12月10日の2022ソフトウェアテストアドベントカレンダーです。
Launchable社でエンジニアとして働いているcvuskと申します。機械学習界隈では機械学習を実用化するためのシステム開発の本を書いてたります。もし良かったら読んでみてください。
『機械学習システムデザインパターン』
『機械学習システム構築実践ガイド』
本ブログでは機械学習を用いてテスト実行を効率化する手法として、Predictive Test Selectionについて説明します。テスト実行時間やコストで課題を抱えているエンジニアに役に立つと幸いです。
昨今の開発におけるテスト事情
2002年に『テスト駆動開発』が世に出て、ソフトウェア開発でテストを書くことが常識になって早20年が経っています。その間にクラウドの登場やDevOpsの普及により、テストをCI/CDパイプラインで自動実行し、コードとプロダクト品質を維持するプラクティスが確立してきました。テストにはユニットテストからインテグレーションテスト、システムテスト等が含まれます。PRを作ってApproveする条件として、必要なテストケースを書き、すべてのテストが通過していることを定めているレポジトリやプロジェクトも多いでしょう。
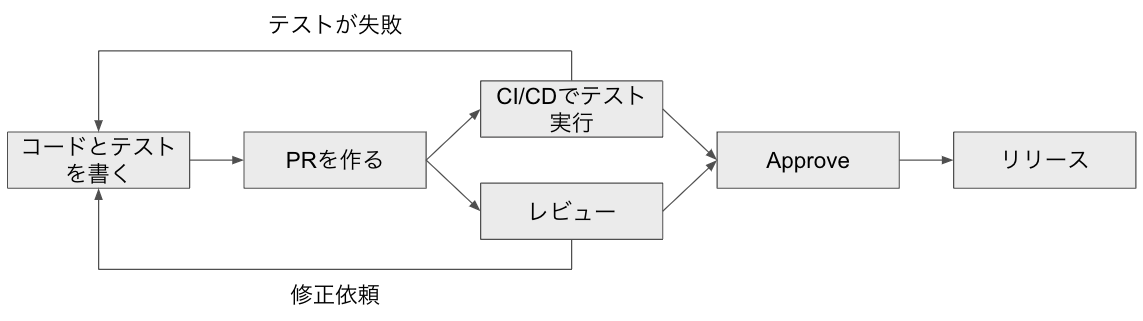
これらに加えて、最近だとソフトウェアの全レイヤーをユーザのユースケースを想定してテストするEnd-to-endテスト(E2Eテスト)も流行っています。特にフロントエンド等のUIがあるサービスだと、従来のユニットテストやインテグレーションテストだけでなく、E2Eテストを導入し、ユーザの画面利用含めてプロダクトをテストするのは当然となっているのではないでしょうか。
CI/CDは古くはJenkinsのようなユーザが構築する基盤で実行していました。最近ではGitHub ActionsやCircleCIのような単独サービスや、AWS CodePipelineやAzure Pipelinesのようなクラウドサービスが提供されています。その他にもE2Eテストの実行管理環境としてmablやautifyがあります。ソフトウェアを開発する(テストを書くことを含む)作業はローカルの開発端末で実施することが多いでしょう。他方で、テスト実行は無償・有償のクラウドでの自動実行環境に寄ってきているように思われます。
