この記事はOUCC(大阪大学コンピュータークラブ)Advent Calender 2020の12月23日の記事です
#初めに
「CNNについてはある程度理解したけど実装ってどうすればええんや?」といった部員に向けてKerasを用いてCNNモデルの構築、学習を行い、実際に画像分類を行うことで「CNN完全に理解した(エンジニア用語)」という風になってもらいます。
今回は画像のデータセットを入手して機械学習を行うための前処理をします。
Pythonの環境が整ってない方やPCにGPUが入ってない方向けに今回はGoogle Colaboratory というものを用います。
※Google Colaboratory の使用の際にGoogleアカウントが必要となります。
この記事の内容を要約すると、「画像認識で「綾鷹を選ばせる」AIを作る」のn番煎じなので、元記事に興味のある方はそちらへ行ってください。
#目次
[1]概要
[2]Google Drive から Google Colaboratory を使えるようにする。
[3]データセットを取得する
[4]データセットの前処理を行う
#[1]概要
以下の手順で行います
(1)Google Drive から Google Colaboratory を使えるようにする。
(2)用いる画像をサイトからダウンロードし、ドライブに保存する。
(3)画像を学習・検証データに分けて前処理を行いnumpyファイルで保存する。
#[2]Google Drive から Google Colaboratory を使えるようにする。
一般的な方法だとGoogle Drive で右クリック>「その他」>「アプリを追加」でGoogle Colaboratory を検索して追加するのですが、なぜか検索しても出てこないので別の方法で行います。
まずはGoogle 上で「Google Colaboratory」と検索して「Colaboratory - Google Colab」をクリックします。(以下画像参照)
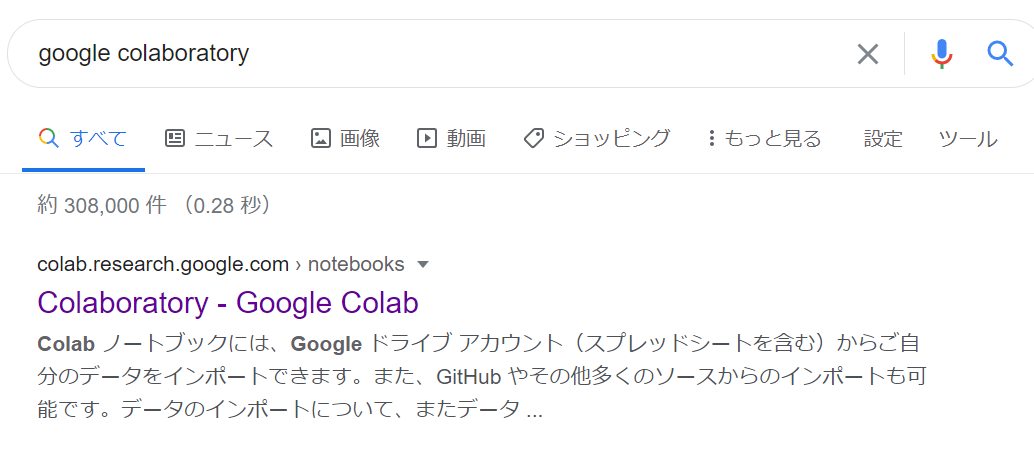
開くと以下の画像のようなものが出てくると思いますので左上の「ドライブにコピー」をクリックします。
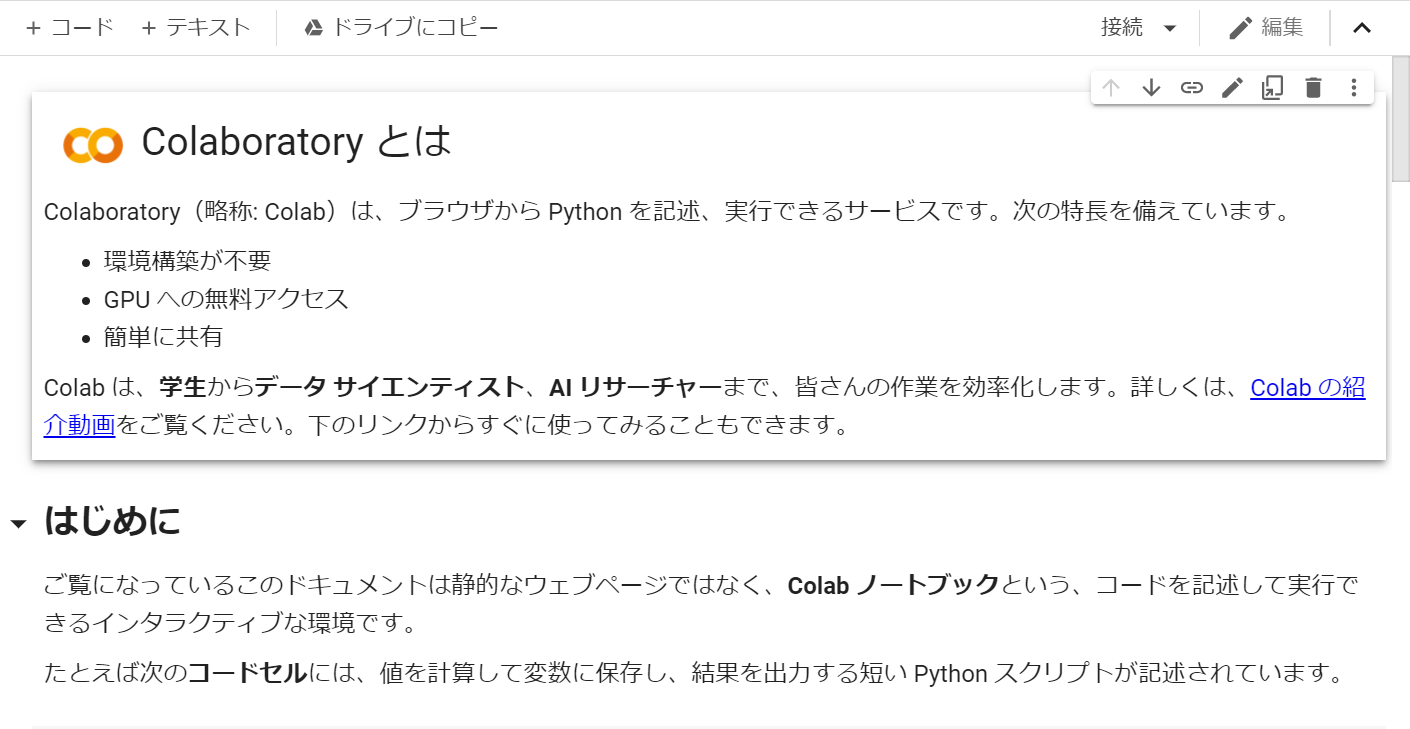
そしてGoogle Drive に戻って任意の空白部分を右クリックして「その他」の欄にGoogle Colaboratory が入っていれば Google Drive から Google Colaboratory が使えるようになります。

また、「ドライブにコピー」を選択しましたので「Colab Notebooks」なるものがドライブに作成されますが削除していただいて結構です。
#[3]データセットを取得する
今回はスタンフォード大学が公開している犬のデータセットをお借りしました。
Stanford Dogs Dataset
このデータセットは120種類もの犬種カテゴリーで構成されており、今回はその中から以下の4品種のデータセットを用いました。
・Pomeranian(ポメラニアン)
・Pembroke(ペンブローク)
・Dhole(ドール)
・African hunting dog(リカオン)
取得方法としては、上記URLからデータセットをダウンロード・解凍し、Google Drive の「マイドライブ」>「画像分類」>「画像」という2つのフォルダを作成して「画像」フォルダに上記4つの品種のデータセットをアップロードします。

#[4]データセットの前処理を行う
まずは「マイドライブ」>「画像分類」に前処理を行う用のプログラムファイル「画像_前処理.ipynb」を作成します。全体の内容は以下のようになっています。
#ラベリングによる学習/検証データの準備
import os, glob
import numpy as np
import random, math
from PIL import Image
#Google Driveにアクセスできるようにする
from google.colab import drive
