動機
スクレイピングでやりたいことがあったので、参考記事を読みながら学んで見たいと思う。
参考記事
初心者向けにPythonでWebスクレイピングをする方法をまとめる(侍エンジニア塾)
https://www.sejuku.net/blog/51241
手順
まずは作業用のプロジェクトフォルダを作成。
$ mkdir project
$ cd project
$ mkdir scrapingSyllabus
$ ls
scrapingSyllabus
$ cd scrapingSyllabus
$ pwd
~/project/scrapingSyllabus
かんりょ。
pythonはmac標準搭載なので環境構築は必要なし。
「そういえばpyenvなんて導入してたかなあ」と思い確認。
※pyenv...pythonのバージョン管理ツール。rbenvの姉妹ツール
$ pyenv versions
* system (set by /Users/user/.pyenv/version)
3.6.5
入れてた。
せっかくpyenv入れてるならプロジェクトごとにバージョン管理したいと欲が出る。
とりまpythonのバージョンを最新版にする。
$ pyenv local 3.6.5
$ pyenv versions
system
* 3.6.5 (set by /Users/user/projects/scrapingSyllabus/.python-version)
かんりょ。
pip3でrequestsを入れる。
$ pip3 install requests
Collecting requests
Cache entry deserialization failed, entry ignored
Using cached https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl
Requirement already satisfied: idna<2.8,>=2.5 in /Users/user/.pyenv/versions/3.6.5/lib/python3.6/site-packages (from requests) (2.6)
Collecting urllib3<1.24,>=1.21.1 (from requests)
Cache entry deserialization failed, entry ignored
Using cached https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c53851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl
Collecting chardet<3.1.0,>=3.0.2 (from requests)
Cache entry deserialization failed, entry ignored
Using cached https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl
Collecting certifi>=2017.4.17 (from requests)
Cache entry deserialization failed, entry ignored
Using cached https://files.pythonhosted.org/packages/df/f7/04fee6ac349e915b82171f8e23cee63644d83663b34c539f7a09aed18f9e/certifi-2018.8.24-py2.py3-none-any.whl
Installing collected packages: urllib3, chardet, certifi, requests
Successfully installed certifi-2018.8.24 chardet-3.0.4 requests-2.19.1 urllib3-1.23
Cache entry deserialization failed, entry ignored
You are using pip version 10.0.1, however version 18.0 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
pipが最新版じゃないと怒られた。最新版じゃないと更新できないのか...
指示されたコマンドでアップグレードする。
$ pip install --upgrade pip
Collecting pip
Using cached https://files.pythonhosted.org/packages/5f/25/e52d3f31441505a5f3af41213346e5b6c221c9e086a166f3703d2ddaf940/pip-18.0-py2.py3-none-any.whl
Installing collected packages: pip
Found existing installation: pip 10.0.1
Uninstalling pip-10.0.1:
Successfully uninstalled pip-10.0.1
Successfully installed pip-18.0
おっけ。
満を持してrequestsを入れる。
$ pip3 install requests
Requirement already satisfied: requests in /Users/user/.pyenv/versions/3.6.5/lib/python3.6/site-packages (2.19.1)
Requirement already satisfied: certifi>=2017.4.17 in /Users/user/.pyenv/versions/3.6.5/lib/python3.6/site-packages (from requests) (2018.8.24)
Requirement already satisfied: urllib3<1.24,>=1.21.1 in /Users/user/.pyenv/versions/3.6.5/lib/python3.6/site-packages (from requests) (1.23)
Requirement already satisfied: idna<2.8,>=2.5 in /Users/user/.pyenv/versions/3.6.5/lib/python3.6/site-packages (from requests) (2.6)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /Users/user/.pyenv/versions/3.6.5/lib/python3.6/site-packages (from requests) (3.0.4)
おっけ。
参考記事に沿ってとりま書いてみる。
scrapingSyllabus.pyを作成し、importでrequestsを指定して...
(contentの内容は多すぎるため実行していない)
import requests
r = requests.get('https://news.yahoo.co.jp')
print(r.headers)
print("--------")
print(r.encoding)
# print(r.content)
実行!
