StepFunctionsからBedrockが呼べるらしいので、どうせならKendraも組み合わせてノーコードでRAGを実現してみます(Amazon States Languageはコードでは無いものとします)。
2024/1/22
よく見るとStepFunctionsからKendraのQueryAPIだけでなくRetrieveAPIも呼べたので修正しました(私が見落としていたのかUpdateされたのか不明)。真ん中のステップのみ微修正しています。
これで世の中のKendra+BedrockのRAGと同等の事が出来ているはずです。
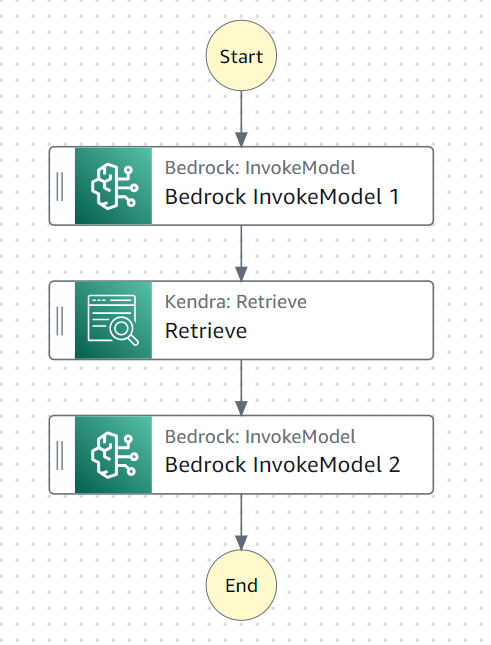
処理の流れ
- 最初のステップではユーザー入力を元にLLM(Claude Instant)に検索キーワードを考えてもらいます
- 真ん中のステップでは検索キーワードを元にKendraを検索します
- 最後のステップで、ユーザー入力(≠検索キーワード)とKendraの検索結果からLLM(Claude2.1)で回答を生成します
最初のステップ
Bedrock InvokeModelを使います。
設定タブの内容は以下
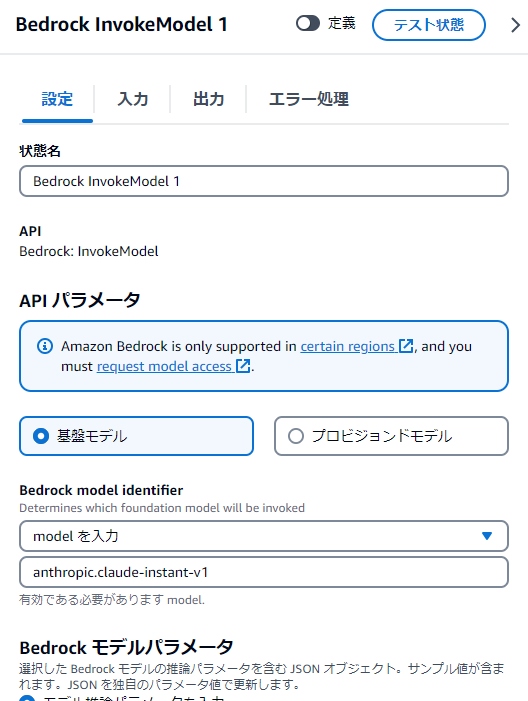
モデルはanthropic.claude-instant-v1を使用しました。
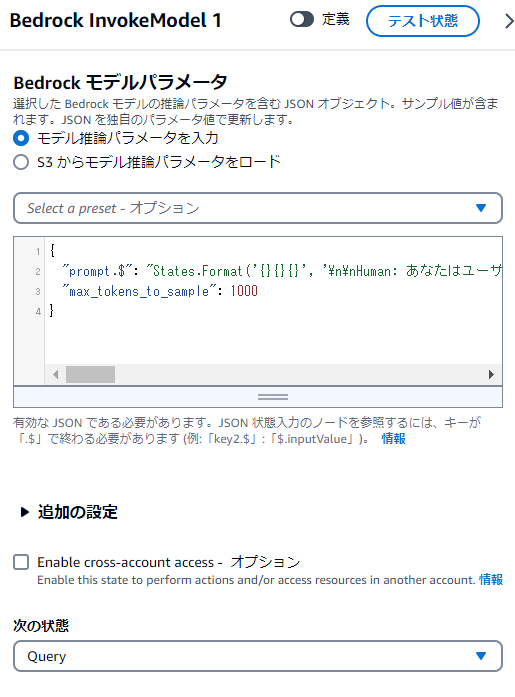
パラメータは以下です。最大出力トークンは1000も必要なかったですね。
{
"prompt.$": "States.Format('{}{}{}', '\n\nHuman: あなたはユーザーからの問い合わせから、検索ツールへの入力となる検索キーワードを考えます。問い合わせ内容に後続処理への指示(例:「説明して」「要約して」)が含まれる場合は取り除きます。検索キーワードは文章では無く簡潔な単語で指定します。検索キーワードは複数の単語を受け付ける事が出来ます。検索キーワードは日本語が標準ですが、ユーザー問い合わせに含まれている英単語はそのまま使用してください。回答形式は文字列です。\n\n<ユーザーからの問い合わせ>',$.input,'</ユーザーからの問い合わせ>\n\nAssistant: ')",
"max_tokens_to_sample": 1000
}
見易くするとこんな感じ
Human:
あなたはユーザーからの問い合わせから、検索ツールへの入力となる検索キーワードを考えます。
問い合わせ内容に後続処理への指示(例:「説明して」「要約して」)が含まれる場合は取り除きます。
検索キーワードは文章では無く簡潔な単語で指定します。
検索キーワードは複数の単語を受け付ける事が出来ます。
検索キーワードは日本語が標準ですが、ユーザー問い合わせに含まれている英単語はそのまま使用してください。
回答形式は文字列です。
<ユーザーからの問い合わせ>',$.input,'</ユーザーからの問い合わせ>
Assistant:
続いて出力タブの内容は以下
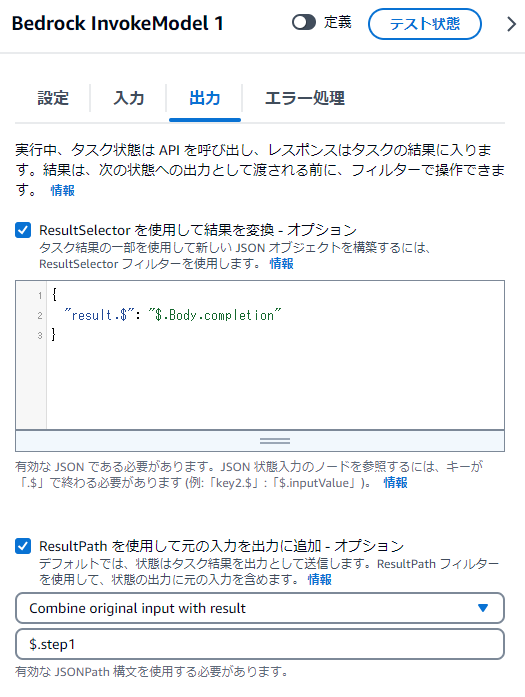
ResultSelectorは以下
{
"result.$": "$.Body.completion"
}
Claudeお決まりのcompletionを抜き出します。
ResultPathは以下
$.step1
これで$.step1.resultにBedrock実行結果が入ります。
真ん中のステップ
Kendra Rtrieveを使います。API仕様はこちら
ここまで気付かなかったのですが、StepFunctionsからはKendraのQueryAPIは呼べるものの、RetrieveAPIは呼べませんでした。1件あたり200トークン返せるRetrieveAPIに比べてQueryAPIは100トークンしか返せないので、少し残念です。
また、EqualsToパラメータで言語指定(日本語)をしようと思ったらエラーになったので、Kendraのインデックスは英語指定でクロールしてあります。
⇒ 私がパラメータを間違えてただけで正しくは言語指定できました。
設定タブの内容は以下
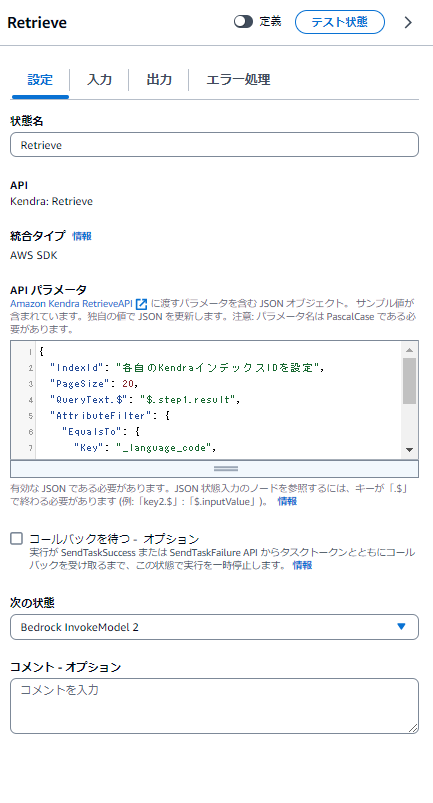
{
"IndexId": "各自のKendraインデックスIDを設定",
"PageSize": 20,
"QueryText.$": "$.step1.result",
"AttributeFilter": {
"EqualsTo": {
"Key": "_language_code",
"Value": {
"StringValue": "ja"
}
}
}
}
デフォルトでは10件なのですが、1件あたりの情報量が少ないので20件取得するようにしています。
また、QueryTextとして、最初のステップの実行結果(LLMが考えた検索キーワード)を与えています。
言語指定として日本語指定で検索するので、日本語設定でインデックスされているものが検索されます。
続いて出力タブの内容は以下
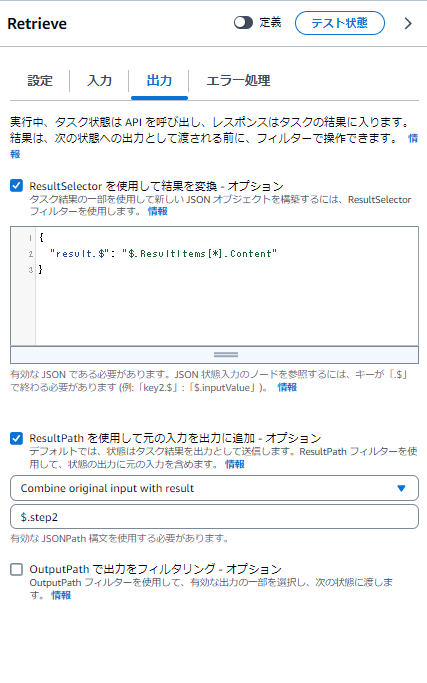
ResultSelectorは以下
{
"result.$": "$.ResultItems[*].Content"
}
配列で20件返ってくるので、ResultItemsからDocumentExcerptのText Contentのみ抜き出して20件分まるっと格納します。
ResultPathは以下
$.step2
これで$.step2.resultにKendra検索結果が入ります。
最後のステップ
Bedrock InvokeModelを使います。
最初のステップからユーザー入力を引き回し続けているので、ユーザー入力とKendraの検索結果を元に回答を生成します。
設定タブの内容は以下
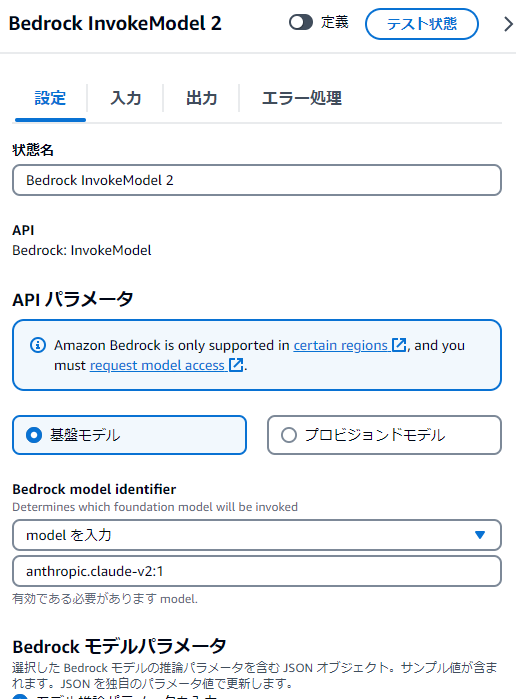
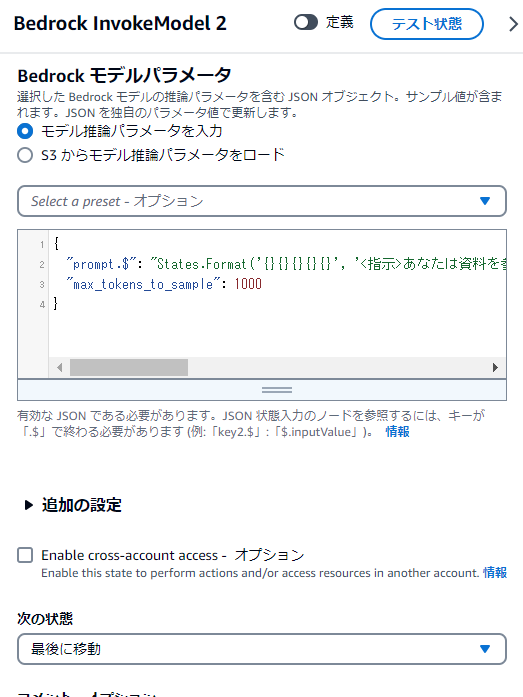