サービスの規模が拡大してコード量が増加すれば、その分テスト量や種類も増えていきます。特に長く運用しているサービスだと、デッドコードが増えるのと同じ要領で、相応にテストケース数が増えます。いつ書かれたのかわからないテストや、何を検証しているのかわからないテストケースも増えてくるでしょう。こうした事態は2つの点で開発生産性を下げます。
- 不要なテストを実行することによるCI/CDの待ち時間と費用
- 不要そうなテストをメンテナンスする人件費とモチベーション
CI/CDがクラウド等のサービスで実行されるようになった結果、「1. 不要なテストを実行することによるCI/CDの待ち時間と費用」が発生し、テストの実行や維持は無償ではなくなっています。テストの実行待ち時間はエンジニアがPRを修正またはマージするための待ち時間となります。待ち時間が短ければすぐ改善し、価値のあるプロダクトを素早くユーザに届けることができるでしょう。テスト実行時間を短くするためにCI/CDでのテスト実行を並列化したりリソースを増強したりしますが、そのためにはCI/CDのサービスに課金する必要があり、その多くは時間課金です。プロダクトが成長しソフトウェアの規模が増大すると、テストの実行時間と開発効率が下がる(または費用が増える)関係にあります。
「2. 不要そうなテストをメンテナンスする人件費とモチベーション」は更に厄介です。テストの多くは当初は意味があって書かれたはずですが、ソフトウェアが変化していくにつれ、不要になるテストも発生してくるでしょう。しかしどのテストが不要かどうかということはソフトウェアとプロダクトの仕様を解読して判断する必要があります。私の把握している限り、多くの開発現場ではテストを消すことはその他のコードを消すことよりも慎重に判断される傾向にあるようです(誰が書いたかわからないけど、テストを消すことで発生する品質低下に責任を持てないため)。結果として不要なテストをメンテナンスするエンジニアは、「価値があるのかわからない」作業に時間を取られる事態に陥ります。
いずれにせよ、テストを書き、CI/CDで実行するだけでは品質維持と開発生産性を改善する開発サイクルに多様な課題が発生してきているように見えます。
Predictive Test Selectionとは
2000年代にテスト駆動開発、2010年代にCI/CDが来て、次のテストのトレンドの一つがPredictive Test Selectionです。Predictive Test Selectionとは旧Facebook社(現Meta社)が発表したテスト実行効率化の手法で、PRに対して実行する価値のあるテストを機械学習によって選出するというものです。
