畳み込みオートエンコーダ
Kerasで畳み込みオートエンコーダ(Convolutional Autoencoder)を3種類実装してみました。
オートエンコーダ(自己符号化器)とは入力データのみを訓練データとする教師なし学習で、データの特徴を抽出して組み直す手法です。
2種類の階層から構成されており、1階層目がエンコーダ、2階層目がデコーダです。エンコーダとデコーダは表裏一体のニューラルネットワークとなっていて、エンコーダのニューロン数が256→128→64→32と推移した場合、デコーダのニューロン数は逆に32→64→128→256となります。
要は入力データが目的データになっていて、エンコーダ、デコーダというニューラルネットワークをとおして入力データ≒出力データとなるよう重みを調整するようにできています。
イメージとして以下のようになります。
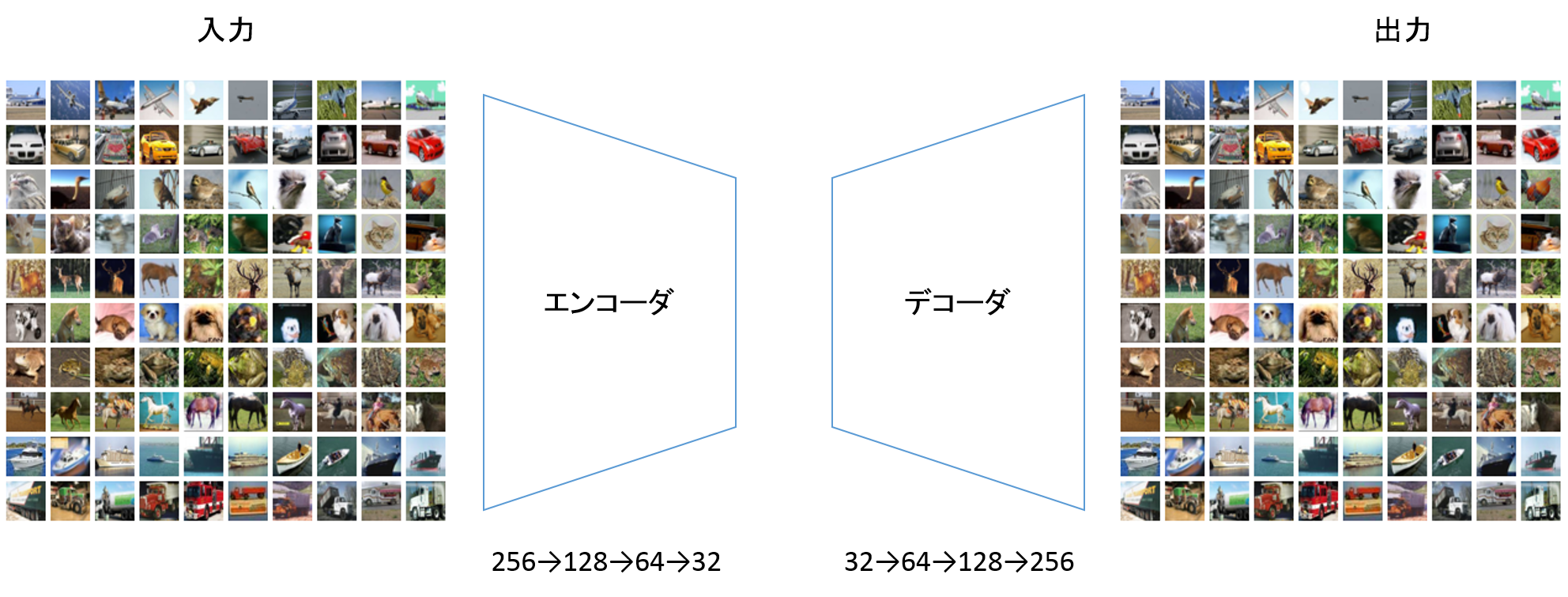
入力には構造化データや非構造化データ(画像やテキスト)を用いることができます。
出力は元データを再現または加工したものになります。
今回はCifar10の画像データを用いて以下の畳み込みオートエンコーダを実装しました。
- シンプルな畳み込みオートエンコーダ
- ノイズ除去オートエンコーダ
- UNET
コードは以下にあります。
https://github.com/shibuiwilliam/Keras_Autoencoder
画像データに対するオートエンコーダについては以下が詳しいです。
Kerasで学ぶAutoencoder
シンプルな畳み込みオートエンコーダ
畳み込みオートエンコーダでは入力画像を再現するオートエンコーダを実装します。
入力画像≒出力画像になることが目的です。
畳み込みオートエンコーダのコードはこちらです。
畳み込みオートエンコーダではエンコーダに畳み込み+MaxPooling(あとBatchNormalizationを入れても良い)、デコーダに畳み込み+アップサンプリング(BatchNormalization以下略)を使います。
エンコーダで画像の次元数を縮小していき、デコーダで拡張していきます。
デコーダを畳み込み+アップサンプリングにしているのは、この構成でDeconvolutionするからです。
エンコーダで64→32→16と縮小し、デコーダで16→32→64と拡大して元の画像を再現します。
