概要
ctcの社内FAQについてWord2Vecを用いてあいまい検索できるように実装をしたので、その際の内容を備忘録的にまとめていきます。
見様見まねでやっているので間違っている部分がありましたら申し訳ございません。
背景
社内システムにおけるよくある質問をFAQにして提供しているが、検索は全文一致する必要がありユーザーが希望するFAQにたどり着けないケースがありました。
例えば「スマートフォンのパスコードを忘れた」というFAQを検索したい場合、「スマホ」や「iPhone」といった類義語ではヒットしません。そのため従来はFAQのタグ機能や本文内で関連するワードを入れたりして類義語でもヒットするようにしていたが、FAQ作成者の書き方に依存する部分がありました。
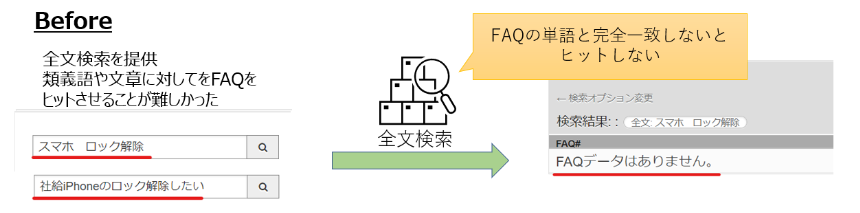
解決策
日本語Wikipediaの文章を学習したWord2Vecを用いてFAQおよび利用者の検索ワードをベクトル化。ベクトルを比較して類似度が高いFAQを表示するアプリを実装しました。
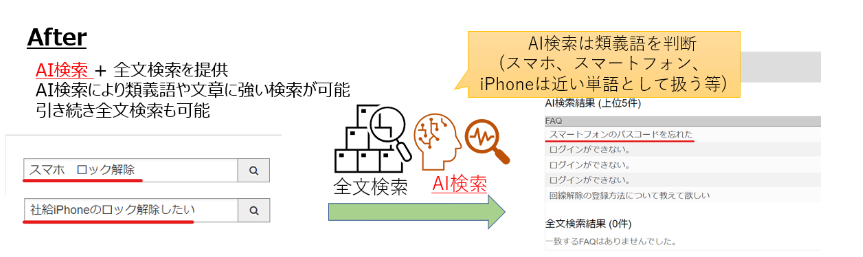
実装イメージ
UIについては従来の検索画面に加え、FAQ利用率向上を狙いチャットボットによる検索画面を問合せフォーム内に表示できるよう開発しました。
実装詳細
-
実行環境
- 言語: Python3.6.8
- OS: CentOS7
- ハード: Celeron G1610T / 4GB RAM
- 退役済のPCを流用。貧弱...
-
概要図
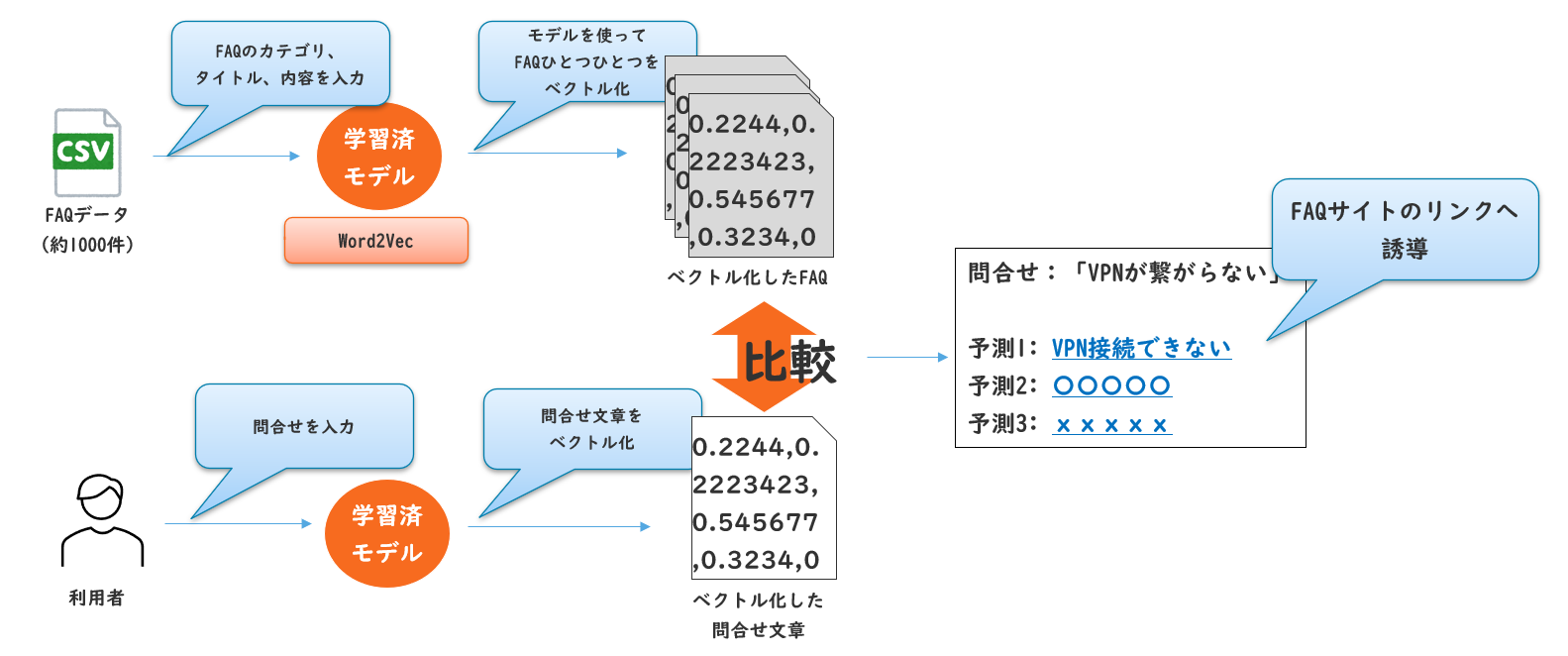
FAQ検索機能とUは分離して開発しました。当初はUIともまとめて一つのアプリで実装をしていましたが、PCスペックの関係でモデルのロードに5分程必要でした。ロードはUI側のプログラム修正でも毎回発生するためAPI化しました。API化により複数のUIで検索機能を使いまわすことができるようになりました。
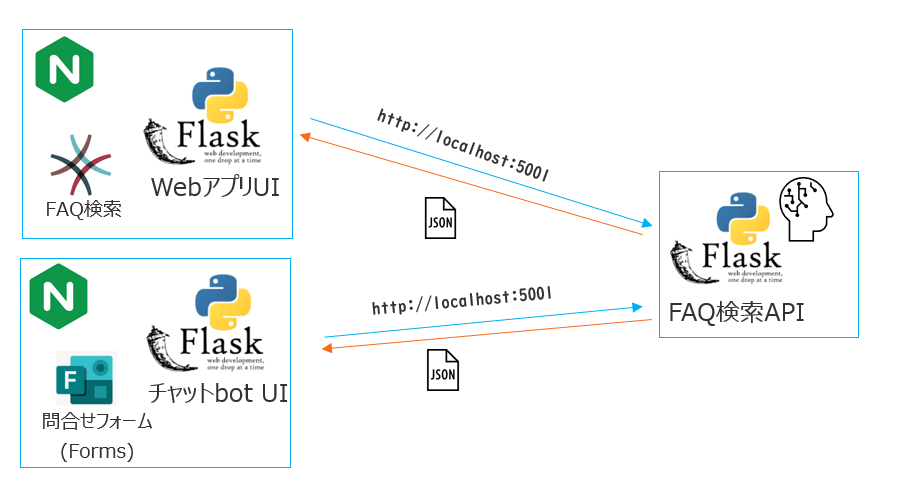
FAQ検索API
モデルは日本語Wikipedia学習済のWord2Vecを利用しました。トークナイザはMeCabを利用。単語ベクトルのプーリングはSWEM(Simple Word-Embedding-based Methods)を実装し、単語ベクトルの平均値を文章ベクトルとするようにしました。以下ざっくりイメージです。
- FAQをCSV形式でエクスポート。1行に1FAQがある状態
- トークナイザでFAQの文章を単語ごとに分割する
- Word2Vecで各単語をベクトル化する
- 単語ごとのベクトルをSWEMで集約してひとつのベクトルにする
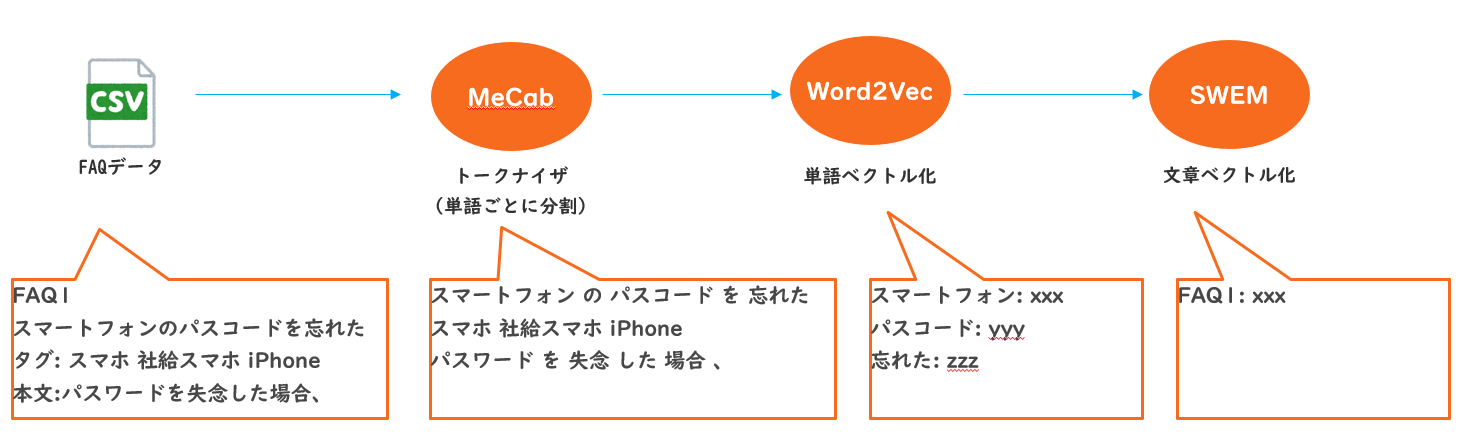
- モデルの読み込み
Word2Vec、MeCabを読み込みします。SWEMの実装についてはこちらのサイトを参考にさせていただきました。
def load_swem_model():
w2v_path = VECTOR_FILE_PATH
w2v = KeyedVectors.load_word2vec_format(w2v_path, binary=False)
tokenizer = MeCabTokenizer('-O wakati')
swem = SWEM(w2v, tokenizer)
return swem
- FAQのベクトル化
CSVエクスポートしたFAQをデータフレームに入れます。試行錯誤の結果ベクトル化する文章はFAQのカテゴリ、タイトル、本文、タグを連結したものを利用しました。SWEMのプーリングは4種類あるが結果的には平均でプーリングした場合の精度が一番よかったのでUI側では平均を利用するように実装しました。
def load_faq_df():
