ノーコードで構築するRAGと言えばKnowledge baseがありますが、Knowledge baseはデータソースが限られる為、コネクタが豊富なKendraを使いつつ、Agents for Amazon Bedrockを使って出来るだけローコードにRAGを実現してみます。
以下のようなニーズを意識したお試しです。
- 出来るだけAWSのサービスを使ってローコードに構築したい
- Knowledge baseよりKendraを使いたい
- LangChainは使いたくない
コードとしてはKendraを検索するだけのLambda関数(実処理としては数ステップ)を1つのみ作成し、後はAgentのプロンプトでどうにかします。
作ったもの
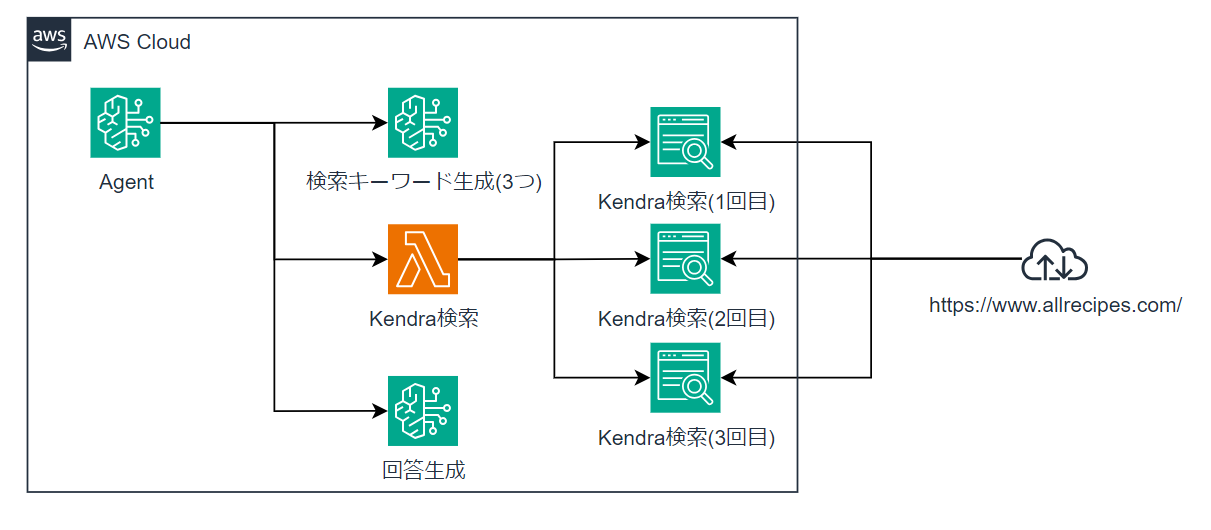
ユーザーからの質問を元に、Kendraの検索キーワードを3種類考えてもらい、1種類ずつKendra検索を行います(検索結果のバリエーションを増やす意図)。
今回は、https://www.allrecipes.com/ (英語のレシピサイト)をKendraに適当にインデックスしてあります(英語のサイトですが、日本語設定でインデックスしてあります)。それに対してAgentから検索・回答生成を行います。
作成したLambda関数
以下のLambda関数を作成します。Agentから渡された引数を元にKendraのRetrieveAPIを呼び出し(取得件数は15件)、結果をAgentに返します。
Lambdaレイヤーは不要です。
また、Lambdaの実行ロールにAmazonKendraFullAccessを付与し、リソースベースのポリシーとしてbedrock.amazonaws.comに実行権限を与えておきます。
タイムアウトは少し伸ばしておきます。
import boto3
def lambda_handler(event, context):
# 検索キーワード(query_textのvalue)を取得
parameters = event.get('parameters')
query_text = next(p for p in parameters if p['name'] == 'query_text')['value']
print("query_text: " + query_text) # 検索キーワードの出力(確認用)
# Kendra検索
kendra = boto3.client("kendra")
response = kendra.retrieve(
IndexId="各自のKendraインデックスID",
PageSize=15,
QueryText=query_text,
AttributeFilter={"EqualsTo": { "Key": "_language_code","Value": {"StringValue": "ja"}}}
)
# 検索結果から"Content"のみを全て抽出
contents = [r.get("Content") for r in response["ResultItems"]]
# agentの形式でreturn
response_body = {"application/json": {"body": contents}}
action_response = {
"actionGroup": event["actionGroup"],
"apiPath": event["apiPath"],
"httpMethod": event["httpMethod"],
"httpStatusCode": 200,
"responseBody": response_body,
}
api_response = {"messageVersion": "1.0", "response": action_response}
return api_response
Agentの作成
以下のInstructionで作成しつつ、Pre-processingを無効にします。
ModelはClaude2.1にしました。
必ずって何回言うねんって感じですが、大事な事なので何度も言いました(想定外の動作をされる度に増えていく…)
あなたはユーザーからの質問に対して3種類の検索キーワードを考えて、Functionを使用して検索して回答します。
1回の検索では充分な検索結果が得られない為、検索キーワードは異なるものを3種類考えます。様々な検索結果になるように、ユーザーからの質問を抽象化したり詳細化するなど、3種類の検索キーワードを工夫してください。
1回目の検索結果を元に2回目、3回目の検索キーワードを変更しても構いません。1回目、2回目、3回目の検索キーワードは必ず異なるものを考えてください。
3種類の検索キーワードでFunctionの呼出を必ず合計3回行います。1回目、2回目、3回目の全ての検索結果を参考に回答を考えます。回答は必ず日本語で行います。
