順位相関係数は0.729となりました。
こちら(↓)の結果と少し違うなと思わなくも無いですが良しとします。
同じになりました。何れにしろOpenAI Embeddingsには少し劣りそうです。
Titan Embeddingsは上述の日本語お手本データセットと順位の相関関係がある=日本語文章に対してもそれなりの性能を持っていそうだなという事が分かりました。