df = pd.read_csv(FAQ_FILE_PATH, encoding='utf-8')
# ベクトル化する列を作成
df['question'] = df['Category'] + ' ' + df['Title'] + ' ' + df['Field1'] + ' ' + df['Keywords']
df['question'].replace('::', ' ', regex=True, inplace=True)
df['question'] = df['question'].str.lower()
# URLの列を作成
df['url'] = 'http://example.com/faq/public.pl?ItemID=' + df['Number'].astype(str).str[1:]
df['text_vector_average'] = df['question'].apply(lambda x: swem.average_pooling(x))
df['text_vector_max'] = df['question'].apply(lambda x: swem.max_pooling(x))
df['text_vector_average_max'] = df['question'].apply(lambda x: swem.concat_average_max_pooling(x))
df['text_vector_hier2'] = df['question'].apply(lambda x: swem.hierarchical_pooling(x, n=3))
return df
- FAQと検索ワードの比較
ベクトル化したすべてのFAQとベクトル化した検索ワードのコサイン類似度を計算します。コサイン類似度が高い=文章が似ていると判断するようにしています。
def _calc_cossim(x, y):
return np.dot(x,y)/(np.linalg.norm(x)*np.linalg.norm(y))
def get_all_prob(word, df):
y_average = np.array(swem.average_pooling(word))
y_max = np.array(swem.max_pooling(word))
y_average_max = np.array(swem.concat_average_max_pooling(word))
y_hier2 = np.array(swem.hierarchical_pooling(word, n=3))
df['prob_average'] = df['text_vector_average'].apply(_calc_cossim, y=y_average)
df['prob_max'] = df['text_vector_max'].apply(_calc_cossim, y=y_max)
df['prob_average_max'] = df['text_vector_average_max'].apply(_calc_cossim, y=y_average_max)
df['prob_hier2'] = df['text_vector_hier2'].apply(_calc_cossim, y=y_hier2)
return df[['Number', 'url', 'Category', 'Title', 'prob_average', 'prob_max', 'prob_average_max', 'prob_hier2']]
- Flask
クエリパラメータで受けた検索ワードを受け取ってFAQと検索ワードの比較を行い、コサイン類似度が高いもの上位5件をjsonで返すようにしています。