この実装ではBatchNormalizationを加えていますが、効果のほどは「う~ん・・・」な感じです。
エンコーダ・デコーダ部分のみ抜粋して以下に転載します。
input_img = Input(shape=(32, 32, 3))
x = Conv2D(64, (3, 3), padding='same')(input_img)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(16, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(16, (3, 3), padding='same')(encoded)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(32, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(64, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(3, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
decoded = Activation('sigmoid')(x)
model = Model(input_img, decoded)
model.compile(optimizer='adam', loss='binary_crossentropy')
es_cb = EarlyStopping(monitor='val_loss', patience=2, verbose=1, mode='auto')
chkpt = saveDir + 'AutoEncoder_Cifar10_Deep_weights.{epoch:02d}-{loss:.2f}-{val_loss:.2f}.hdf5'
cp_cb = ModelCheckpoint(filepath = chkpt, monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
# input data is target data
history = model.fit(x_train, x_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_val, x_val),
callbacks=[es_cb, cp_cb],
shuffle=True)
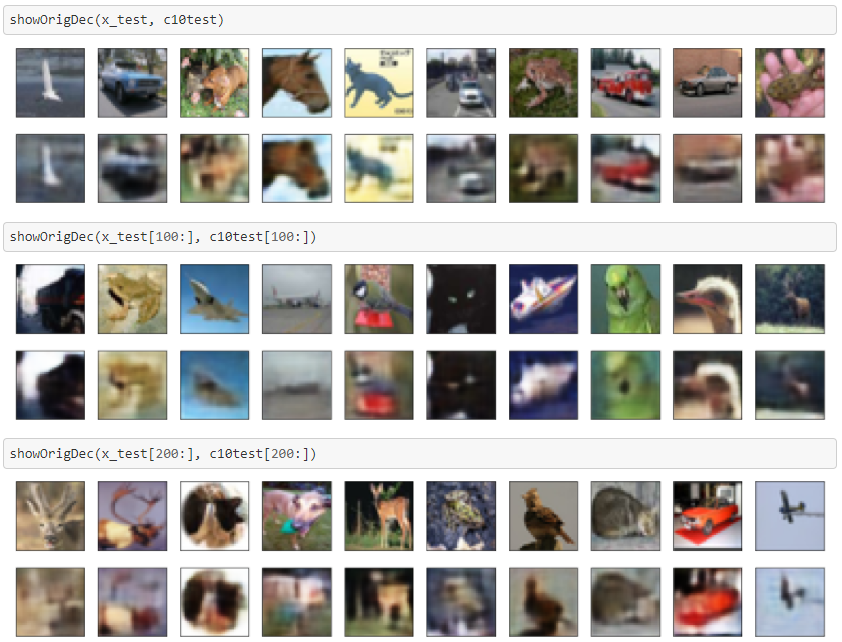
入力画像(上段)と出力された再現画像(下段)を並べて表示します。
ご覧のとおり、出力画像は滲んでしまっています。
MNISTでやっている例では案外きれいに再現できているので、どうもRGB3色の再現は難しいらしいです。
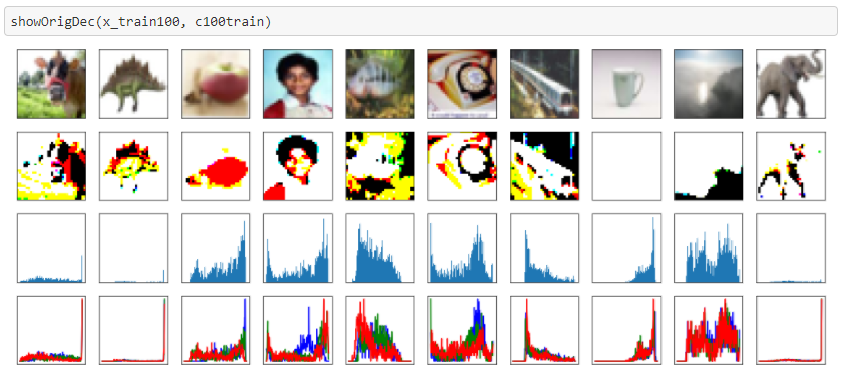
Cifar10で作ったモデルでCifar100画像も再現してみました。
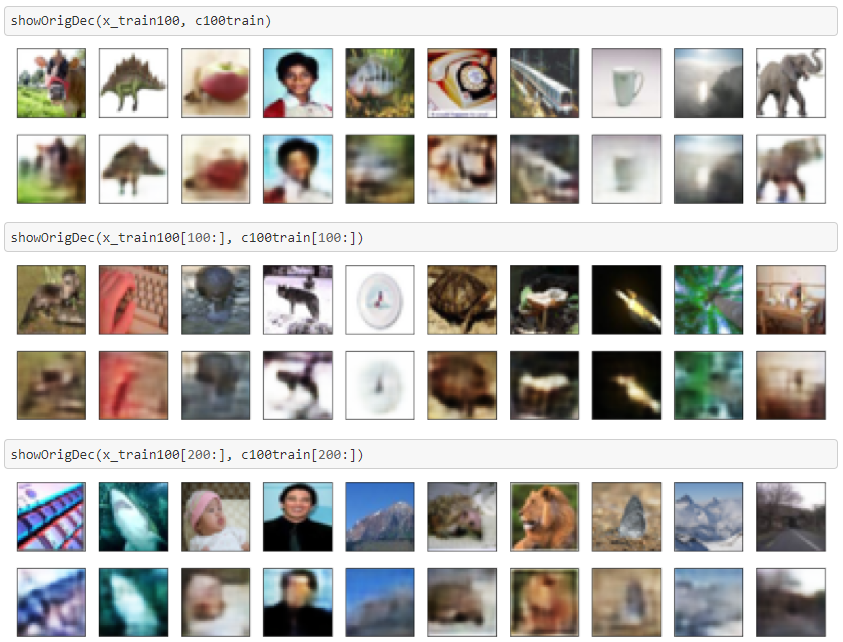
にじみ具合はCifar10と同じくらいな気がします。
ノイズ除去オートエンコーダ
オートエンコーダは画像中のノイズ除去を除去するのにも使えます。
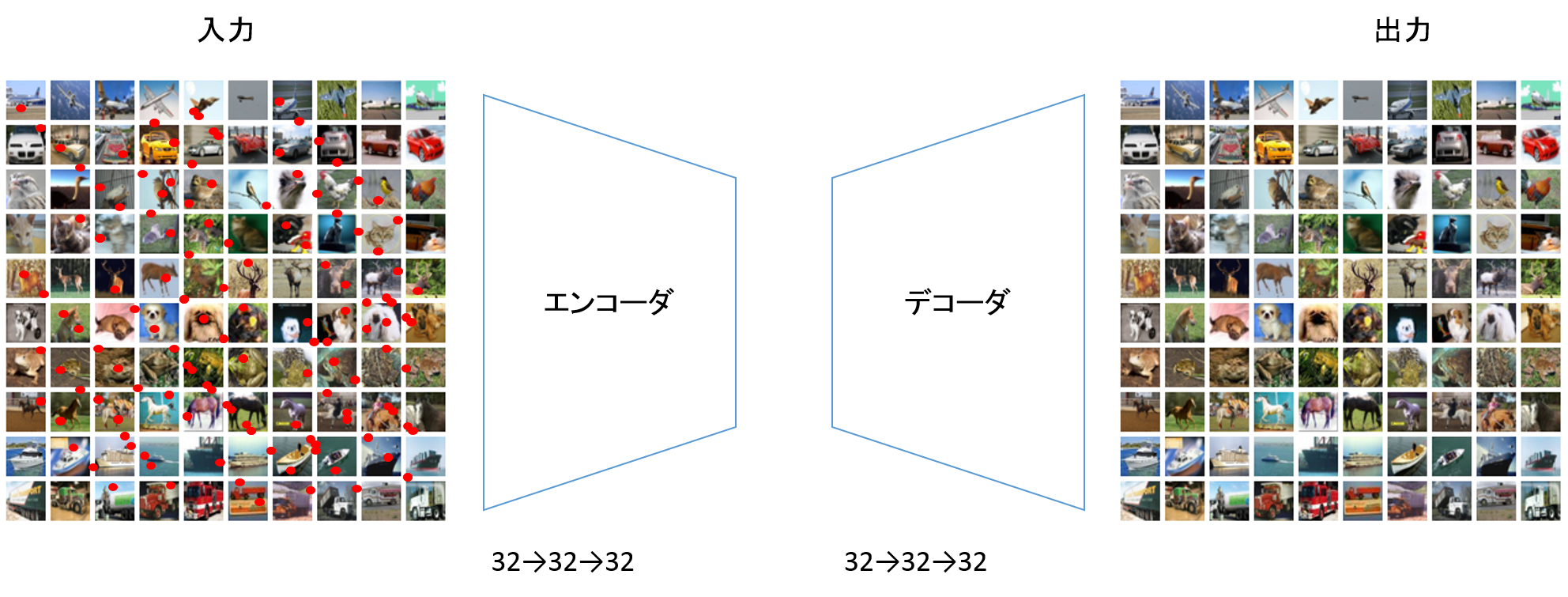
イメージは以下になりまして、ノイズのある画像からノイズを除去してくれます。
コードはこちらです。
ノイズ除去オートエンコーダでは畳み込みオートエンコーダよりもフィルター数を増やしています。
エンコーダが32→32→32、デコーダも32→32→32になります。
ノイズ除去オートエンコーダでは訓練データに、入力データはノイズあり画像、ターゲットデータはノイズなし画像を使います。
input_img = Input(shape=(32, 32, 3))
x = Conv2D(32, (3, 3), padding='same')(input_img)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (3, 3), padding='same')(encoded)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(32, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(3, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
decoded = Activation('sigmoid')(x)
model = Model(input_img, decoded)
