前置き
2023年Advent Calendar集まれ文系エンジニア!1日目の投稿です。
私はこれまでに2冊の技術書を執筆し、現在はSoftware Designという雑誌でMLOpsに関する記事を毎月連載(2023年8月号〜)しています。
- AIエンジニアのための機械学習システムデザインパターン(翔泳社)
- 現場で使える!機械学習システム構築実践ガイド デザインパターンを利用した最適な設計・構築・運用手法(翔泳社)
- ソフトウェアデザイン2023年12月号(技術評論社)
いずれの本も出版社から出していて、執筆にあたって編集者にご協力いただいています。この場を借りて御礼申し上げます。
漫画や小説を出版する流れを書いた作品は多々ありますが、技術書を書くことについてまとまった記事は多くない印象です。本記事では技術書を書くことについて、私の経験した手順や知見を共有します。
なお、私は自費出版の経験はないので、そちら方面は経験したら後日書くかもしれません(書かないかもしれません)。
本記事の対象読者
本記事は将来的に技術書を執筆して出版したい方へ、私の知見や経験を伝えることを目的としています。
本を書くのは大変です。1冊を書くのに構想から出版まで1年程度の期間を要しますし、書いた内容が世の中の役に立ち、好評価を得られるとは限りません。しかも頑張って書いた本の内容がすぐOut of dateになることもあります。本を出版した同月に使っていたライブラリがDeprecatedになったり、「チャットボットを作るときは機械学習を使うよりも、まずはルールベースで作ったほうが良い」と書いた本を出したのと同じタイミングでChatGPTが公開されるという不運に見舞われることもあります。
それでも私が本を書いて出版するのは、自分特有の経験に裏打ちされた知見や技術を伝え、世の中をより便利にしたい(あと自慢したい)というモチベーションがあるからです。私が駆け出しのインフラエンジニアだった頃に感銘を受けた本に『クラウドデザインパターン』があります。2015年頃のAWSを用いたシステム設計・構築のベストプラクティスを整理した名著で、それまで散らばっていたクラウドを用いたシステムの設計指針やノウハウが詰まった一冊でした。クラウドデザインパターンはもともとはWikiで公開されたものが編集され、本として再編成されたものになります。Wiki版クラウドデザインパターンが公開されたときの衝撃は今でも忘れられません。いつか私も、自分が得た他にない知見を世の中に出したいと強く思ったものです。
モチベーション
私は大学、大学院(修士)と文学部でイギリスの歴史を研究していました。ソフトウェアエンジニアになったのは就職してからです。大学時代は歴史の研究者になるのが目標だったのですが、自分にその才能がないことや、文学系研究者の世知辛い実情を知り、諦めました。ソフトウェアエンジニアになったのは偶然で、新卒で唯一内定をいただいたのが日本のSIerだったからです。
大学時代に限らず本を読むのは自分の生活の一部です。文学系の学部に進学し、研究者を目指したのは自然な流れだと当時は思っていました。しかし本ばかり読んでいても文学系の研究では成功できない(もちろん研究で文章を読むことは作業の大きな割合を占めるのですが、アウトプットすることは別物ですし、生計を立てるのは更に別次元です)と深く自覚したのが大学院時代でした。それでも私の人格が文字という手段、本というメディアに拘泥して作られてきたことは否定しようがなく、いつか自分の中にある特有のものを本として世に問いたいと夢に抱いていました。技術書を出版できたのはその夢が叶った瞬間です。
私にとって良い作品とは、作者独自の他にない知見や経験を表現するものです。自分にしか書けない個別的で重要なことこそ、読む人の心を揺さぶるものがあると思っています。もちろん一般的なノウハウや汎用的な知識を書く本が重要ではないと言うつもりはありません(実際、どんなテーマについても世の中の大多数の人は初心者であり、初歩的で一般的な内容のほうが需要はあるでしょう)。しかしそれは自分でなくても書けるし、しかも現在であればAIに書いてもらえば良いものです。自分特有の真理を自分にしか表現できないストーリーとして表出するからこそ価値があり、応用的な技術書を書くという費用対効果の微妙な大仕事に没頭することができるのだと思います。