@app.route('/api/faq-ai-search', methods=["GET"])
def api_faq_ai_search():
try:
req = request.args
inputtext = req.get('query')
if inputtext == None:
raise
tmp_df = get_all_prob(inputtext, faq_df)
top5_df = tmp_df.sort_values('prob_average', ascending=False).head(5).reset_index()
app.logger.info('type="AI" input="%s", result="%s"', inputtext, top5_df['Title'].head(1).to_string())
return jsonify(top5_df.to_dict())
except:
return jsonify('error')
- 検索結果例(json)
検索ワード: 「スマホ ロック解除」
検索ワードに近いFAQが選ばれているように見えます
※結果について非公開な内容もあったため一部マスクしています。
{
"Category": {
"0": "端末・設備::スマートフォン関連::故障・紛失・ロック解除",
"1": "端末・設備::スマートフォン関連",
"2": "端末・設備::スマートフォン関連",
"3": "端末・設備::パソコン関連",
"4": "xxxxxxxxxxx"
},
"Number": {
"0": 100242,
"1": 1001098,
"2": 100579,
"3": 100668,
"4": 100116
},
"Title": {
"0": "スマートフォンのパスコードを忘れた",
"1": "iPhoneが固まって操作を受け付けない。再起動したい。",
"2": "社給スマートフォンからxxxxxxxxxxxxにSSOサインインできない",
"3": "xxxxxxxxxxxxのバージョンアップ方法について",
"4": "xxxxxxxxxxxx"
},
"index": {
"0": 232,
"1": 1082,
"2": 568,
"3": 655,
"4": 106
},
"prob_average": {
"0": 0.8004410896560629,
"1": 0.7710547598937089,
"2": 0.7629554308402817,
"3": 0.7560575784110765,
"4": 0.7531497331172312
},
"prob_average_max": {
"0": 0.8300873187920826,
"1": 0.823325646286283,
"2": 0.8063060429023359,
"3": 0.8163334508047796,
"4": 0.8315589117985464
},
"prob_hier2": {
"0": 0.726790248245966,
"1": 0.7119361336639003,
"2": 0.6716707290055255,
"3": 0.719479541743257,
"4": 0.7562184195394666
},
"prob_max": {
"0": 0.8494470615430099,
"1": 0.8453928808063947,
"2": 0.8329228898130551,
"3": 0.835537396594874,
"4": 0.8492473662249758
},
"url": {
"0": "http://example.com/faq/public.pl?ItemID=00242",
"1": "http://example.com/faq/public.pl?ItemID=001098",