- ブログ:https://engineering.fb.com/2018/11/21/developer-tools/predictive-test-selection/
- 論文:https://arxiv.org/pdf/1810.05286.pdf
この論文ではテストの成否はコードの変更と過去のテスト履歴からある程度推論できるとしています。コードを変更して、関連箇所のテストを修正していなければそのテストが失敗する可能性は高くなるでしょう。また、最近頻繁に失敗しがちなテストであれば(原因はどうであれ)、次の実行でも失敗する可能性は高いでしょう。逆に全然変更されていないコードや過去に一度も失敗したことのないテストは、今後も失敗する可能性は低いでしょう(そのテストに価値があるかどうかは別として)。
コード量やテスト量が少なければ、「このコードを変更したらこのテストが落ちるかも」「このテストは最近頻繁に落ちてるから今回も落ちるかも」と推測できますが、ソフトウェアの規模が大きくなるとそれも難しくなります。Predictive Test Selectionではコードの変更ログとテストの実行履歴をデータとして、機械学習によって、そのPRによるテスト実行ではどのテストが失敗する可能性を推論します。
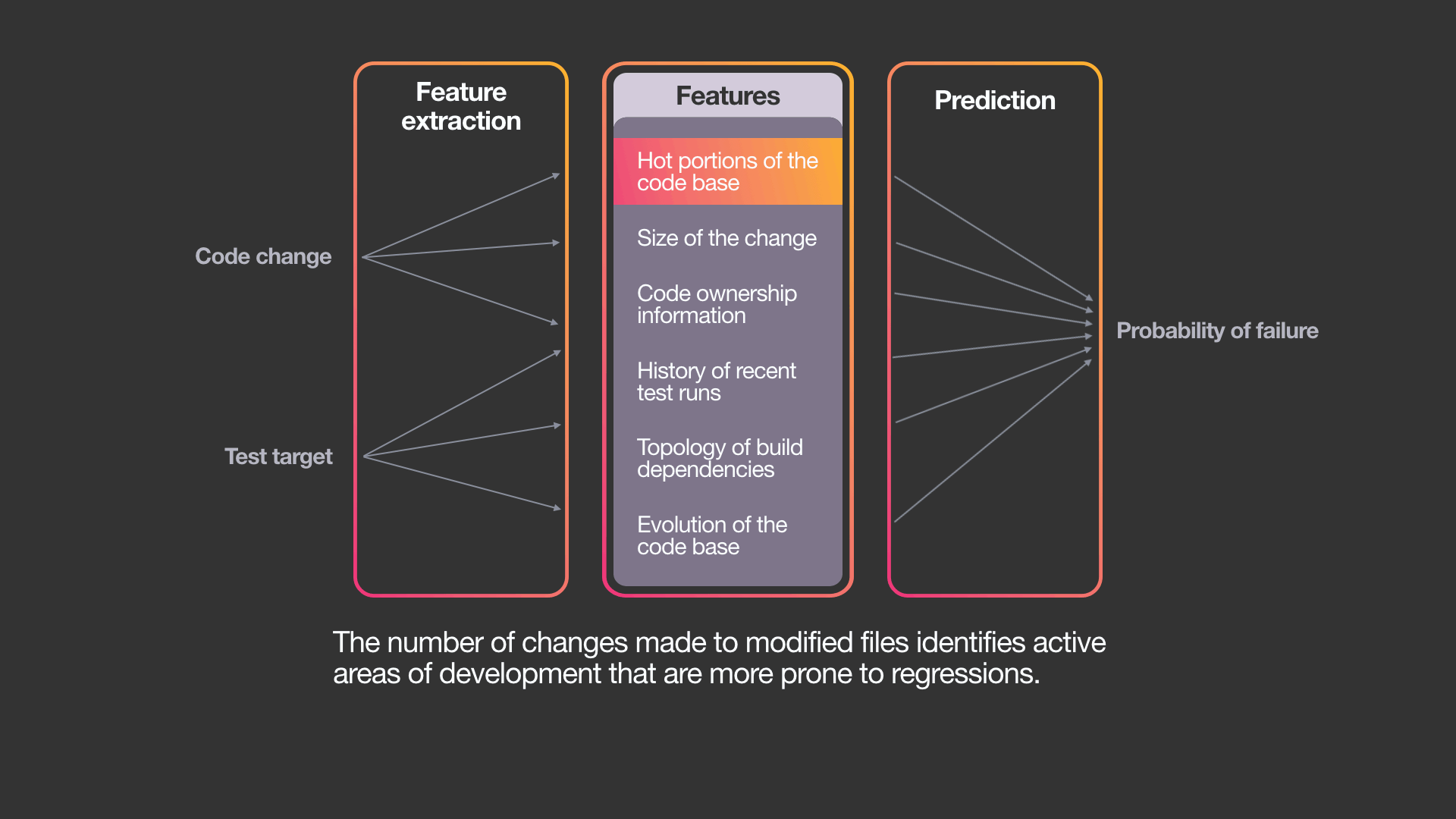
論文では以下を特徴量として活用していると書いてあります。
- ファイルの変更履歴(Change history for files)
- 変更されたファイル数(File cardinality)
- 変更箇所に関わるテスト数(Target cardinality)
- ファイルの拡張子(Extensions of files)
- ファイルの編集者(Number of distinct authors)
- テストの失敗率(Historical failure rated)
- プロジェクト名(Project name)
- テスト数(Number of tests)
- 変更されたファイルとテスト間の距離(Minimal distance between files and target)
- 変更されたファイルとテストの共通の単語数(Number of common tokens)