モデルはanthropic.claude-v2:1を使用しました(Instantでも良いのですがなんとなく)。
パラメータは以下です。
{
"prompt.$": "States.Format('{}{}{}{}{}', '<指示>あなたは資料を参考に質問に回答します。資料に情報が無い場合は「資料にありません」と回答します。</指示>\n<資料>', $.step2.result, '</資料>\n\nHuman: ', $.input, '\n\nAssistant:')",
"max_tokens_to_sample": 1000
}
見易くするとこんな感じ
<指示>あなたは資料を参考に質問に回答します。
資料に情報が無い場合は「資料にありません」と回答します。</指示>
<資料>', $.step2.result, '</資料>
Human: ', $.input, '
Assistant:
真ん中のステップの実行結果(Kendraの検索結果20件分)と、最初のユーザー入力をプロンプトに含めるようにしています。
続いて出力タブの内容は以下
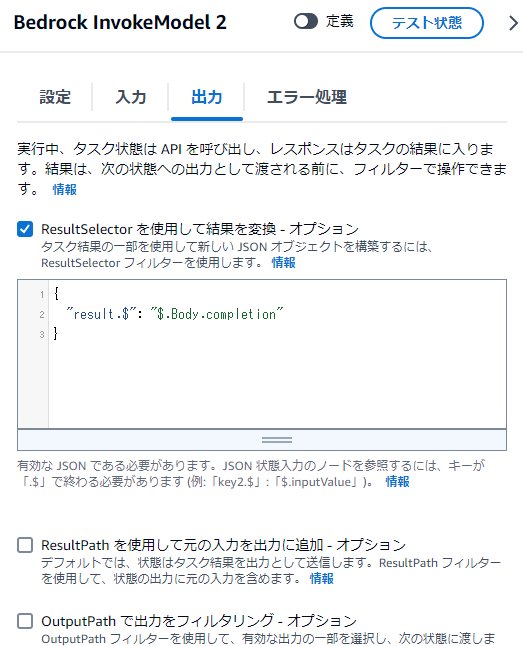
ResultSelectorは以下
{
"result.$": "$.Body.completion"
}
Claudeお決まりのcompletionを抜き出します。
これでデザイナーでの設定は終わりました。
後は保存して実行します。
最初の実行時にKendraの権限不足と言われると思うので、AmazonKendraReadOnlyAccess AmazonKendraFullAccessを付与してください。
実行してみる
KendraにはBedrockのユーザードキュメント(英語)をクロールしてあります。

最後の実行結果
資料に、Llama2のModel IDは次のとおり記載されています。
- Llama 2 Chat 13B v1: meta.llama2-13b-chat-v1:0:4k
- Llama 2 Chat 70B v1: 記載なし
- Llama 2 13B v1: meta.llama2-13b-v1:0:4k
- Llama 2 70B v1: meta.llama2-70b-v1:0:4k
よって、Llama2を使用する場合のModel IDは、使用したいモデルのサイズに応じて、
meta.llama2-13b-chat-v1:0:4k または meta.llama2-13b-v1:0:4k、あるいは meta.llama2-70b-v1:0:4k を使用します。
相変わらずなんか微妙に間違っているような気がしますが、Kendraを検索してそうです。
各ステップの入出力を見ていきます。
最初のステップ
{
"input": "BedrockでLlama2を使う場合のModelIdは?",
"step1": {
"result": " Bedrock Llama2 ModelId"
}
}
ユーザー入力をinputで受けてます。