drive.mount('/content/drive')
#画像フォルダが保存されているルートディレクトリのパス
import glob,os
path = "/content/drive/My Drive/画像分類/画像"
categories = os.listdir(path)
#すべての画像データを格納するリスト
allfiles = []
#allfilesに[品種ごとのidx,画像のパス]という形で画像データを格納する
for idx, category in enumerate(categories):
image_dir = path + "/" + category
#使用する画像の保存形式によって変える(今回はjpgの画像を使用)
files = glob.glob(image_dir + "/*.jpg")
for file in files:
allfiles.append((idx, file))
#画像データごとにadd_sample()を呼び出し、X,Yのリストを返す関数
def make_sample(files):
global X, Y
X = []
Y = []
for category, fname in files:
add_sample(category, fname)
return np.array(X), np.array(Y)
#各画像データを(250,250)のサイズにしたあとNumpy配列に変えてXに格納する関数
def add_sample(category, fname):
#画像を取り出す
img = Image.open(fname)
#RGBに変換する
img = img.convert("RGB")
#画像のサイズを変換する
img = img.resize((250, 250))
#Numpy配列に変換する
data = np.asarray(img)
#リストに加える
X.append(data)
Y.append(category)
#シャッフルする
random.shuffle(allfiles)
#allfilesの前8割を訓練データ、残りを検証データに分ける
th = math.floor(len(allfiles) * 0.8)
train = allfiles[0:th]
test = allfiles[th:]
#make_sample関数を用いてデータを作成する
X_train, y_train = make_sample(train)
X_test, y_test = make_sample(test)
#作成した訓練・評価用データをまとめる
xy = (X_train, X_test, y_train, y_test)
#データを保存する(データの名前を「dogs_data.npy」としている)
np.save("dogs_data.npy", xy)
データセットの前処理の手順としては、
①画像のパスを取得する
②画像を処理する関数を作成する
③訓練データと評価データを作成して、.npyファイルで保存する
となっております。
それではプログラムの内容を見ていきましょう
##①画像を取り込む
#ラベリングによる学習/検証データの準備
import os, glob
import numpy as np
import random, math
from PIL import Image
#Google Driveにアクセスできるようにする
from google.colab import drive
drive.mount('/content/drive')
#画像フォルダが保存されているルートディレクトリのパス
import glob,os
path = "/content/drive/My Drive/画像分類/画像"
categories = os.listdir(path)
#すべての画像データを格納するリスト
allfiles = []
#allfilesに[品種ごとのidx,画像のパス]という形で画像データを格納する
for idx, category in enumerate(categories):
