この記事は、Julia Advent Calender2日目の記事です。
概要
11月3日にJuliaデータサイエンスワークショップ - connpassを開催し、Juliaデータサイエンス―Juliaを使って自分でゼロから作るデータサイエンス世界の探索の1章から5章を読んでJuliaに入門してみようというワークショップを行いました。
この記事では、これからこの本を購入しようか迷っている方などに向けて、ワークショップに参加して初めてJuliaを使ってみた感想と、私が担当だった3章(データ探索)において、本のコードが動かなかった箇所や、面白いと思った箇所について書きます。
感想
休日の10時から16時までのワークショップと長時間にもかかわらず、20人弱の方に参加いただき、私が発表の時にはわからない箇所も教えてもらうなど、活況に終わりました。
Juliaの実行速度の速さという魅力に多くの人が興味があるんだなという感想です。とはいうもののまだまだ「一部で人気の言語」という段階であり、今後のv1.0のリリース以降は更に盛り上がると思うのでとても楽しみです。
本(Juliaデータサイエンス)の内容
Juliaデータサイエンスは、Julia for Data Science: Anshul Joshi: 洋書を訳した本であり、1章から5章でJuliaの環境構築や、関数、可視化の方法などを学んだあと、6章から11章で機械学習や深層学習についての内容となっています。よいところと悪いところは、以下のように感じました。
良いところ
- (Julia言語の持ち味かもしれないが)他の言語をかじったことがあれば、理解な記述が多くわかりやすい
- 日本語訳がわかりやすい(主観的な感想ですが、不明なところはない訳でした)
- サンプルコードが上がっている
悪いところ
- サンプルコードがJupyterNotebook形式で上がっていない
- 一部のコードが最新のJuliaのバージョンでは動かない
最新のバージョンで動かないものがあるのは当然なので、全体としてとても良書だと思います。
3章データ探索について
ワークショップで私は、3章を担当したので3章について書いていきます。
ワークショップで使ったコードは、gistにあげたので参照ください。
3章で関心したこと
ヒストグラム(76頁)
ヒストグラムは、以下のコードを書くだけで、こんなに綺麗な図を描くことができまて、感動しました。
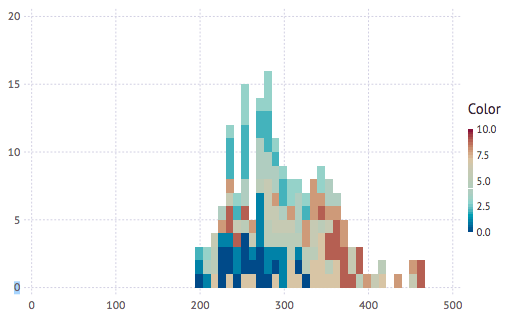
plot(x = sleep[:Reaction],Geom.histogram(bincount = 30), color = sleep[:Days])
3章で動かなかった箇所など
v0.6.1の私の環境では、本のコードで一部動かない箇所や推奨されないと表示された箇所があったので、参考にかいておきます。
Trimmean(61頁)
上位と下位を除いて平均をもとめるtrimmeanは推奨されないと表示されました。今後はuse mean(trim(x,p/2)というように書いて、trim関数で上位と下位を除いてからmean関数で平均をとる方が推奨されるようです。
平均絶対偏差
66頁にmad(a,5)という記載がありますが、mad!(a,5)というように書く必要がありました。
ヒストグラム(75頁)
以下のようにどちらに閉じているか、境界での扱いを指定してやる必要がありました。
# 本のコード
h = fit(Histogram,(rand(100),rand(100)),nbins=10)
# 修正後
h = fit(Histogram,(rand(100),rand(100)),nbins=10,closed=:right)
最後に
Juliaに入門してみた感想を書きました。
Juliaの下手なコードを受け入れてくれる懐の深さはとても魅力に感じているので、もう少し学びたく、今後のアドベントカレンダーの記事をとても楽しみにしています。