学習のターゲットデータはテストの成否(2値分類)です。これらのデータをテーブル形式の特徴量とし、勾配ブースティング決定木(Gradient boosting decision tree、GBDT)で学習しています。GBDTは勾配降下法、アンサンブル法、決定木を組み合わせたアルゴリズムです。有名な実装ではXGBoostやLightGBMがその一種で、テーブルデータの機械学習ではとても有効な手法になります。論文ではGBDTを選んだ理由として、すぐ利用でき、学習が早く、ポジティブ/ネガティブラベルの比率が偏った不均衡データでも性能が良く、順序データやカテゴリデータに対応しているため、と書いてあります。
CI/CDのログから当該PR(コードやテストの変更データ)における各テストの成否をデータとして記録します。CI/CDを実行することで学習データが自動生成され記録される仕組みになります。
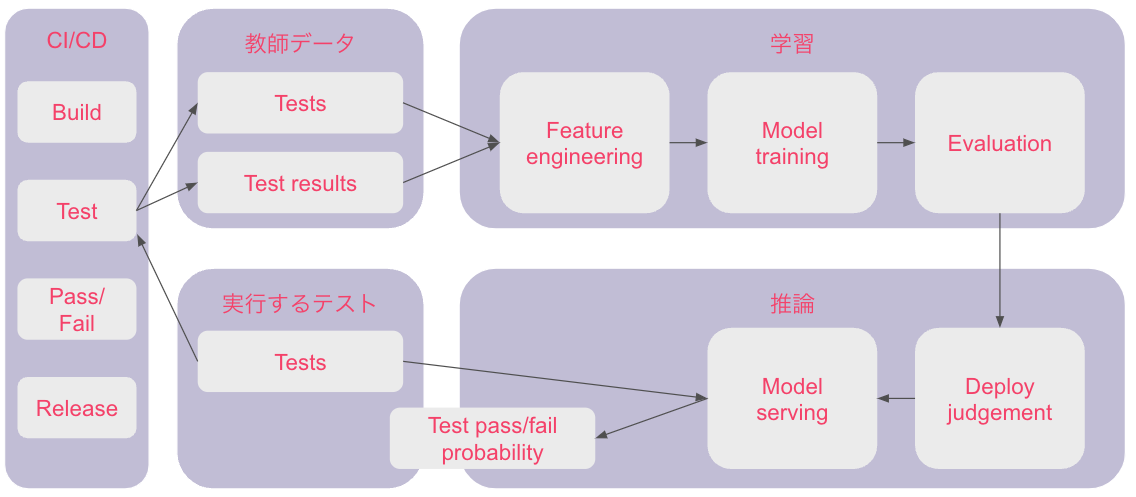
モデルの学習が完了したら、そのモデルを用いてCI/CDによるテストの実行前に必要なテスト(=失敗する可能性の高いテスト)を選出し、CI/CDの実行対象とします。テスト結果は機械学習モデルの評価と学習データとして記録されます。
モデルの価値は「失敗する確率の高いテスト」を見つけることです。成功するテストを実行することは(その成功が偶然でない限り)、実行待ち時間とリソースの無駄になります。逆に失敗するテストを漏らすことは品質が悪化するリスクになります。Predictive Test Selectionでは選出したテストセットの中に可能な限り多くの失敗する可能性の高いテストを詰め込みます。全体から意味のある一部のテストを選出することで待ち時間とコストを削減し、失敗しそうなテストを実行して実際に失敗することで品質の穴を塞ぎます。最終的に修正したコードでテストが通過することによって、ソフトウェア開発のテスト実行サイクルを効率化します。
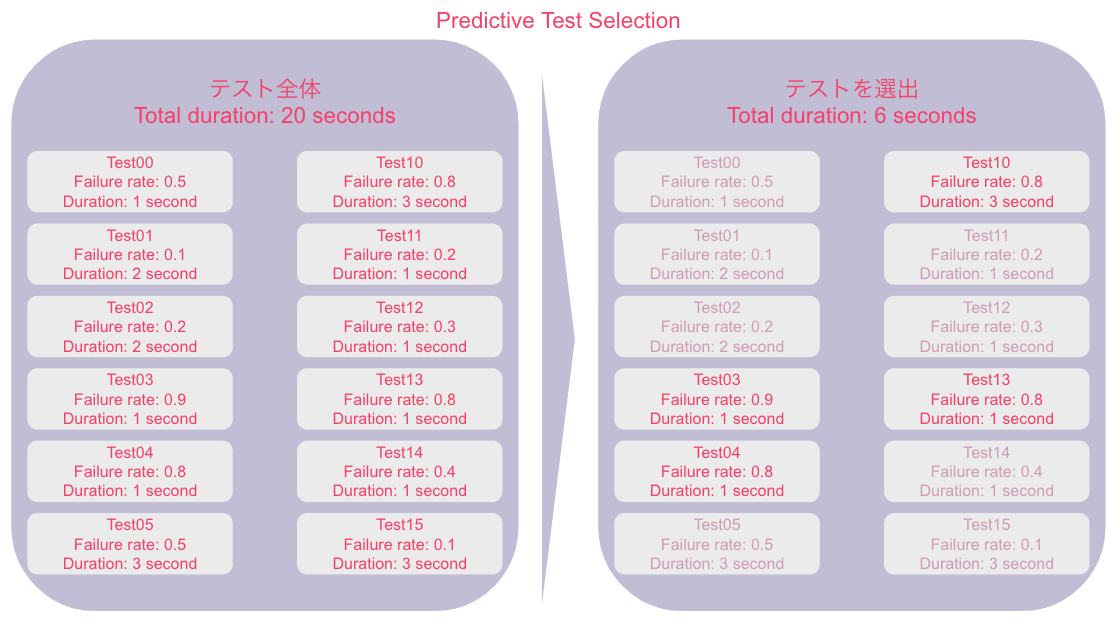
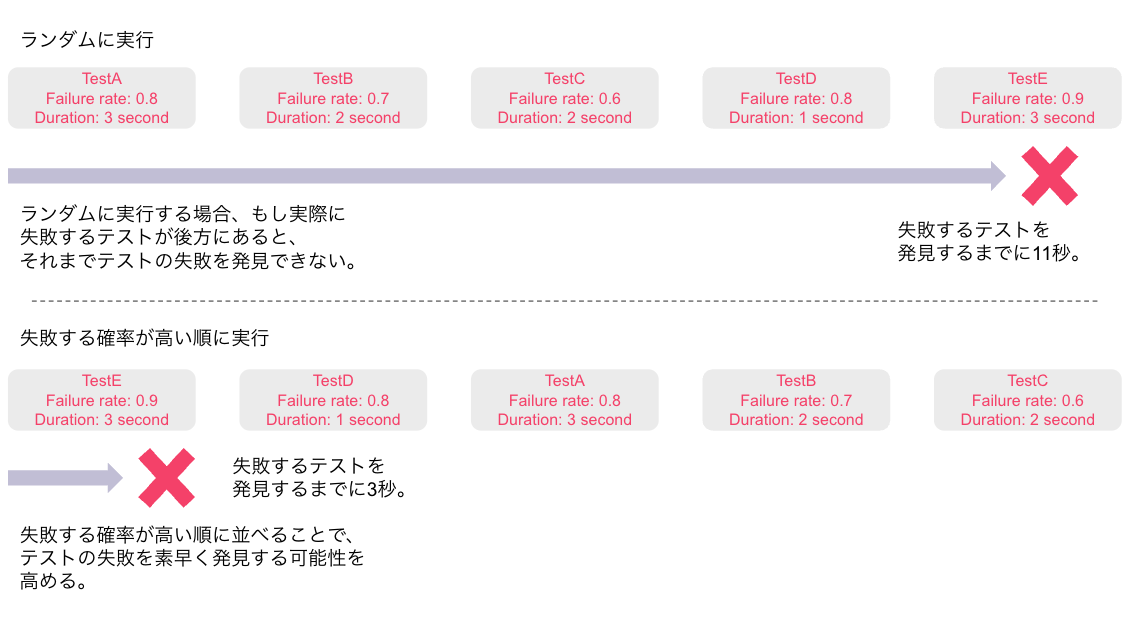
また、テストを失敗する可能性が高い順に並べ替えて、テストの実行順とします。この工夫により、より早くCI/CDを失敗させ、コードの修正に取りかかれるようになります。たとえば合計で120分かかるテストセットがあるとします。Predictive Test Selectionによって、その中から60分ぶんの失敗する可能性の高いテストだけを選出します。選ばれたテストがランダムに並んで実行される場合、実際のテスト失敗が60分中の30分目に発生することがあるでしょう。