model.compile(optimizer='adam', loss='binary_crossentropy')
es_cb = EarlyStopping(monitor='val_loss', patience=2, verbose=1, mode='auto')
chkpt = saveDir + 'AutoEncoder_Cifar10_denoise_weights.{epoch:02d}-{loss:.2f}-{val_loss:.2f}.hdf5'
cp_cb = ModelCheckpoint(filepath = chkpt, monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
history = model.fit(x_train_noisy, x_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_val_noisy, x_val),
callbacks=[es_cb, cp_cb],
shuffle=True)
ノイズ除去能力を示すために、元画像(上段)、ノイズを加えた画像(中段)、ノイズ除去画像(下段)を並べて表示します。
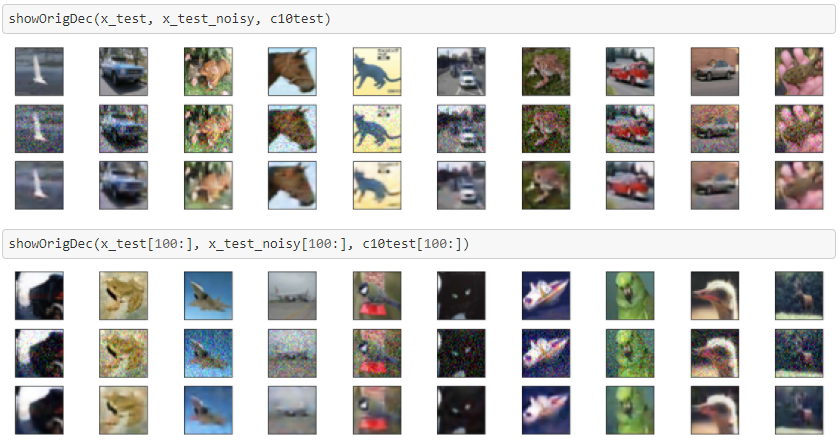
ノイズ除去はできていますが、やはり滲んでしまっています。
Cifar100についても同様です。
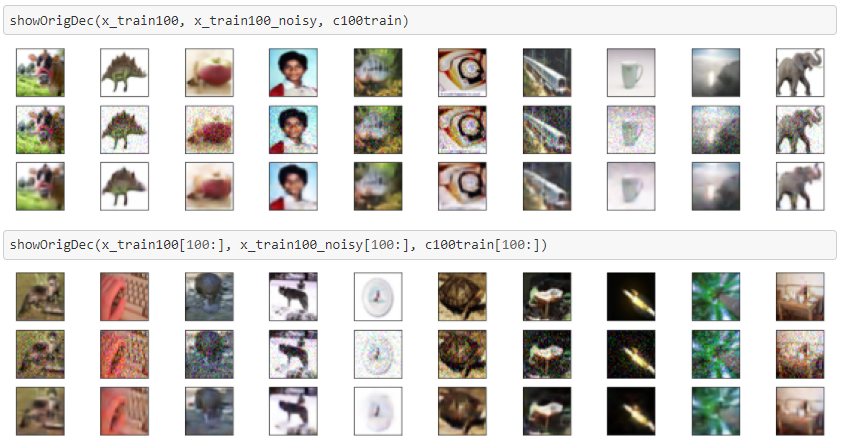
UNET
UNETはセグメンテーションを行うためのオートエンコーダ
です。
セグメンテーションについてはここが詳しいです(英語ですが・・・)。
セグメンテーションはUNETやオートエンコーダだけでなく、Fully Convolutional Network(FCN)でも実装があります。
UNETは以下のようなU字型をした構造をしています。
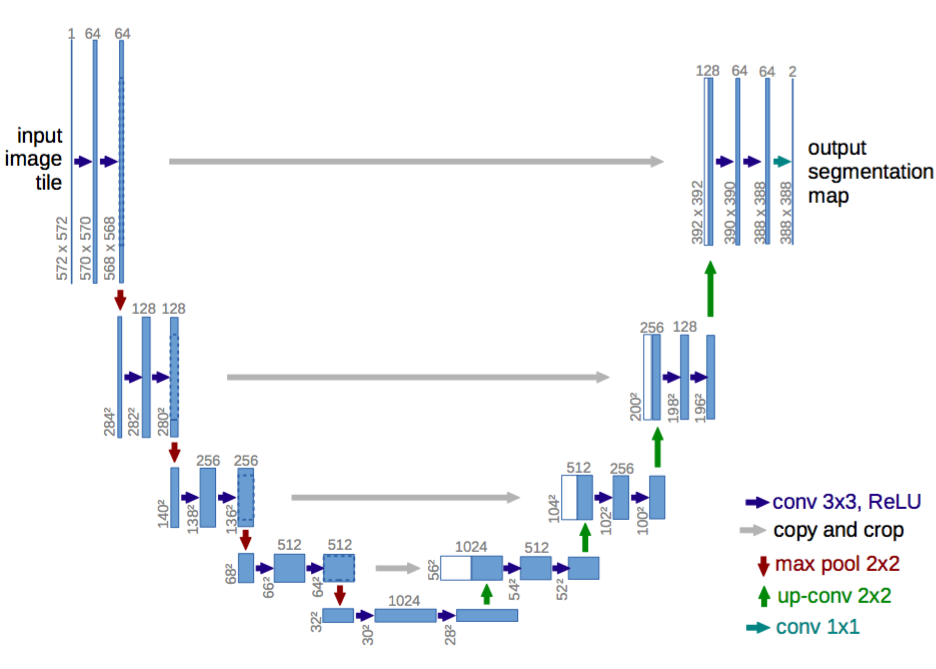
構造としてはVGGを重ねたようなものとなっており、エンコーダでConv→Conv→MaxPoolingを繰り返し、デコーダでConv→Conv→合成を繰り返します。
デコーダの合成(Concatenate)では、エンコーダの対応するConv層と合成します。