技術書を書く前に
出版社と企画
技術書を出版するためには出版社が必要です。自費出版でもない限り、本は出版社で企画が承認された後から書き始めます。
私が一冊目の『AIエンジニアのための機械学習システムデザインパターン』を執筆したとき(2020年〜2021年)は、最初に編集者からSNS経由でお声がけいただきました。当時私が登壇したPyCon JP 2020と、GitHubで公開したMachine learning system design patternを編集者が発見したのがお声がけのきっかけだったそうです。編集者とはそれから1度オンラインでミーティングしました。そこで私に執筆する意志があることを伝え、内容をざっくり整理し、執筆のおおまかな手順を教わりました。その後、技術書の目的を整理して目次を作成し、それをもとに出版社側で社内で技術書の企画について承認を得て、ようやく執筆者に正式に依頼するという流れになります。このタイミングで出版スケジュールや出版部数、価格、印税率を決めます。
当初の企画書と目次は以下のようなイメージになります。


本は目次から書く、というプラクティスは巷でよく提唱されているものです。実際に目次をベースにして各章を執筆していくと、「ここでこれを書くけどこれは書かずにあっちで書く」という内容の選別が自然と判断でき、助けられました。現在連載しているソフトウェアデザインのMLOpsの連載も目次から書いていくスタイルを続けており、毎回締め切り前には原稿を上げられるペースで書いています。
本の内容
漫画や小説とかだと作品を持ち込んだり新人賞に応募したりするのかもしれません。技術書でも、テックブログや公開ドキュメントとして書き溜めたものを推敲して出版することもあるでしょう。
私の一冊目はMachine learning system design patternが公開ドキュメントそのもので、執筆内容はある程度イメージできるものになっていました。
全編を書き始める前に、1節だけ(機械学習システムデザインパターンの1つだけ)執筆して、編集者のレビューをいただいています。執筆者と編集者で方針や書き方について、具体的な文章で合意が取ることが目的です。この時点で以下のことを決めています。
- 1節(1パターン)の流れは前置き、課題、パターン、具体例、メリット、デメリットにすること。
- 「ですます調」で書くこと。
- サンプルコードを本文に含めること。サンプルコードの全編はGitHubレポジトリに用意し、本文にはGitHubのURLを明記すること。
- 図はpngで作ること。
- 初稿はマークダウンで書き、GitHubで管理するが、第2稿以降のレビューは組版で行うこと。
一冊目は機械学習システムデザインパターンをまとめた内容になるため、各パターンの書き方を統一することが重要と考えていました。最初に構成を決めることで、各パターンで書かなければならないことが明確になり、執筆がやりやすかった覚えがあります。
また、各パターンの実装コードをGitHubで公開することで合意しました。私の当時の問題意識として、機械学習を実用化することを謳う記事や本は多々あれど、それを実際に実装して構築して見せているものは皆無に等しく、これでは実践的なスキルが伝わらない思いがありました。名著と言われる『テスト駆動開発』にしても『Java言語で学ぶデザインパターン入門』にしても、サンプルコードは豊富に用意されており、考え方と同時にスキルを学ぶことができる内容になっています。同じことを目指した結果、各機械学習システムデザインパターンの動く実装を書くことにしました。
初稿をマークダウンで書いてGithubで管理したのは私にとって楽だったからです。人によってはGoogle DocsやMicrosoft Wordsで書いても良いでしょう。ただし、初稿以降の原稿は組版で作られたPDFをレビューし、修正することになるので注意が必要です。
技術書を書く
執筆作業は主に平日の夜か休日に進めました。一冊目のときも二冊目のときも、私は本業でフルタイムで働きつつ、副業約2件でソフトウェア開発の業務委託を受けていたので、その合間に時間を取って執筆しました。