"2": "http://example.com/faq/public.pl?ItemID=00579",
"3": "http://example.com/faq/public.pl?ItemID=00668",
"4": "http://example.com/faq/public.pl?ItemID=00116"
}
}
WebアプリUI
リクエストを受けた際、FAQ検索APIで検索し結果を表示させています。
@app.route('/')
def get_request():
value = request.args.get('query', '')
print(value)
ai_search_url = FAQ_AI_API_URL + value
fulltext_search_url = FAQ_FULLTEXT_API_URL + value
# AI検索
try:
res = requests.get(ai_search_url)
ai_df = pd.read_json(res.content)
app.logger.info('type="AI" input="%s", result="%s"', value, ai_df['Title'].head(1).to_string())
ai_result = ai_df.values.tolist()
except:
ai_result = None
return render_template('result.html.j2',
query=value,
ai_result=ai_result,
fulltext_result=fulltext_result
)
FAQ検索APIから受け取った結果を表示しています。
<h3>AI検索結果 (上位5件)</h3> {% if ai_result is none %}
<p> AI検索出来ませんでした。もう少し長い文章や複数単語を指定ください (例: VPNに接続できない) </p> {% else %}
<div class="Content">
<table class="Overview">
<thead>
<tr>
<th>FAQ</th>
<th>カテゴリー</th>
<th>類似度</th>
</tr>
</thead>
<tbody> {%- for i in ai_result %}
<tr>
<td><a href="{{ i[8] }}&search-type=ai">{{ i[2] }}</a></td>
<td>{{ i[0] }}</td>
<td>{{ i[4]|round(3)*100 }}%</td>
</tr> {%- endfor %} </tbody>
</table>
</div> {% endif %}
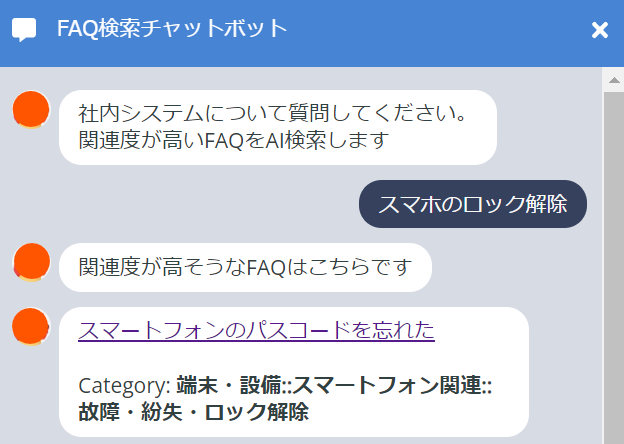
チャットボットUI
チャットボットのUIはチャットUIライブラリchatuxを利用して実装しました。chatuxは以下のようなシンプルなhtmlでendpointのWebアプリサーバーが所定のjsonを返すことでチャットボットを作成することができます。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1">
<title>情シスFAQ</title>
</head>
<body>
<script src="https://riversun.github.io/chatux/chatux.min.js"></script>
<script>
const chatux = new ChatUx();
const initParam =
{
renderMode: 'mobile',
buttonOffWhenOpenFrame: true,