$ python scrapingSyllabus.py
{'Date': 'Wed, 12 Sep 2018 14:41:11 GMT', 'P3P': 'policyref="http://privacy.yahoo.co.jp/w3c/p3p_jp.xml", CP="CAO DSP COR CUR ADM DEV TAI PSA PSD IVAi IVDi CONi TELo OTPi OUR DELi SAMi OTRi UNRi PUBi IND PHY ONL UNI PUR FIN COM NAV INT DEM CNT STA POL HEA PRE GOV"', 'X-Content-Type-Options': 'nosniff', 'X-XSS-Protection': '1; mode=block', 'X-Frame-Options': 'SAMEORIGIN', 'Vary': 'Accept-Encoding', 'Content-Encoding': 'gzip', 'Content-Length': '9493', 'Content-Type': 'text/html; charset=UTF-8', 'Age': '0', 'Connection': 'keep-alive', 'Via': 'http/1.1 edge1074.img.bbt.yahoo.co.jp (ApacheTrafficServer [c sSf ])', 'Server': 'ATS', 'Set-Cookie': 'TLS=v=1.2&r=1; path=/; domain=.yahoo.co.jp; Secure'}
--------
UTF-8
出た。
それぞれ取得したいデータを指定してあげるとその情報のみ抜き出すことができる。
headers → ヘッダー
encoding → エンコード情報(UTF-8とか)
content → スクレイピングしてきたhtmlの内容(これが本体)
ひとまず情報が抜き出せたので、今度はbeautifulsoup4をインストール。
$ pip3 install beautifulsoup4
Collecting beautifulsoup4
Downloading https://files.pythonhosted.org/packages/21/0a/47fdf541c97fd9b6a610cb5fd518175308a7cc60569962e776ac52420387/beautifulsoup4-4.6.3-py3-none-any.whl (90kB)
100% |████████████████████████████████| 92kB 1.8MB/s
Installing collected packages: beautifulsoup4
Successfully installed beautifulsoup4-4.6.3
beautifulsoupとは、requestsなどで取ってきたスクレイピングデータを実際に解析するツールです。いわゆるパーサーと呼ばれているものですね。
スクレイピングしてきた生データは、これで整形しなければ使い物になりません。(多分。浅い知識で結構言ってますが間違いがあったらご指摘お願いします...)
武器が揃ったので、とりあえず「Yahoo!ニュース」の「トピック(主要)」のタイトル一覧を取得してみます。
importで2種の神器を指定、ある程度書く。
import requests
from bs4 import BeautifulSoup
html = requests.get('https://news.yahoo.co.jp')
yahoo = BeautifulSoup(html.content, "html.parser")
print(yahoo.select("p.ttl"))
ひとまず実行。
$ python scrapingSyllabus.py
