前回でEmbeddingとベクトル化のイメージが掴めたので、VectorDB(Vector Store)を使ってKendraを使わないRAGを試します。
VectorDBとしてはChromaDBとやらを使います。特に拘りは無いのですがお試しなので簡単そうなもの使います。
概念図
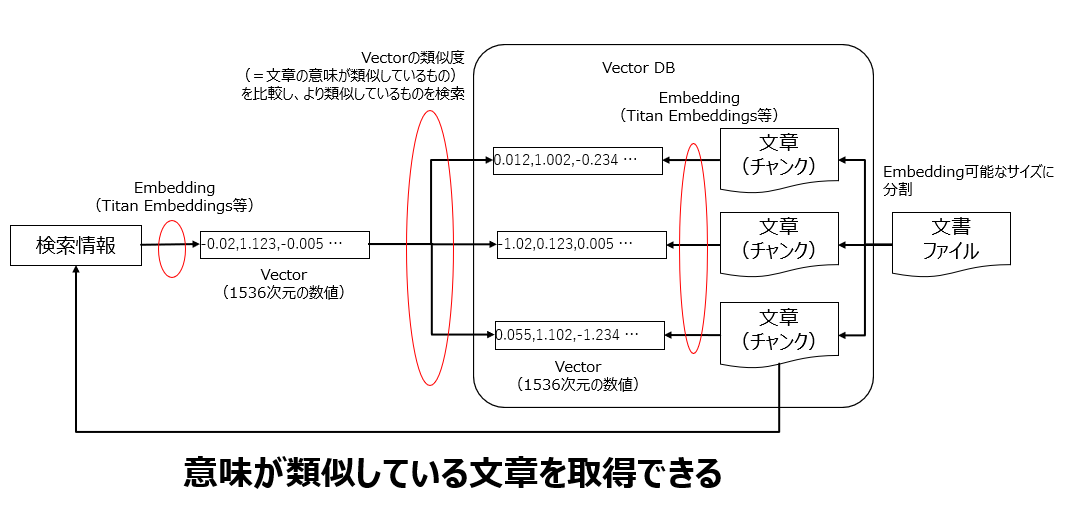
構成図
お試しなのでVectorDB(ChromaDB)はローカル端末にあります。
正確にはPDFをChromaDBに直入れしているわけではないですが。
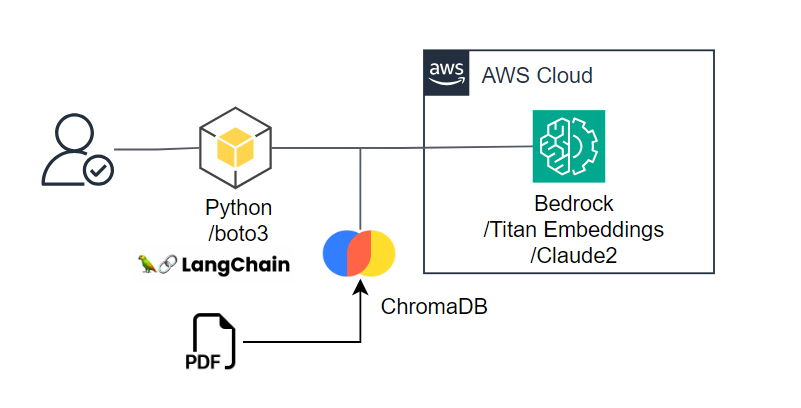
実際に使う時にはAWS上に構築するのが自然だと思います。
(ベクターなのかベクトルなのか…)
VectorDBの構築
インデックスするドキュメントとしては以下のBedrockユーザーガイド(のPDF)とKendraデベロッパーガイド(のPDF)を使います。
Kendraデベロッパーガイドの方が大幅にページ数が多いので、検索ノイズが多い中でBedrockの情報が正しく検索できるかを確認します。
ちなみにBedrockユーザーガイドは日本語がアレな感じです。
上記のPDFファイルをローカル環境のどこかに置いておきます。
以下のライブラリを追加でインストールしておきます。
pip install -U chromadb
pip install -U pypdf
ローカル環境にChromaDB用のフォルダを適当に作っておきます。
以下のプログラムでVectorDBを構築します。
persist_pathは各自のローカル環境のChromaDB用フォルダに置き換えてください。
PyPDFLoaderに渡しているPDFファイルの場所も、各自のローカル環境に配置したPDFファイルのパスに置き換えてください(x2)。
from langchain.embeddings import BedrockEmbeddings
import chromadb
from langchain.vectorstores import Chroma
from langchain.document_loaders import PyPDFLoader
# Embeddingsの定義
embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v1")
# ChromaDBの定義
persist_path = 'c:\Python\Embedding\chroma' #場所
client = chromadb.PersistentClient(path=persist_path)
db = Chroma(
collection_name="vector_store",
embedding_function=embeddings,
client=client
)
# PDFファイルをChromaDBに追加
loader = PyPDFLoader(r"c:\Python\Embedding\PDF\bedrock-ug.pdf")
pages = loader.load_and_split()
db.add_documents(documents=pages, embedding=embeddings)
loader = PyPDFLoader(r"c:\Python\Embedding\PDF\kendra-dg.pdf")
pages = loader.load_and_split()
db.add_documents(documents=pages, embedding=embeddings)
上記のプログラムを実行すると、PDFファイルが(多分)ページ単位にチャンク化されてTitan EmbeddingsによってVector化され、ChromaDBに格納されます。
RAGの構築
検索内容のEmbeddingとしてはVectorDBと同じTitan Embeddingsを使用し(そりゃそうですが)、最後の文章整理についてはClaude2を使用します。
実行しやすいようにStreamlitでガワを被せています。
