Kerasのモデルは学習完了時のものが最良とは限らない
ちょっとしたTipsです。
Kerasの限らず、ディープラーニングで作ったモデルは学習完了時のものが最良とは限りません。
学習を進めていって全エポックを終了したとしても(またはEarlyStoppingしても)、過学習であったり局所最適化されてしまったりということがありえます。
学習の途中に最良のモデルが存在するけど、学習完了時はそれより劣る、ということです。
そうした場合はCheckpointで保存された最良のモデルをロードし直すのが良いと思います。
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
from keras.callbacks import EarlyStopping, ModelCheckpoint
import os
baseSaveDir = "./mnist/"
if not os.path.isdir(baseSaveDir):
os.makedirs(baseSaveDir)
batch_size = 128
num_classes = 10
epochs = 10
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
es_cb = EarlyStopping(monitor='val_loss', patience=2, verbose=1, mode='auto')
chkpt = os.path.join(baseSaveDir, 'MNIST_.{epoch:02d}-{val_loss:.2f}.hdf5')
cp_cb = ModelCheckpoint(filepath = chkpt, monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test),
callbacks=[es_cb,cp_cb],
shuffle=True)
上記の実行結果は以下で、初回のエポックで最良のモデルができてしまい、その後のエポックでは検証データのLossが改悪されています。
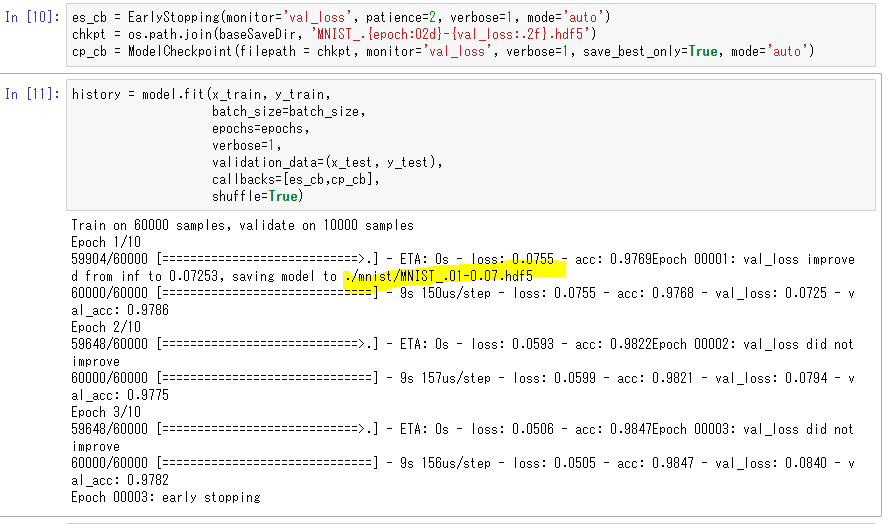
しかし、学習完了後のmodelは最新の重みを持っているため、最良のモデルにはなっていません。
# get the newest model file within a directory
def getNewestModel(model, dirname):
from glob import glob
target = os.path.join(dirname, '*')
files = [(f, os.path.getmtime(f)) for f in glob(target)]
if len(files) == 0:
return model
else:
newestModel = sorted(files, key=lambda files: files[1])[-1]
model.load_weights(newestModel[0])
return model
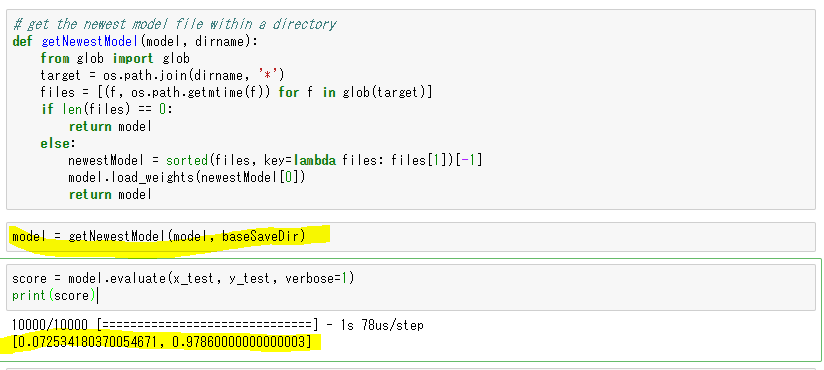
model = getNewestModel(model, baseSaveDir)
score = model.evaluate(x_test, y_test, verbose=1)
print(score)
getNewestModel()では、CheckPointで保存された最新のファイルをロードします。
CheckPointでは最良のもののみが保存されていくので、最新のファイルを最良としています。
もちろん最新のファイルではなく、ファイル名からloss値をパースして比較する、ということでも良いと思います。
Kerasアドベントカレンダー2017 完了!
投稿日は前後しましたが、なんとかKerasアドベントカレンダーを埋めることができました。
ご投稿、ご購読いただいた皆様、ありがとうございました!