Google Cloud Vision APIを使って物体検出などを行いたいとき、Google Drive + Google Colaboratoryを使うとブラウザ上で全ての作業を完結できてとても便利。
Google Colaboratoryのノートブックを作る
で、「PYTHON 3の新しいノートブック」を作成する。
Cloud Vision用のpipをインストールする
Cloud Vision APIを使う場合はpipをインストールする必要がある。インストール後にRestartを求められるため、このステップはノートブックの一番最初にやっておくのが良い。
!pip install --upgrade google-cloud-vision
ランタイムのRestartを求められたらRestartする。

Google Driveに画像をアップロードする
Google Driveに新しいフォルダを作成して、その中に解析したい画像を突っ込む。

ノートブック上でファイル指定でアップロードしたり、Google Cloud Storageから画像をダウンロードさせたりすることもできるが、複数画像を手軽に試すならGoogle Driveが一番手軽だと思う。
Google Driveをマウントする
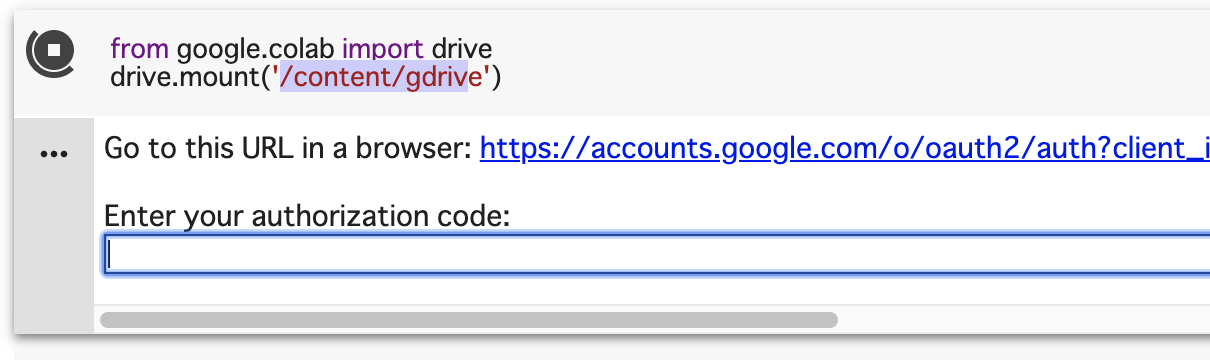
from google.colab import drive
drive.mount('/content/gdrive')
drive.mountをすると、Google Driveの内容を指定したパスにマウントでき、プログラム内からファイルとして参照できるようになる。
認証する
初回実行時は認証を求められる。ブラウザでリンクを開いて認証をしたら、最後に表示される認証コードをNotebook側のテキストフィールドに打ち込んでエンターを押す。
ディレクトリ内の画像ファイルのリストを取得する
import glob
src_files = glob.glob('/content/gdrive/My Drive/visiontest/*.jpg')
src_files.sort()
for f in src_files:
print(f)
上でマウントしたパスを利用して、先ほどアップロードしたjpgファイルの一覧を取得してみる。ログにファイルの一覧が表示されない場合はパスか何かが間違っているので確認する。
Cloud Vision APIを叩く
Cloud Vision APIを有効にする
Google Cloud Consoleを開いて、「APIとサービス」からCloud Vision APIを有効にする。プロジェクトが存在しない場合は、新しくプロジェクトを作成する。なお、Cloud Vision APIは有料のAPIなので支払い設定を完了させないと正しく叩くことができないので注意。
サービスアカウントキーを作る
「認証情報」からAPIを叩くためのサービスアカウントキーを作成する。作成されたJSONファイルをGoogle Driveの先ほどのディレクトリにアップロードする。ここではcredentials.jsonという名前でアップロードした。
アップロード先のディレクトリがpublicに共有されていないことを確認すること。このサービスアカウントキーが外部に流出すると、APIを叩かれてトラブルにつながるリスクがあるので扱いには十分注意する。もっと安全な方法で管理したいが、現状ではGoogle Colab上で使う場合は特別安全な方法が存在しない模様。Google Driveにアップロードするのが不安な場合は、file.uploadを使って実行時に都度アップロードする方式を検討してください。
サービスアカウントキーファイルを読み込む
import os
import os.path
import errno
from googleapiclient import discovery
from oauth2client.client import GoogleCredentials
cred_path = '/content/gdrive/My Drive/visiontest/credentials.json'
if os.path.exists(cred_path) == False:
raise FileNotFoundError(errno.ENOENT, os.strerror(errno.ENOENT), cred_path)
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = cred_path
サービスアカウントキーファイルを読み込む。ファイルが存在しない場合はエラーを発生させて処理が先に進まないようにしている。
物体検知をする
フォルダ内の画像一枚一枚に対して、物体検出のAPIを叩き、結果をobjectsディクショナリーに保存する。Cloud Vision APIは有料なので、試行錯誤の過程で無駄に叩いてしまうことのないように、結果をキャッシュして後から参照する形にした方が良い。
import io
from google.cloud import vision
from google.cloud.vision import types
objects = {}
client = vision.ImageAnnotatorClient()
for file in src_files:
with io.open(file, 'rb') as image_file:
content = image_file.read()
image = types.Image(content=content)
res = client.object_localization(
image=image).localized_object_annotations
objects[file] = res
実行結果を表示する
from matplotlib import pyplot as plt
from PIL import Image
from PIL import ImageDraw
def draw_object_boxes(f, objects):
im = Image.open(f)
w, h = im.size
draw = ImageDraw.Draw(im)
for obj in objects:
color = '#ffff00'
box = [(v.x * w, v.y * h) for v in obj.bounding_poly.normalized_vertices]
xs = [(v.x * w) for v in obj.bounding_poly.normalized_vertices]
ys = [(v.y * h) for v in obj.bounding_poly.normalized_vertices]
draw.line(box + [box[0]], width=20, fill=color)
return im
for file in files:
plt.figure(figsize=(5,3))
plt.imshow(draw_object_boxes(file, objects[file]))
plt.show()