一冊目『AIエンジニアのための機械学習システムデザインパターン』

一冊目の執筆スケジュールは以下のような感じったと思います。
- 2020年9月くらいに編集者から連絡がきて、企画。
- 10月くらいに執筆開始。
- 12月の年末年始休暇にサンプルコードを書き切る。
- 2021年の1月くらいに初稿を提出。
- 2月、3月で第1版、第2版、第3版、第4版のレビューおよび修正。
- 4月くらいにFix。
- 5月のゴールデンウィーク明けに出版。
本当はゴールデンウィーク前に出版したかったのですが(編集者曰く、ゴールデンウィーク前のほうが売れる)、間に合いませんでした。しかし一冊の技術書を半年程度で書き終えたのはだいぶ早いペースだったらしいです。一冊目は前述のとおり、事前に書いて公開していたMachine learning system design patternがあったので、だいぶ楽できたと思います。また、サンプルコードも個々のデザインパターン向けに書くだけで良かった(それぞれを繋げる必要がなかった)ため、難易度は低かったです。それでも2020年の年末年始は本の執筆作業で潰れたので、本を書くのは楽ではありません。
本書は7章&「はじめに」と「おわりに」という構成になっています。執筆順は、第4章、第5章、第6章、第1章、第2章、第3章、第7章、はじめに、おわりに、という順番でした。奇しくもスターウォーズの上映順と同じになったのは偶然です。第4章「推論パターン」から書き始めたのは、私にとって書きやすかったからです。また、第4章のために書いたサンプルコードは他の章でも修正して流用するつもりだったので、最初に終わらせておく必要がありました。第7章とはじめに、おわりにを最後に残したのは、いずれも全編書き終わった後で総括したかったためです。最終的にこの書き順は成功したと思います。
編集者には各章を書くごとに提出していました。組版は章ごとに個々に作成していただき、全編描き終わるまで組版が出来上がらないことを回避しました。組版とは文章やサンプルコード、図を本当の書籍形式で組んだファイルです。本のレビューはマークダウンにGitHubでコメントするのではなく、組版(PDF)に赤入れする形式で行います。実際の書籍を修正していくようなイメージです。
以下は実際の初稿原稿から組版を作成して、大量の誤字脱字や表現の修正しているものです。

組版が出来上がったタイミングで外部のエンジニアにサンプルコードの稼働確認をしていただきました。自分で書いたプログラムが自分以外の環境でも動くことをレビューいただきます。そのためにはサンプルコードを格納したGitHubにそれぞれの実行方法を解説する必要があります。プログラムの稼働環境を汎用化するため、インフラはDockerとKubernetesを活用しました。DockerレジストリにPushしたDocker Imageをダウンロードして起動すれば良い形式にすることで、稼働環境構築を簡易化しています。サンプルコードを提供する以上、そのサンプルが動く必要があります。DockerとKubernetesで汎用的に環境を定義できるのは便利でした。
同じタイミングでエンジニアの知人に本文のレビューを依頼しました。本文のレビューは大体1ヶ月程度の期間で全文をレビューいただくというもので、だいぶハードスケジュールだったと思います。組版にしてわかったことですが、本書は400ページを超える分厚いものでした。サンプルコードおよび本文をレビューいただいた皆様には頭が上がりません。
誤字脱字のチェックや文章の推敲は出版社が組版に赤入れしてくれました。サンプルコードおよび本文レビューの反映修正は第1版で私が書き込みます。修正された組版(第2版、第3版、第4版)をもとに更に誤字脱字を直して文章を推敲する、というプロセスを数回繰り返します。その間に文言を統一したり、章立てを組み換えたり、サンプルコードをわかりやすく書き直したりします。自分の書いた文章を何度も読むのですが、そのたびに修正事項が見つかります。最後は諦めが大事です。
第2稿、3稿、4稿で以下のように出来上がっていきます。
-
第2稿

-
第3稿

-
第4稿

書いた!出版した!
