目的
Python3.5、Anaconda4.3環境を使用しています。
Kerasで作ったLSTMモデルをJupyter Notebook上でpydot + Graphvizで可視化する際の手順です。
OSはCentOS7.3です。
ここにKerasのモデルを可視化する方法が書いてあるのですが、必要なパッケージ含めて解説します。
https://keras.io/visualization/
手順
- yumでOSにgraphvizをインストール。
- pipでpydot、graphvizをインストール。
- Jupyter Notebookでモデルを可視化してみる。
yumでOSにgraphvizをインストール
Graphviz自体はPythonと関係ないパッケージです。
http://www.graphviz.org/About.php
CentOSに限らず、OSで動作するものなので、まずはインストールします。
sudo yum -y install graphviz
pipでpydot、graphvizをインストール
Pythonでgraphvizを使ってモデル可視化するためにはpydotとgraphvizが必要です。
こちらのgraphvizはOSパッケージのPythonラッパーになります。
pip install pydot graphviz
これでインストールできましたが、可視化するために、環境によっては以下が必要になるかもしれません。
pip install pydot3 pydot-ng
Jupyter Notebookでモデルを可視化してみる
Jupyter Notebookを起動して、KerasでLSTMモデルを書きます。
今回はここのモデルを転用します。
http://machinelearningmastery.com/sequence-classification-lstm-recurrent-neural-networks-python-keras/
import numpy as np
import pydot
from keras.datasets import imdb
from keras.models import Sequential
from keras.layers import Dense, LSTM
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
from keras.utils.visualize_util import model_to_dot
from IPython.display import SVG
np.random.seed(7)
top_words = 5000
(x_train, y_train), (x_test, y_test) = imdb.load_data(nb_words=top_words)
max_review_length = 500
x_train = sequence.pad_sequences(x_train, maxlen=max_review_length)
x_test = sequence.pad_sequences(x_test, maxlen=max_review_length)
embedding_vector_length = 32
model = Sequential()
model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length))
model.add(LSTM(100))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
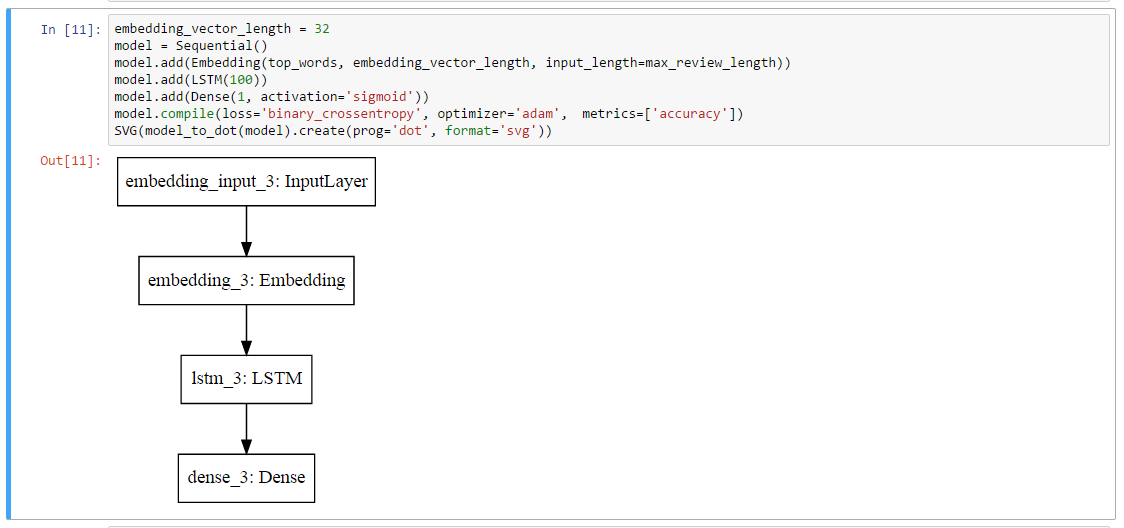
# ここでモデルを可視化する。
SVG(model_to_dot(model).create(prog='dot', format='svg'))
model.fit(x_train, y_train, validation_data=(x_test, y_test), nb_epoch=3, batch_size=64)
scores = model.evaluate(x_test, y_test, verbose=0)
print ("accuracy: %.3f%%" % (scores[1]*100))
これで↓のようにモデルを可視化できます。