その場合、エンジニアは30分待たねばなりません。しかし失敗する可能性の高い順番にテストを実行すれば、テストの失敗が最初の5分で判明する確率が高くなります。言い換えるとエンジニアはテストの実行から5分でテストの失敗を修正する作業を開始できます。つまり、テストの実行順序を失敗する可能性の高い順番にすることで、30分の待ち時間を5分に短縮する効果を得ることができます。エンジニア組織の大小に関わらず、CI/CDによるテストの実行が常識となり、テスト実行時間がエンジニアの待ち時間となる現状では、CI/CDの待ち時間30分が5分になる価値はご理解いただけるでしょう。
Predictive Test Selectionで実行するテストを選出することによって、逆に実行頻度が少ないテストも明確になります。Predictive Test Selectionではコードの変更やテスト実行履歴から失敗しやすいテストを選んで優先して実行するため、選出されないテストというのは、失敗する可能性が低いテスト、またはコードの変更と関係することが少ないテスト(または滅多に変更されないコードのテスト)ということができます。言い方を変えると、そうしたテストは優先して削除の対象と考えることができ、テストの全体量を削減する(=テストコードのメンテナンスを回避する)機運となるでしょう。
Predictive Test Selectionのようなテストのデータ分析で見えてくる新たな課題の一つに、Flaky testというものがあります。Flaky testとはランダムに失敗しているテストのことを言います。全く関係のないコードを変更しているのに、またはコードを一切変更していないのに、何らかの要因(外部要因やリソース不足等)によりテストが失敗するものをFlaky testと言います。こうしたFlaky testは修正が難しい一方で、再実行すれば成功する場合もあるため、修正を後回しにされがちな問題になります。
Predictive Test Selectionではコードの変更に関連して失敗しそうな意味のあるテストを推論します。そのため、Flaky testとして失敗しているテストがテストセットに含まれるのは避けたいものです。
Flaky testはランダムに失敗するテストである特性上、各テスト実行の成否を記録していけば、そのテストがどのくらいFlakyかどうかを判断することができます。Predictive Test Selectionでは関連のないFlaky testをテストセットから排除することで、不要なテスト実行とその修正のための調査を避けることができます。