Bedrockが考えて、検索キーワードとして" Bedrock Llama2 ModelId"を生成しています。
Bedrock側のログも見てみます。
"operation": "InvokeModel",
"modelId": "anthropic.claude-instant-v1",
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"max_tokens_to_sample": 1000,
"prompt": "\n\nHuman: あなたはユーザーからの問い合わせから、検索ツールへの入力となる検索キーワードを考えます。問い合わせ内容に後続処理への指示(例:「説明して」「要約して」)が含まれる場合は取り除きます。検索キーワードは文章では無く簡潔な単語で指定します。検索キーワードは複数の単語を受け付ける事が出来ます。検索キーワードは日本語が標準ですが、ユーザー問い合わせに含まれている英単語はそのまま使用してください。回答形式は文字列です。\n\n
<ユーザーからの問い合わせ>BedrockでLlama2を使う場合のModelIdは?</ユーザーからの問い合わせ>\n\nAssistant: "
},
"inputTokenCount": 263
},
"output": {
"outputContentType": "application/json",
"outputBodyJson": {
"completion": " Bedrock Llama2 ModelId",
"stop_reason": "stop_sequence",
"stop": "\n\nHuman:"
},
"outputTokenCount": 12
}
Bedrockの生成結果を取得出来ている事が分かります。
真ん中のステップ
{
"input": "BedrockでLlama2を使う場合のModelIdは?",
"step1": {
"result": " Bedrock Llama2 ModelId"
},
"step2": {
"result": [
"...(1件目の検索結果)...",
"...(2件目の検索結果)...",
...
"...(20件目の検索結果)..."
]
}
}
ユーザー入力を引き回すと共に、最初のステップの実行結果を元にKendraを検索して20件取得できています。
最後のステップ
{
"result": " 資料に、Llama2のModel IDは次のとおり記載されています。\n\n- Llama 2 Chat 13B v1: meta.llama2-13b-chat-v1:0:4k\n- Llama 2 Chat 70B v1: 記載なし\n- Llama 2 13B v1: meta.llama2-13b-v1:0:4k \n- Llama 2 70B v1: meta.llama2-70b-v1:0:4k\n\nよって、Llama2を使用する場合のModel IDは、使用したいモデルのサイズに応じて、\nmeta.llama2-13b-chat-v1:0:4k または meta.llama2-13b-v1:0:4k、あるいは meta.llama2-70b-v1:0:4k を使用します。"