『AIエンジニアのための機械学習システムデザインパターン』の最終版を提出したのは2021年4月の初めくらいだったと思います(たぶん)。ゴールデンウィーク頃に贈呈本が10冊ほど届き、書店に並んだのが5月中旬でした。見本は執筆にあたってお世話になった方々や両親、母校に贈りました。自分の書いた本が書店に並んでいる姿に感動しました。

印税は6月と12月に振り込まれたはずです。ありがたいものです。
二冊目『現場で使える!機械学習システム構築実践ガイド デザインパターンを利用した最適な設計・構築・運用手法』

一冊目を書いた当初から二冊目を書くつもりでした。これは技術書を書くモチベーションとなった『クラウドデザインパターン』が2部構成(設計編と構築編)だったため、私も同じ構成にすることを念頭に一冊目を書いていました。
一冊目を書いたときは編集者から企画の依頼がありましたが、二冊目は私からの持ち込みとなります。と言っても私がやったことは、編集者に書きたい旨と目的、おおまかな内容、目次構成を提出しただけで、出版社の企画会議は編集者が通してくれました。編集者が売れると思ったかどうかは定かではないですが、私のわがままに付き合ってくれてありがたいものです。
技術書を書く手順は一冊目で学んでいたのですが、一冊目と違って書き溜めがなかったので、すべて0から書き始めることになります。執筆期間も一冊目より二冊目のほうが長くなりました。大体のスケジュールは以下のような感じでした。
- 2021年6月くらいに編集者に企画を送る。
- 8月くらいに編集者とミーティング。
- 9月に企画が通って執筆開始。
- 年末年始にサンプルコードを書きまくる。第2章需要予測システムのサンプルコードと原稿を書き切る。第3章、第4章のスマホアプリシステムはサンプルコードを途中まで作る。
- ゴールデンウィークに原稿とサンプルコードを書きまくる。第3章、第4章のサンプルコードを書き切る。
- 2022年5月くらいに初稿完成。
- 6月〜10月にレビューと修正。
- 11月に出版。
一冊目が半年くらいで完成したのに対し、二冊目は企画から出版まで1年半近く要しています。これは書き溜めがなかったことだけでなく、当時の私が何故か機械学習を活用したシステムをエンドツーエンドで作るという企画にしていたからです。エンドツーエンドというのは、Androidアプリ、バックエンドのWeb API(FastAPI)、学習パイプライン(ワークフローエンジンはArgo Workflows)、モデル管理(MLflow)、学習済みモデルのデプロイ自動化(Argo Workflows)、推論API(TensorFlow Serving等)、評価のためのBI(Streamlit)、検索システム(ElasticSearch)、メッセージング(RabbitMQ)、キャッシュ(Reddis)、データベース(PostgreSQL)、インフラ(Kubernetes、Prometheus、Grafana)、データアノテーション(手動)をすべて含みます。
