Kerasでfizzbuzz問題を解く
Fizzbuzz問題はご存知でしょうか?
プログラミングの初級問題で、以下のようなコードを書くものです。
1から100までの整数について、3で割り切れるときは"fizz"、5で割り切れるときは"buzz"、15で割り切れるときは"fizzbuzz"、それ以外のときは数字を出力する。
回答の一例をPythonで書くと以下になります。
import numpy as np
num = np.arange(1,101,1)
for i in num:
if i % 15 == 0: print ("fizzbuzz")
elif i % 5 == 0: print ("buzz")
elif i % 3 == 0: print ("fizz")
else: print (i)
コードの書き方は無数にありますが、基本的にforとifで場合分けすれば簡単に書けます。
しかし!
こういう問題はディープラーニングで解いてみたくなるのは人間の性です。
しかもTensorflowでも解いている先人もいますし(解けてないけど(。ŏ﹏ŏ))
http://joelgrus.com/2016/05/23/fizz-buzz-in-tensorflow/
というわけで、上記Tensorflow fizzbuzzをKerasで書き換えてみようと思います。
主にモデル部分のみKerasに移行しており、その他のコードはほぼTensorflow版をそのまま参考にしています。
目標
教師あり学習でニューラルネットワークモデルを作り、1から100の整数をテストデータとしてモデルの正答率を評価します。
Kerasで書く
それでは早速書いていきましょう。
まずは必要なライブラリをimportします。
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
from keras.layers import Dense
from keras.models import Model
教師データが必要です。
今回は101から1024の整数を教師データとしますが、教師データはバイナリ形式で持ちます。
つまり、(923, 10)の行列が教師データになります。
def binary_encode(i, num_digits):
return np.array([i >> d & 1 for d in range(num_digits)])
NUM_DIGITS = 10
trX = np.array([binary_encode(i, NUM_DIGITS) for i in range(101, 2 ** NUM_DIGITS)])
さて、教師データのfizzbuzz値も必要です。
これもバイナリ形式で作ります。
def fizz_buzz_encode(i):
if i % 15 == 0: return np.array([0, 0, 0, 1])
elif i % 5 == 0: return np.array([0, 0, 1, 0])
elif i % 3 == 0: return np.array([0, 1, 0, 0])
else: return np.array([1, 0, 0, 0])
trY = np.array([fizz_buzz_encode(i) for i in range(101, 2 ** NUM_DIGITS)])
これで教師データの101から1024の整数(バイナリ形式)とそのfizzbuzz(バイナリ形式)ができあがりました。
事前準備は完了です。
それではモデルを書いていきましょう。
シーケンシャルでモデルを生成します。
model = Sequential()
レイヤーを追加します。
今回は3レイヤー(全結合)ネットワークにします。
model.add(Dense(1000, input_dim=10, activation="relu"))
model.add(Dense(1000, activation="relu"))
model.add(Dense(4, activation="softmax"))
最終的な出力は整数、fizz、buzz、fizzbuzzのいずれかなので、最後のレイヤーはアウトプットが4になります。
最適化アルゴリズムはadagradにします。
Tensorflow版はSGDでしたが、Kerasでやったらあまり収束しませんでした。
モデルをコンパイルし、学習させてみましょう。
model.compile(loss='categorical_crossentropy', optimizer='adagrad', metrics=["accuracy"])
model.fit(trX, trY, nb_epoch=100, batch_size=128)
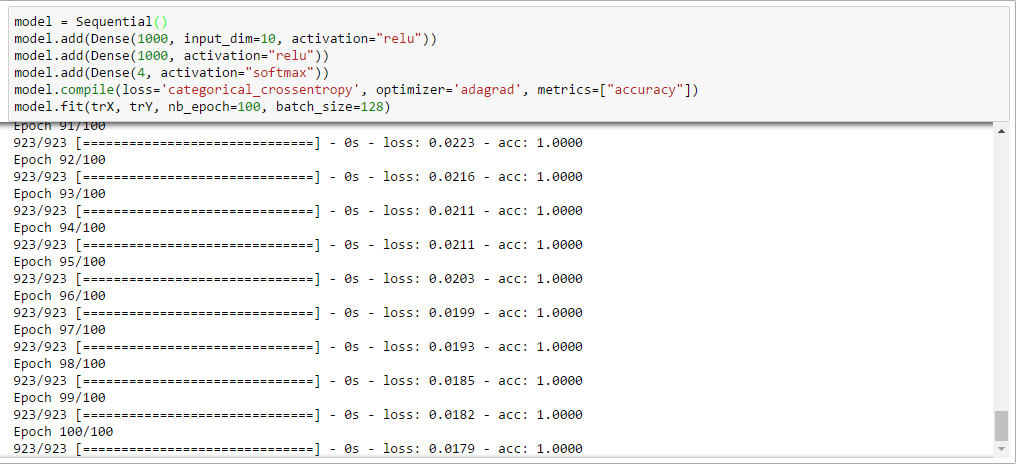
まあまあの収束率です。
(若干オーバーフィット気味?)