image_dir = path + "/" + category
#使用する画像の保存形式によって変える(今回はjpgの画像を使用)
files = glob.glob(image_dir + "/*.jpg")
for file in files:
allfiles.append((idx, file))
まずはdrive.mount('/content/drive')を実行するとアカウントを認証するためのURLが表示されます。URLをクリックして使用するアカウントを選択→表示されるコードをGoogle Colaboratoryに表示されているテキストボックスに入力すると認証が完了します。
次に画像フォルダにある種類別の各画像データをallfilesに「品種ごとのidx,画像のパス」といった感じに格納します。
##②画像の処理をする関数を作成する
#画像データごとにadd_sample()を呼び出し、X,Yのリストを返す関数
def make_sample(files):
global X, Y
X = []
Y = []
for category, fname in files:
add_sample(category, fname)
return np.array(X), np.array(Y)
#各画像データを(250,250)のサイズにしたあとNumpy配列に変えてXに格納する関数
def add_sample(category, fname):
#画像を取り出す
img = Image.open(fname)
#RGBに変換する
img = img.convert("RGB")
#画像のサイズを変換する
img = img.resize((250, 250))
#Numpy配列に変換する
data = np.asarray(img)
#リストに加える
X.append(data)
Y.append(category)
ここでは画像の前処理を行っています。内容は上記コメントの通りですが、大まかな感じとしては、make_sampleでfiles内の各画像パスにつきaddsampleを呼び出す→addsampleで画像の取得・処理を行いX,Yに加える→最後にmake_sampleでX,Yを出力する、という感じになっています。
##③訓練データと評価データを作成し、.npyファイルで保存する
ここではいよいよ評価用データと訓練用データを作成します。コードは以下の通りです。
#シャッフルする
random.shuffle(allfiles)
#allfilesの前8割を訓練データ、残りを検証データに分ける
th = math.floor(len(allfiles) * 0.8)
train = allfiles[0:th]
test = allfiles[th:]
#make_sample関数を用いてデータを作成する
X_train, y_train = make_sample(train)
X_test, y_test = make_sample(test)
#作成した訓練・評価用データをまとめる
xy = (X_train, X_test, y_train, y_test)
#データを保存する(データの名前を「dogs_data.npy」としている)
np.save("dogs_data.npy", xy)
※この処理は3分ほどかかります。
allfilesの中身をシャッフルした後に前8割を訓練データ、残りを検証データに分けます。そして先ほど作成したmake_sample関数を用いてX_train,y_train,X_test,y_testを作成し、それらを.npyファイルに保存します。
作成後はGoogle Colaboratoryの右側のフォルダマークをクリックすると、作ったファイルがあるのでダウンロードしましょう(ダウンロードに数分かかります)。
ダウンロード後は「マイドライブ」>「画像分類」にファイルをアップロードしましょう。
保存することでデータセットを毎回作るという手間を省くことができます。
以上で前処理編は終了となります。
次はGoogle Colab で画像分類(機械学習編)です。(coming soon)