(だからと言って、Flaky testを放置するのが良策ということではありません。原因を特定して解決できるのであれば、Flaky testは削減するほうが望ましいです。特にFlakyと思われていたテストが実は原因があって失敗していた場合、そのテストの失敗を放置することはリスクとなるでしょう。Flaky testについてこの論文が詳しいです。)
テストの実行を効率化することは、ソフトウェアの品質を維持するだけでなく、エンジニアの生産性を向上させることができます。こうした取り組みが多数のエンジニアを抱え、全世界規模のサービスを提供するMeta社(Facebook、Instagram、Oculus、Whatsapp・・・)から出てきたのは必然でしょう。そして同様の取り組みはMeta社だけでなくGoogle社からも「Taming Google-Scale Continuous Testing」として登場しています。
マイクロソフト社でも「FastLane: Test Minimization for Rapidly Deployed Large-scale Online Services」として機械学習によるコミットのリスク(テストの失敗)を推論する取り組みがあります。
ソフトウェア規模やエンジニア組織が巨大になるとテストの自動実行が課題となり、そのための工夫が必要になります。Predictive Test Selectionではないですが、楽天社でもテスト実行を効率化する仕組みは実現されています。
テスト駆動開発によってテストを書くことが常識となり、実行環境をJenkinsやGitHub Actions、CircleCIに代表されるCI/CD基盤が利用されるようになりました。その次のステップとして、Predictive Test Selectionに代表される手法でテスト実行の効率化が検討され広まってきている流れを感じます。
まとめ
最後に本題なのですが、筆者が所属しているLaunchable社ではPredictive Test SelectionやFlaky testの検知を実現するサービスを提供しています。テスト実行の時間やコストに困っているエンジニアの皆様、ぜひLaunchableのご利用をご検討いただけると幸いです。
なお、Launchableの仕組みや使い方については以下Launchable Advent Calendarで毎日発信していますので、合わせてご参照ください。