モデルの評価
それではこのモデルを評価してみましょう。
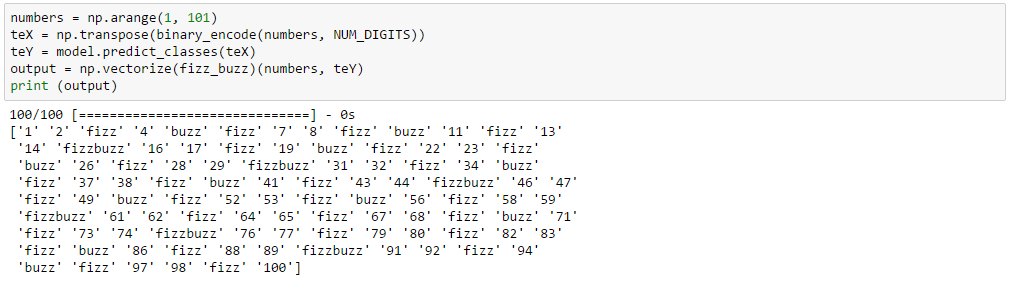
1から100の整数に対し、モデルを適用してみます。
def fizz_buzz(i, prediction):
return [str(i), "fizz", "buzz", "fizzbuzz"][prediction]
numbers = np.arange(1, 101)
teX = np.transpose(binary_encode(numbers, NUM_DIGITS))
teY = model.predict_classes(teX)
output = np.vectorize(fizz_buzz)(numbers, teY)
print (output)
出ました。
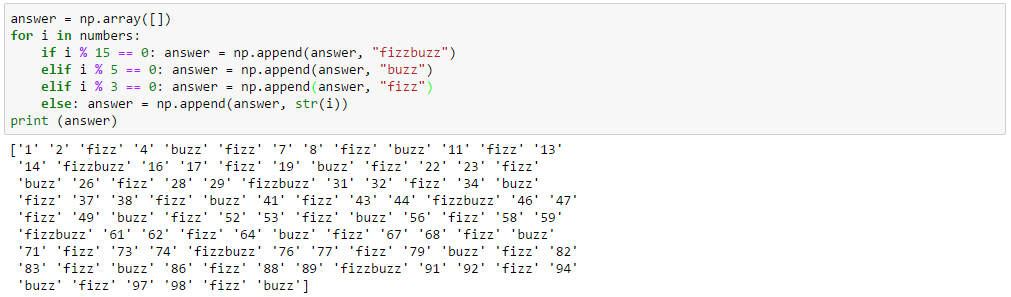
ちなみに、正解は以下になります。
answer = np.array([])
for i in numbers:
if i % 15 == 0: answer = np.append(answer, "fizzbuzz")
elif i % 5 == 0: answer = np.append(answer, "buzz")
elif i % 3 == 0: answer = np.append(answer, "fizz")
else: answer = np.append(answer, str(i))
print (answer)
モデルの正解率をみてみましょう。
evaluate = np.array(answer == output)
print (np.count_nonzero(evaluate == True) / 100)

97%!!
まあまあ良いのかな?
レイヤー数やユニット数を増やしてみればより良い正解率が出るかもしれませんが、まあおいおい。
コード全体は以下になります。
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
from keras.layers import Dense
from keras.models import Model
# 教師データ生成
def binary_encode(i, num_digits):
return np.array([i >> d & 1 for d in range(num_digits)])
NUM_DIGITS = 10
trX = np.array([binary_encode(i, NUM_DIGITS) for i in range(101, 2 ** NUM_DIGITS)])
# 教師データのfizzbuzz
def fizz_buzz_encode(i):
if i % 15 == 0: return np.array([0, 0, 0, 1])
elif i % 5 == 0: return np.array([0, 0, 1, 0])
elif i % 3 == 0: return np.array([0, 1, 0, 0])
else: return np.array([1, 0, 0, 0])
trY = np.array([fizz_buzz_encode(i) for i in range(101, 2 ** NUM_DIGITS)])
# モデル
model = Sequential()
model.add(Dense(1000, input_dim=10, activation="relu"))
model.add(Dense(1000, activation="relu"))
model.add(Dense(4, activation="softmax"))
model.compile(loss='categorical_crossentropy', optimizer='adagrad', metrics=["accuracy"])
model.fit(trX, trY, nb_epoch=100, batch_size=128)
# バイナリのfizzbuzz変換
def fizz_buzz(i, prediction):
return [str(i), "fizz", "buzz", "fizzbuzz"][prediction]
# モデルを1から100の整数に適用してみる
numbers = np.arange(1, 101)
teX = np.transpose(binary_encode(numbers, NUM_DIGITS))
teY = model.predict_classes(teX)
output = np.vectorize(fizz_buzz)(numbers, teY)
print (output)
# 正解
answer = np.array([])
for i in numbers:
if i % 15 == 0: answer = np.append(answer, "fizzbuzz")
elif i % 5 == 0: answer = np.append(answer, "buzz")
elif i % 3 == 0: answer = np.append(answer, "fizz")
else: answer = np.append(answer, str(i))
print (answer)
# 正解率
evaluate = np.array(answer == output)
print (np.count_nonzero(evaluate == True) / 100)