上記画像でエンコーダからデコーダに灰色の矢印が引かれているのはこの合成を表しています。
損失関数にはDICE係数(DICE Coefficient)を使います。
DICT係数は類似度をはかる指数でして、以下の計算をします。
X = True
Y = Prediction
\frac{2 * |X∩Y|}{|X| + |Y|}
コードの主要部分のみを抜粋します。
# dice coefficient
def dice_coef(y_true, y_pred):
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = K.sum(y_true_f * y_pred_f)
return (2. * intersection + 1) / (K.sum(y_true_f) + K.sum(y_pred_f) + 1)
def dice_coef_loss(y_true, y_pred):
return -dice_coef(y_true, y_pred)
inputs = Input((32, 32, 3))
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(inputs)
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv1)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(pool1)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv2)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(pool2)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv3)
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
conv4 = Conv2D(256, (3, 3), activation='relu', padding='same')(pool3)
conv4 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv4)
pool4 = MaxPooling2D(pool_size=(2, 2))(conv4)
conv5 = Conv2D(512, (3, 3), activation='relu', padding='same')(pool4)
conv5 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv5)
up6 = concatenate([Conv2DTranspose(256, (2, 2), strides=(2, 2), padding='same')(conv5), conv4], axis=3)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(up6)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)
up7 = concatenate([Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(conv6), conv3], axis=3)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(up7)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv7)
up8 = concatenate([Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(conv7), conv2], axis=3)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(up8)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv8)
up9 = concatenate([Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same')(conv8), conv1], axis=3)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(up9)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv9)
conv10 = Conv2D(3, (3, 3), activation='sigmoid', padding='same')(conv9)