}
Bedrockのログも見てみます。
"operation": "InvokeModel",
"modelId": "anthropic.claude-v2:1",
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"max_tokens_to_sample": 1000,
"prompt":
"<指示>あなたは資料を参考に質問に回答します。
資料に情報が無い場合は「資料にありません」と回答します。</指示>
<資料>(略)</資料>
Human: BedrockでLlama2を使う場合のModelIdは?
Assistant:"
},
"inputTokenCount": 4796
},
"output": {
"outputContentType": "application/json",
"outputBodyJson": {
"completion": " 資料に、Llama2のModel IDは次のとおり記載されています。\n\n- Llama 2 Chat 13B v1: meta.llama2-13b-chat-v1:0:4k\n- Llama 2 Chat 70B v1: 記載なし\n- Llama 2 13B v1: meta.llama2-13b-v1:0:4k \n- Llama 2 70B v1: meta.llama2-70b-v1:0:4k\n\nよって、Llama2を使用する場合のModel IDは、使用したいモデルのサイズに応じて、\nmeta.llama2-13b-chat-v1:0:4k または meta.llama2-13b-v1:0:4k、あるいは meta.llama2-70b-v1:0:4k を使用します。",
"stop_reason": "stop_sequence",
"stop": "\n\nHuman:"
},
"outputTokenCount": 234
}
}
想定通りに動いてそうです。
感想
ノーコードなRAGと言えばKnowledge baseでええやんって話なんですが、Kendraのコネクタは捨てがたいので、StepFunctions+KendraでほぼKnowledge baseと同等の事が出来る事を確認しました。
まあ出来たは出来たんですが、RetrieveAPIが使えない点が少し惜しい感じです。
StepFunctionsは思ったよりもクセ強だったので、素直にAgent⇒Lambda⇒Kendraの方が良いかも。
StepFunctionsからKendraのRetrieveAPIを使用できることが分かりましたので、Kendraを使用したRAGをノーコード(ローコード)で構築したい場合には充分に選択肢に入りそうです。