persist_pathは各自のローカル環境のChromaDB用フォルダに置き換えてください。
from langchain.embeddings import BedrockEmbeddings
import chromadb
from langchain.vectorstores import Chroma
from langchain.llms import Bedrock
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
import streamlit as st
# Embeddingsの定義
embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v1")
# ChromaDBの定義
persist_path = 'c:\Python\Embedding\chroma' #場所
client = chromadb.PersistentClient(path=persist_path)
db = Chroma(
collection_name="vector_store",
embedding_function=embeddings,
client=client
)
# LLMの定義
llm = Bedrock(
model_id="anthropic.claude-v2",
model_kwargs={"max_tokens_to_sample": 1000},
)
# promptの定義
prompt_template = """
<documents>{context}</documents>
\n\nHuman: 上記の内容を参考文書として、質問の内容に対して詳しく説明してください。言語の指定が無い場合は日本語で答えてください。
もし質問の内容が参考文書に無かった場合は「文書にありません」と答えてください。回答内容には質問自体やタグは含めないでください。
Take a deep breath and work on this problem step-by-step.
<question>{question}</question>
\n\nAssistant:"""
PROMPT = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
chain_type_kwargs = {"prompt": PROMPT}
# Chainの定義。検索結果の上位15件を使用
qa = RetrievalQA.from_chain_type(llm,retriever=db.as_retriever(search_kwargs={"k": 15}),chain_type_kwargs=chain_type_kwargs)
# Streamlit
st.title("VectoRAG")
input_text = st.text_input("入力された文字列でVectorDBを検索し回答します")
send_button = st.button("送信")
if send_button:
# 実行
st.write(qa.run(input_text))
プロンプトについては定義しなくてもLangChainのデフォルトで動くのですが、ときどき英語になったり挙動不審なのでプログラム内で上書きしています。
プロンプトの書き方は毎回気分で少し違いますが大きな意味はありません。
また、とりあえずですが文章は15件(PDFの状態で15ページ)取得するようにしています。質問内容と意味の近いものが15ページ取得されるのが期待値です(全量だと1000ページ近くあるので、1000ページ中の15ページが取得される)。
上記のプログラムをStreamlitから実行します。
python -m streamlit run titan_search.py
動作確認
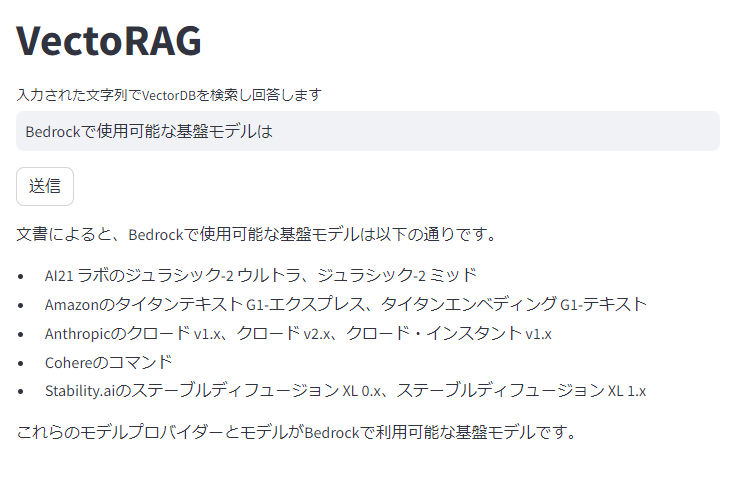
素のClaude2が知らないBedrockについて聞いてみます。
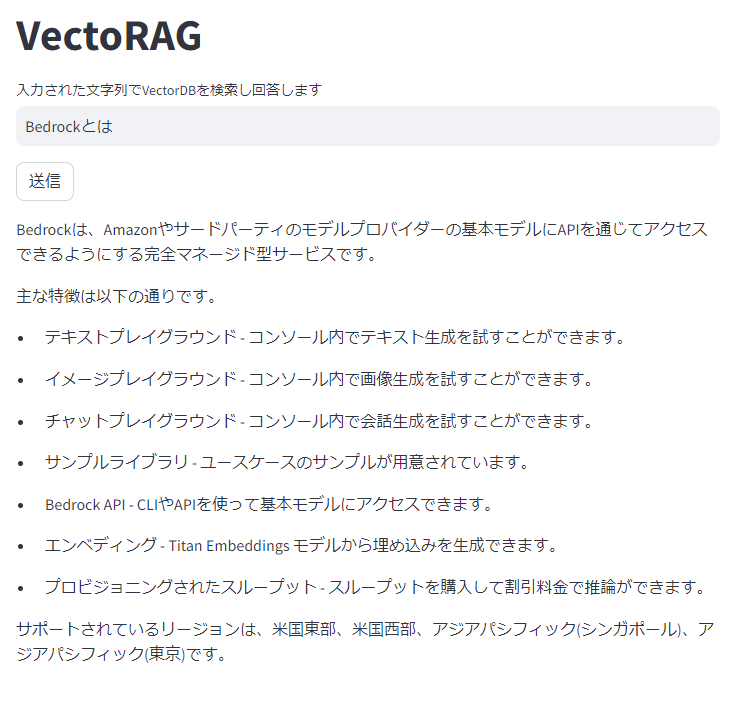