model = Model(inputs=[inputs], outputs=[conv10])
model.compile(optimizer='adam', loss=dice_coef_loss, metrics=[dice_coef])
es_cb = EarlyStopping(monitor='val_loss', patience=4, verbose=1, mode='auto')
chkpt = saveDir + 'AutoEncoder_UNET_weights.{epoch:02d}-{loss:.2f}-{val_loss:.2f}.hdf5'
cp_cb = ModelCheckpoint(filepath = chkpt, monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
history = model.fit(x_train, x_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_val, x_val),
callbacks=[es_cb, cp_cb],
shuffle=True)
セグメンテーションしてみた結果は以下になります。
元画像(上段)、セグメンテーション(2段目)、グレイ・スケールのヒストグラム(3段目)、RGBのヒストグラム(下段)を表示しています。
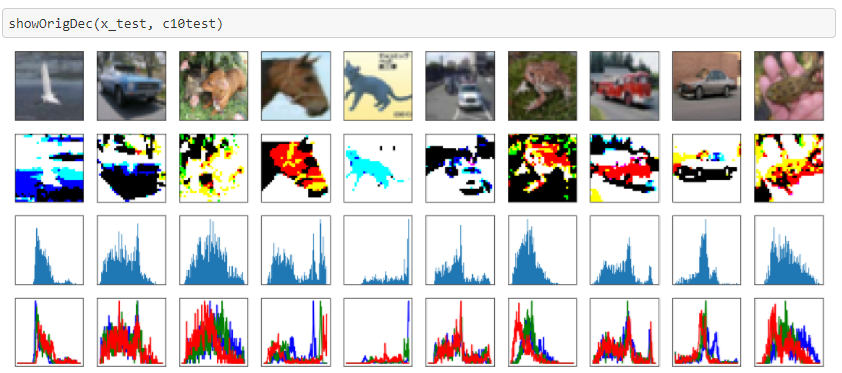
セグメンテーションできれいに物体が浮かび上がっている画像もあれば、そうでないものもあります。
ヒストグラムと見比べればわかりますが、ヒストグラムが尖った山を成していて、尖った山=物体(または尖った山=物体以外)になっている画像ではうまくセグメンテーションしているように思います。
こういう画像だと、物体と背景を区別する色合いがうまく抽出できているのでしょう。
逆に全体でなだらかな丘を作っているものは画像が潰れているような感じがします。
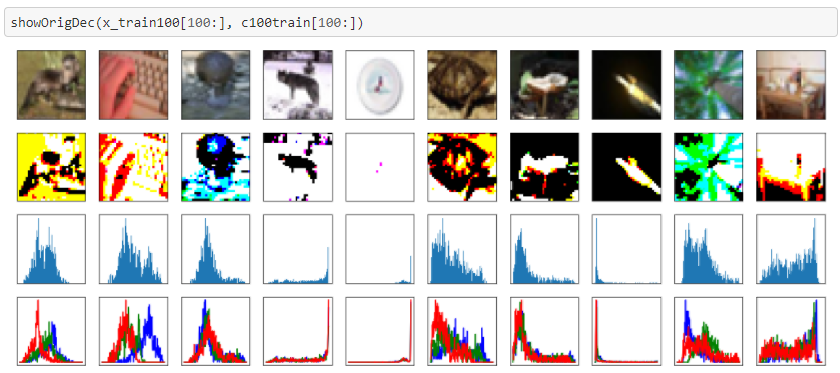
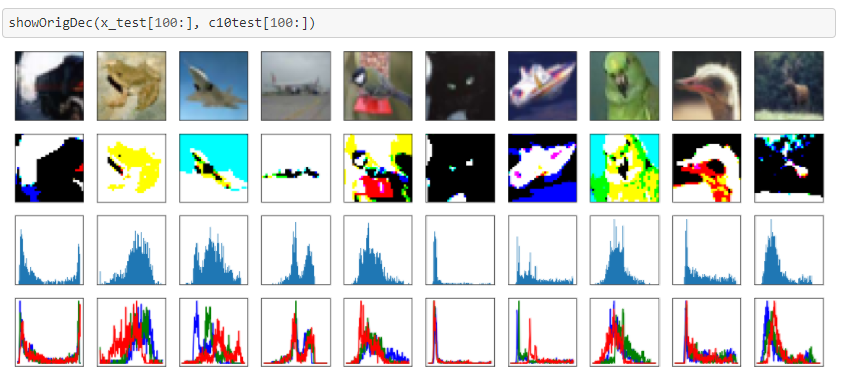
Cifar100のセグメンテーションです。
こちらはあまりうまくいっていないように見えますね。