api: {
endpoint: 'http://example.com/api/faqchat',
method: 'GET',
dataType: 'jsonp'
},
bot: {
wakeupText: '社内システムについて質問してください。<br>関連度が高いFAQをAI検索します',
botPhoto: 'https://example.com/image.png',
humanPhoto: null,
widget: {
sendLabel: '送信',
placeHolder: 'お問合せ内容を入力してください。(例: VPNに繋がらない)'
}
},
window: {
title: 'お問い合わせ',
infoUrl: 'http://example.com/'
}
};
chatux.init(initParam);
chatux.start(true);
</script>
</body>
</html>
endpointのプログラム抜粋
# FAQ検索APIへリクエストして結果を返す部分
url = FAQ_API_URL + value
callback = request.args.get('callback', '')
try:
res = requests.get(url)
faq_df = pd.read_json(res.content)
dic = get_answer_dic(faq_df.head(5))
contents = callback + '(' + json.dumps(dic) + ')'
app.logger.info('input="%s", result="%s"', value, faq_df['Title'].head(1).to_string())
return contents
# FAQ回答結果を作る部分
def get_answer_dic(df):
dic = {}
ans_list = []
# 最初のメッセージ
ans_list.append({'type': 'text', 'value': '関連度が高そうなFAQはこちらです'})
# FAQ回答
for _, row in df.iterrows():
tmp_dic = {}
tmp_dic['type'] = 'text'
tmp_dic['value'] = f'<a href="{row["url"]}&search-type=ai" target="_blank">{row["Title"]}</a><br><br>Category: <b>{row["Category"]}</b>'
tmp_dic['delayMs'] = 200
ans_list.append(tmp_dic)
# YES/NOボタン
ans_list.append({'type': 'text', 'value': 'こちらのFAQで問題解決できましたでしょうか?', 'delayMs': 1000})
option_list = []
option_list.append({'label': '解決した', 'value': YES_RESPONSE})
option_list.append({'label': '解決しなかった', 'value': NO_RESPONSE})
ans_list.append({'type': 'option', 'options':option_list})
dic['output'] = ans_list
return dic
今後取り組みたい内容
まだまだ検索精度が低いので新しいモデルを用いて精度向上ができるか確認をしたいです(ただ今の環境でDoc2VecやBertを動かしたりは厳しそう)。モデル変更以外でもチャットボット内でカテゴリ絞らせる等で精度向上ができる部分もあると思うので試していきたいです。
参考サイト