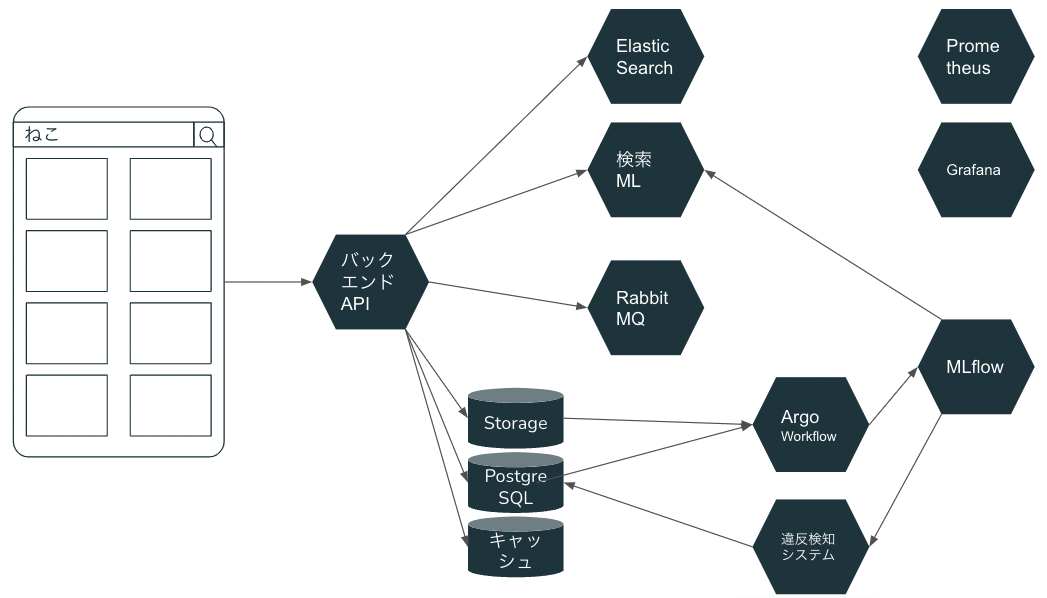
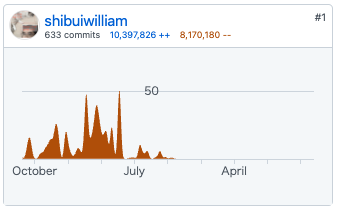
普通に本番サービスを作りきるのと同じレベルでシステムを構築しました。本当はモデル監視やドリフト検知やログ基盤も作るつもりだったのですが、途方もなくなったので諦めました。GitHubに記録されているコミットされたコード行数は10,397,826++ 8,170,180--ですーー技術書といえど、1冊の本だけのために実装するレベルのシステムではありません。今後技術書を書く皆様は絶対に真似しないよう、ご注意ください。
そんなこんなで二冊目は年末年始休暇とゴールデンウィークを潰して書ききり、どうにか2022年11月に出版しました。
本を書いて得られたもの
技術書を2冊出版して得られたものは多々あります。
外面的には自分の名刺代わりに著作を紹介したり、機械学習システムデザインパターンや機械学習システム構築実践ガイドの著者と自己紹介することができるようになったことです。私のことは知らなくても著書を知ってくれている方は意外と多く、技術者どうしの初対面でも著書のことを伝えるだけで、自分の技術的バックグラウンドを知ってくれていて、コミュニケーションがスムーズになります。あとちょっとチヤホヤされます。
内面的には、技術書を読むときに目をつける箇所が変わりました。技術書を読む目的は多くの場合、その中に書いてある技術的なノウハウやスキルを知り、身につけることだと思います。そのため、効率的に読む場合は、必要な箇所を掻い摘んで読むか、全編通して読むにしてもナレッジになる箇所を優先して読みます。言い換えると、冒頭の紹介や最後のまとめみたいな箇所は読み飛ばすことが多いです。しかし自分で技術書を書いてみて一番苦労したのは冒頭と最後の締めでした。それぞれで著作のレゾンデートルというか、なぜわざわざこの本を書いて、それが世の中にどういう意味があるのか、説明する必要があります。技術書を書く意味やその本が世の中に必要とされる理由は、著者が論じない限り、世の中に発表されません。頑張って書いた本の存在価値を示すために書く冒頭と最後は、自分の中にある曖昧な熱意を文字に起こしているような気分で、だいぶ大変でした。いずれも数回書き直したはずです。そうした苦労もあり、技術書を読むときは冒頭からちゃんと目を通して著者の思いを追うようにしました。逆に、冒頭で著作の存在価値を示していない著作は読まないことにしました。
まとめ
というわけで、私が技術書を書いた経験談でした。まとまりない気がしますが、技術書を書いて出版するまでの流れは大まかに伝えられたと思います。将来的に技術書を書きたいという思いのある方の参考になると幸いです。