必ず以下の処理手順を行います:
1. ユーザーからの問い合わせから、検索キーワードを3種類考えます
2. 1つ目の検索キーワードでFunction呼出しを行います
3. 1つ目の呼出し結果を元に、2つ目、3つ目の検索キーワードを再考します。1つ目の検索キーワードと必ず異なる検索キーワードを考えます。
4. 2つ目の検索キーワードでFunction呼出しを行います
5. 3つ目の検索キーワードでFunction呼出しを行います
6. 1つ目の検索結果、2つ目の検索結果、3つ目の検索結果を元に、回答を考えます。
7. 日本語で詳細に回答します。
Action groupの設定
上で作成したLambda関数を指定しつつ、「引数は英語にしてね」とくどくどとお願いします(英語のドキュメントをインデックスした為)。
openapi: 3.0.0
info:
title: Lambda
version: 1.0.0
paths:
/search:
get:
summary: Kendra Search
description: 情報を検索するツールです。このFunctionを呼び出す前に検索キーワードを考えてから呼び出します。検索キーワードには検索の後続処理への指示(例:「説明して」「要約して」)は含まないようにしてください。検索キーワードには助詞や接続詞は含まず、簡潔な単語の組み合わせを指定します。検索キーワードはスペース区切りで複数の単語を受け付ける事が出来ます。検索キーワードは英語のみ受け付けます。必ず英語にしてください!日本語では検索できません。ユーザーからの問い合わせが日本語の場合も、英語の検索キーワードを考えます。
operationId: search
parameters:
- name: query_text
in: path
description: 検索キーワード。必ず英語で指定してください
required: true
schema:
type: string
responses:
"200":
description: 検索成功
content:
application/json:
schema:
type: object
properties:
body:
type: string
動作確認

1回目:sichuan cuisine famous dishes (四川料理の名物料理)
2回目:top 10 famous sichuan dishes (有名な四川料理トップ10)
3回目:top 10 sichuan dishes (四川料理トップ10)
おおまかには期待通りに動きました。「代表的な」という言葉に引っ張られたのか、トップ10を検索しようとしています。
最終的な入力トークン数は16,275でした。
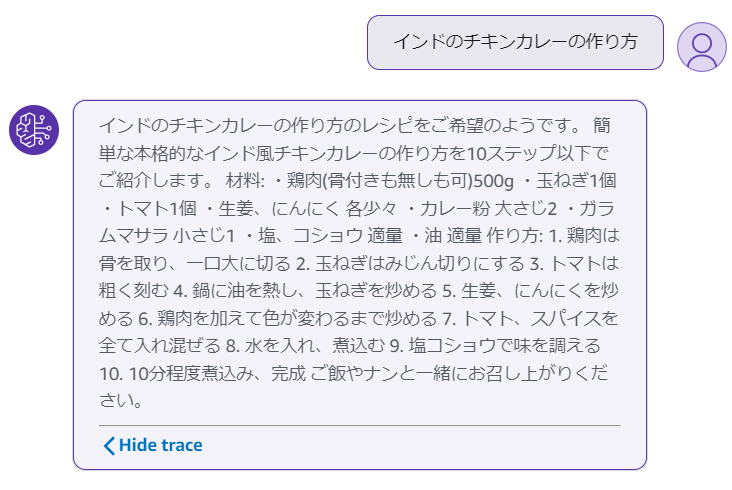
1回目:indian chicken curry recipe (インド風チキンカレーのレシピ)
2回目:authentic indian chicken curry recipe step by step (本格インド風チキンカレーのレシピをステップバイステップで)
3回目:basic indian chicken curry recipe 10 steps or less (基本のインド風チキンカレーのレシピを10ステップ以下で)
良いですね。生成された回答も良い感じです。
最終的な入力トークン数は15,154でした。
感想
Lambda関数を1つ作ればKnowledge baseとほぼ同じ使用感でRAGを構成する事が出来そうです。今回は雑に本文だけを取得していますが、実際にやる時にはURL等も引き回した方が良いと思います。
良さそうな点
- 処理全体のフレームワークとしてAgents for Amazon Bedrockを使用できる
- ライブラリとしてboto3を使うだけなので維持管理も負担が少ない
- 格納する部分(チャンク化等等)をKendraに任せられる
- 取得件数をカスタマイズできる(Knowledge baseは固定)
- Kendraはコネクタが豊富、データをS3に持ってこなくても良い
- セッション管理、チャット履歴管理をAgents for Amazon Bedrockに任せられる
もう少し良くなって欲しい点
- Kendraは1件あたりの取得トークン数が少ない(上限200トークン。knowledge baseはデフォルト300トークンで変更可能)
- ベクトル検索と比べて単語一致検索の趣が強い(気がする)
- Kendraの費用
- 期待通りに動かそうとするとプロンプトを結構頑張る必要がありそう(他の方式でも変わりませんが)。
まあ脳死でLangChainを使ったとて、プロンプトがOpenAIに最適化されてるのでBedrockで使おうとすると結局プロンプトを弄る必要があるんですよね
この方式は他の方式に比べて考える事が少ないので、クイックに作るのであれば良さそうです(めちゃくちゃ作り込むならともかく)。