ちゃんとVectorDBから値を取得してくれてそうです。
CloudWatch Logsから、Bedrockに渡されているプロンプトを確認してみます。
"operation": "InvokeModel",
"modelId": "anthropic.claude-v2",
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"max_tokens_to_sample": 1000,
"prompt": "\n <documents>Amazon Bedrock ユーザーガイド\nBedrockユーザーガイドのドキュメン\nト履歴\n•ドキュメントの最新更新日:2023 年 8 月
・・・
うことがで\nきます。\n22</documents>\n \n\nHuman: 上記の内容を参考文書として、質問の内容に対して詳しく説明してください。言語の指定が無い場合は日本語で答えてください。\n もし質問の内容が参考文書に無かった場合は「文書にありません」と答えてください。回答内容には質問自体やタグは含めないでください。\n Take a deep breath and work on this problem step-by-step.\n <question>Bedrockとは</question>\n \n\nAssistant:"
},
"inputTokenCount": 13047
},
"output": {
"outputContentType": "application/json",
"outputBodyJson": {
"completion": " Bedrockは、Amazonやサードパーティのモデルプロバイダーの基本モデルにAPIを通じてアクセスできるようにする完全マネージド型サービスです。\n\n主な特徴は以下の通りです。\n\n- テキストプレイグラウンド - コンソール内でテキスト生成を試すことができます。\n\n- イメージプレイグラウンド - コンソール内で画像生成を試すことができます。\n\n- チャットプレイグラウンド - コンソール内で会話生成を試すことができます。\n\n- サンプルライブラリ - ユースケースのサンプルが用意されています。\n\n- Bedrock API - CLIやAPIを使って基本モデルにアクセスできます。\n\n- エンベディング - Titan Embeddings モデルから埋め込みを生成できます。 \n\n- プロビジョニングされたスループット - スループットを購入して割引料金で推論ができます。\n\nサポートされているリージョンは、米国東部、米国西部、アジアパシフィック(シンガポール)、アジアパシフィック(東京)です。",
"stop_reason": "stop_sequence",
"stop": "\n\nHuman:"
},
"outputTokenCount": 390
}
地道に、<documents>タグの内容をPDFファイルと見比べてみました。
以下の順で<documents>に含まれていました。15ページ取得される想定でしたが14ページ分しか特定できませんでしたが、まあそこは気にしない事にします(見落としたんだと思います)。
P.144, 目次の一部(頁の途中まで), P.15, P.13, P.91,
目次の先頭(ページの途中まで), P.14, P.33, P.1, P.19,
P.3, P.18, P.36, P.22
このうち、P.1の以下2カ所と、


P.3の以下あたりを抜粋してまとめてくれたようです。

わかったこと
- 目次のページは文字数が多すぎる(トークン数が多すぎる)からか途中で切れている
- それ以外のページはページ単位で渡されている(=ページ単位でチャンクされてそう)
- 設問が単純だからか、関係ないページも結構検索されている
- ページ単位で順不同で取得されているので、ページを跨る記載は読めなそう
- PDFのレイアウトの影響(改行等)を受けている。プロンプトで補正させても良いかもしれない?