[<p class="ttl"><a href="https://news.yahoo.co.jp/pickup/6296719" onmousedown="this.href='https://news.yahoo.co.jp/pickup/6296719'">被災地 子どもに心のケアを<span class="icVideo">映像</span></a></p>, <p class="ttl"><a href="https://news.yahoo.co.jp/pickup/6296731" onmousedown="this.href='https://news.yahoo.co.jp/pickup/6296731'">路上に箱状の不審物 福岡<span class="icPhoto">写真</span><span class="icNew">new</span></a></p>, <p class="ttl"><a href="https://news.yahoo.co.jp/pickup/6296734" onmousedown="this.href='https://news.yahoo.co.jp/pickup/6296734'">新AppleWatch 心電図を計測<span class="icPhoto">写真</span><span class="icNew">new</span></a></p>, <p class="ttl"><a href="https://news.yahoo.co.jp/pickup/6296729" onmousedown="this.href='https://news.yahoo.co.jp/pickup/6296729'">中部空港 関空被災で混雑続く<span class="icPhoto">写真</span></a></p>, <p class="ttl"><a href="https://news.yahoo.co.jp/pickup/6296727" onmousedown="this.href='https://news.yahoo.co.jp/pickup/6296727'">硫黄島で海底噴火 被害なし<span class="icPhoto">写真</span></a></p>, <p class="ttl"><a href="https://news.yahoo.co.jp/pickup/6296732" onmousedown="this.href='https://news.yahoo.co.jp/pickup/6296732'">滝沢秀明 年内で芸能活動引退<span class="icPhoto">写真</span><span class="icNew">new</span></a></p>, <p class="ttl"><a href="https://news.yahoo.co.jp/pickup/6296733" onmousedown="this.href='https://news.yahoo.co.jp/pickup/6296733'">今井翼が退所 病気治療に専念<span class="icPhoto">写真</span><span class="icNew">new</span></a></p>]
めっちゃ出た。
タイトルだけ抽出したいので、for文を利用してタイトルを一つずつ表示させる。
(結果はリスト型で抽出されているため、for文で回すことができる。)
import requests
from bs4 import BeautifulSoup
html = requests.get('https://news.yahoo.co.jp')
yahoo = BeautifulSoup(html.content, "html.parser")
for title in yahoo.select("p.ttl"):
print(title.getText())
実行してみる。
$ python scrapingSyllabus.py
被災地 子どもに心のケアを映像
路上に箱状の不審物 福岡写真new
新AppleWatch 心電図を計測写真new
中部空港 関空被災で混雑続く写真
硫黄島で海底噴火 被害なし写真
滝沢秀明 年内で芸能活動引退写真new
今井翼が退所 病気治療に専念写真new
出ました。
下が取得元の「Yahho! News」
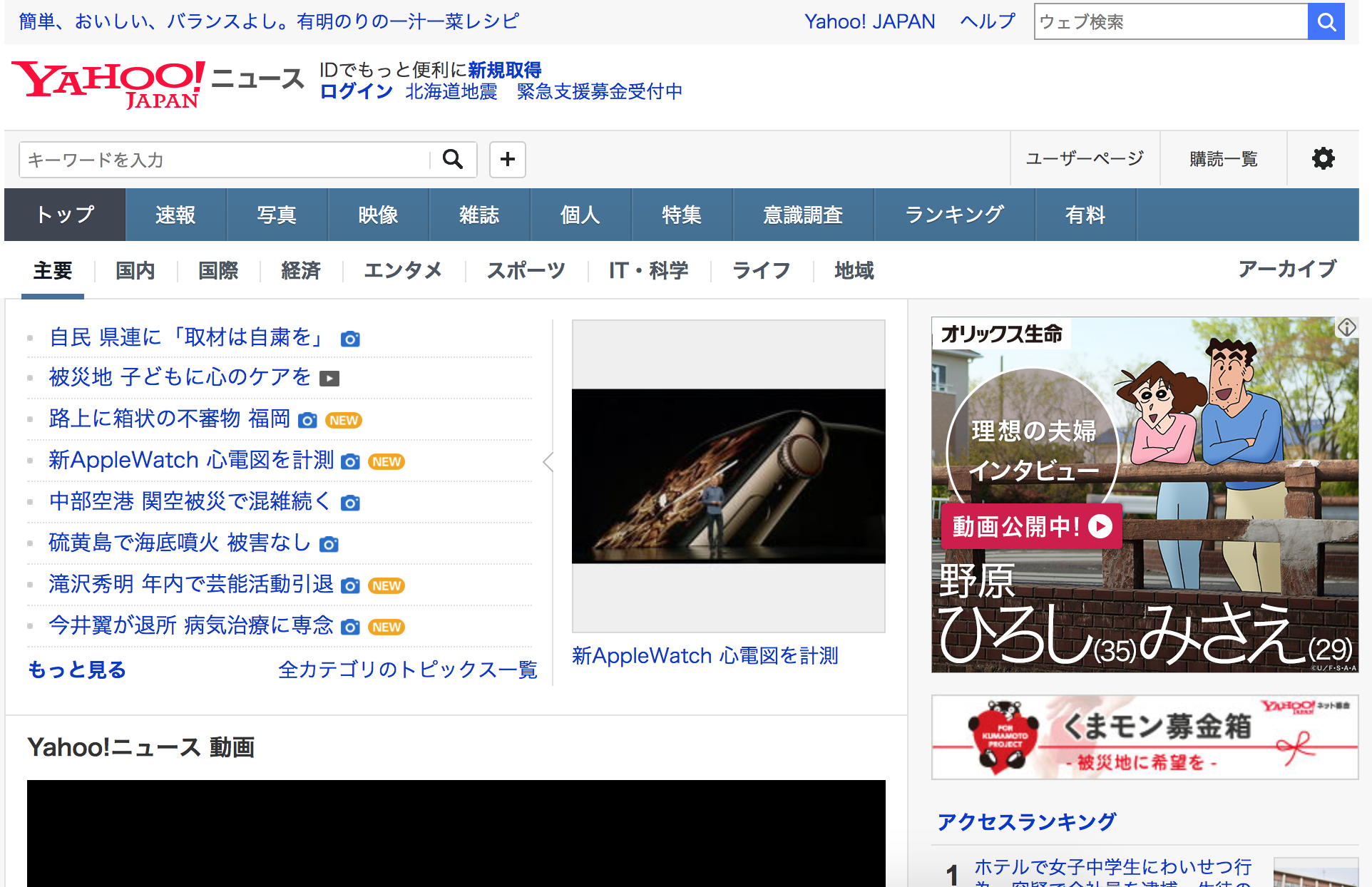
一致している。
ひとまずこれでスクレイピングの基礎は完了。
これでやりたいことがあったんですが、別件で忙しいのでひとまずこれまで...
(ファイルの名前がscrapingSyllabus.pyだったのは、大学のシラバスをスクレイピングしたかったからでした)
ほぼチュートリアルの内容でした。(これ投稿する意味あるのか...?)
「侍エンジニア塾」さんわかりやすい解説を有難うございますっ!