はじめに
本記事では、前回に引き続いてClickHouseでレプリケーション構成を作るための設定について記載します。なお、ほぼ公式ドキュメントオンリーみたいな状態で自己流で作っていますのでもっと良いやり方があるかもしれません。
また本格運用前でとりあえず動いた!レベルの人間が書いた記事ですので鵜呑みにしないようにお願いします。
ClickHouseのレプリケーション構成について
まず、ClickHouseのレプリケーションの設定はテーブル単位です。Zookeeperに分散構成を取るテーブルの情報を格納し、各サーバがそこにクエリキューを溜めていって、「俺も更新しなきゃ!」という該当シャードのサーバがいたらクエリを実行するような感じ…という気がします(妄想)。すごい大雑把な概念図は以下のような感じなんでしょうか。id=と書いてる部分は特に意味はありません。
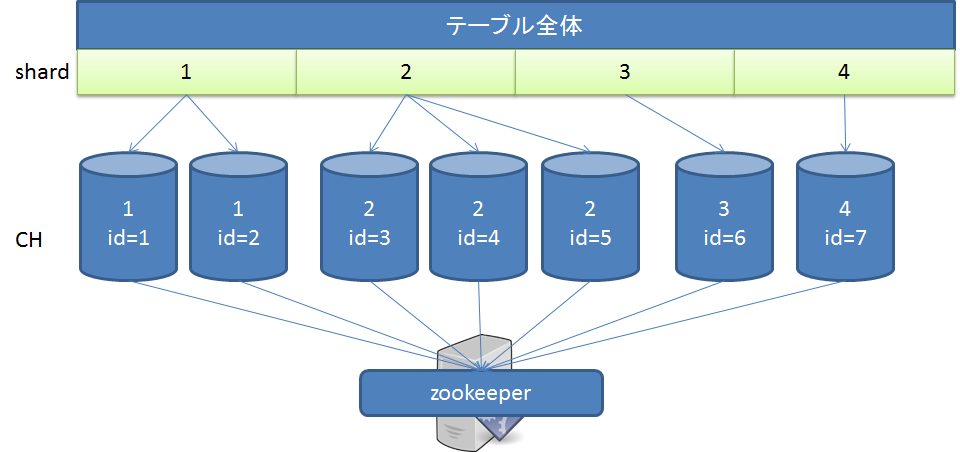
テーブル全体が複数のシャード(任意の数)によって構成されていて、各ClickHouseのインスタンスがシャードに割り当たっています。config.xmlの中におもむろにシャード番号を設定します。
同一シャード番号のインスタンスは、同一のデータを持ちます。
シャーディングはともかくとして、単純なレプリケーションを組むのであれば、全ノード同じシャード番号を持つように構成すれば構成できます。
具体的な設定について
zookeeper
まずはZooKeeperを立てます。これは同じサーバ上でも、あるいは他のサーバ上でもいいですし、既存でzookeeperを使われているのでしたらそのzookeeperを指定しても構いません。
zookeeperの構築については省略します。
設定(config.xml)
/etc/clickhouse-server/config.xmlの中を編集していきます。まずはzookeeperサーバを指定します。zookeeperセクションは既にあるので、書き換えましょう。
<zookeeper>
<node index="1">
<host>zookeeper001</host>
<port>2181</port>
</node>
<node index="2">
<host>zookeeper002</host>
<port>2181</port>
</node>
<node index="3">
<host>zookeeper003</host>
<port>2181</port>
</node>
</zookeeper>
次に、自分のシャード番号を示すためにmacrosセクションを修正します。これはクエリの中で使えるマクロ、変数みたいなもので、それ自体に意味があるものではありません。setとshardとreplicaはそういう名前の変数というだけです。どう使うかは後々の説明になります。
1号機
<macros>
<set>1</set>
<shard>1</shard>
<replica>clickhouse01</replica>
</macros>
2号機
<macros>
<set>1</set>
<shard>1</shard>
<replica>clickhouse02</replica>
</macros>
あとは、ClickHouseを再起動します。なおreload呼んでも再起動します。
$ service clickhouse-server restart
テーブル作成
レプリケーションを行うには、レプリケーションを想定したテーブルエンジンでテーブルを作成する必要があります。それが、ReplicatedMergeTreeになります。
CREATE TABLE文は以下の通りで、これを全ノードで個別に実行します。
CREATE TABLE rep_access_log_20171221 (
log_date Date,
url String,
referrer String,
ip String,
ua String,
created_at DateTime
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{set}-{shard}/rep_access_log' , '{replica}', log_date, (log_date, url, referrer, ip, ua, created_at), 8192)
カラム指定の部分については特にMergeTreeと変更はありませんが、エンジンの引数部分がかなり異なっています。
- 第1引数 zookeeper上で情報を保管するパスを指定します テーブル情報は/clickhouse/tables/1-1/rep_access_logに保管されることになります。
{set}はClickhouseのクラスタセット番号を{shard}はシャード番号を表しています。1号機と2号機で全く同じパスになるので、イコール 全く同じデータが入るということになります。 - 第2引数 各ノードを表すための固有の文字列を入れます。とりあえずホスト名を入れとけばいいんじゃないでしょうかということで、
{replica}にホスト名を入れています。 - 第3引数以降 あとはMergeTreeと同じ引数になります
これで、INSERTすると両方のClickHouseに保管されるようになります。また、一気に各日付のテーブルにSELECTを発行するには、MergeTableの際と同じようにMergeエンジンでテーブルを作成すればOKです。ReplicatedMergeはありません。
注意点
zookeeperが稼働し続けることが重要です。そのあたりの冗長性確保をサボると大変なことになりそう。