- LLMは文字列しか読めないので、当たり前だが表形式の構造等は失われる
- 今回の例で言うと15件程度は取得した方が良さそう
- KendraのPDFファイルは取得されなかった
- 入力トークン数は
13047なので、GPT-3.5であれば入らない量 - 入力トークン数を料金にすると20円程度
ありもののPDF資料でクイックにRAGを実現するというレベルでは充分に動いてそうです。
一方で、PDFのレイアウトの影響(改行、改ページ、表等)を受けるので、精度を向上させたい場合には少し工夫が必要そうです。チャンクを作る時にページで分割せずに大きめのトークン数で分割した方が良いかもしれません。
概ね期待通り動いてそうなので、後は画面から幾つか試してみます。
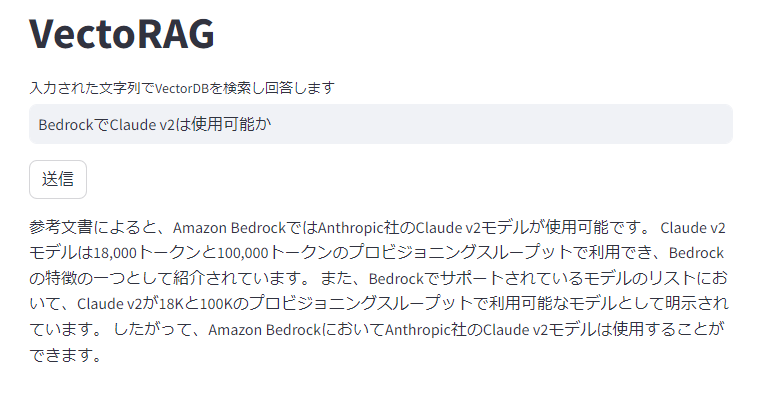
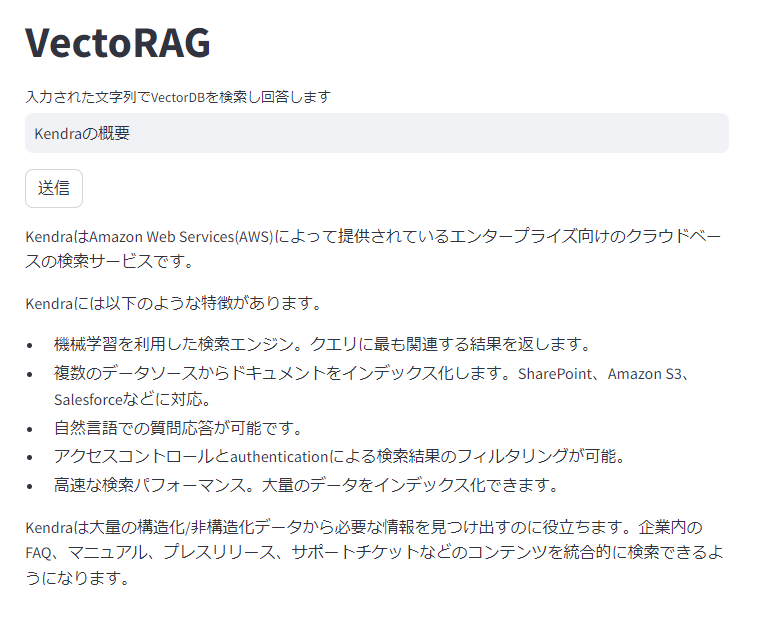
最後のケースについて同様にCloudWatch Logsを確認したところ、Bedrockという単語は含まれておらず、Kendra デベロッパーガイドが多数取得されていたので、期待通りに動いてそうです。
ちなみに入力トークン数は8940でした。