はじめに
画像認識をする方法であったり、APIといったものが最近になって多く出てくるようになりました。ただ、こんな悩みはないでしょうか?Azure, GCP, Watsonなどなど多くのサービスがありすぎて把握しきれない!
自分自身もそのように感じている部分は多くあるのですが、今回はGoogleのVision APIに焦点をあて、どのような機能があるのか?11つの機能をまとめてみました!
VisionAPIとは?
Googleのサービスの一つで、画像の解析を行うAPIの一つです。
Googleがもつ画像系のAIのサービスですと、大きく分けて2つ存在しますが、1つは今回紹介するVision API、もう一つはAutoML Visionというものです。
前者は事前にトレーニング済みのモデルを学習するため、学習が不要。
後者は独自にカスタムしたモデルを学習させることができるため、前者に比べてひと手間かかりますが、汎用的に使えるようになるといったものです。
詳しくは、このリンクを見てもらえればと思います。ただ、そうはいっても量が多くて全体を読むのはちょっと...、画像処理って、そんなに種類あるの?という人には、是非この記事を読み進めてもらえたらと思います!
VisionAPIの機能は10種類以上!
画像処理といっても、何に特化しているか、どのような情報を返すかによって種類が多く存在します。詳しくはこの後1つずつ紹介していきますが、いくつか例をあげますと、画像に写っている文章の抽出や顔の検出(顔のパーツの位置も含めて)、写真のコンテンツとしての適切性、画像に写っているものに関する情報をwebの情報を参照しながらその画像に似ている画像だったり、どのような画像なのか推測した結果を返してくれたりといった機能まであります。
このリンクから下の画像のUpload your imageの部分に画像をアップロードするだけで、デモが試せるので興味がある方はやってみてください!
visionAPIでできること
画像の解析ができるVison API でありますが、画像解析と一言で言っても多岐にわたる解析対象があります。
そこで、ここではVision APIではどのような解析ができるのかについて紹介します! (さらに詳しい部分はvision APIのドキュメントに書いてありますのでそちらを参照していただけたらと思います!)
1. CROP_HINTS
画像をクロップ(切り抜く)とき、どの領域を切り抜けばよいかを教えてくれる機能です。下の2枚目の画像は、1枚目の写真をこのCROP_HINTを元に切り抜いた画像です。
使い方は簡単で、リクエストとしてクロップしたい縦横の比率(アスペクト比)を指定するだけです!

https://cloud.google.com/vision/docs/images/china1_small.jpeg?hl=ja

https://cloud.google.com/vision/docs/images/china1_crop_small.png?hl=ja
レスポンスとしては、
- boundingPoly : バウンディングボックスの四隅の点のx,y座標 ((12,42),(439,42),(439,285),(12,285))
2. DOCUMENT_TEXT_DETECTION
文書内のテキストを検出
この機能では画像内からテキストを検出、抽出することができます。似たような機能として、この後に説明するTEXT_DETECTIONという機能がありますがそちらは汎用的なテキスト検出用のものである一方、こちらは高密度のテキストなどの文書に特化しているという特徴があり、ページやブロックだけでなく、段落や単語、改行などの情報もJSON形式で返ってきます。
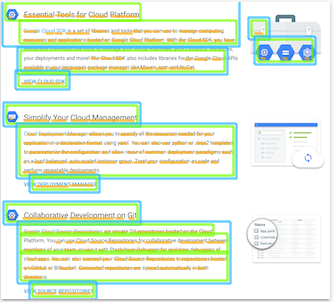
レスポンスとしては、
- locale : 認識した言語の言語コード(en,jaなど)
- description : 認識した言葉(文章)
- boundingPoly : 認識した言葉が位置するバウンディングボックスの四隅の点のx,y座標 ((12,42),(439,42),(439,285),(12,285))
- text : 文章の全文
3. FACE_DETECTION
顔の検出
画像に含まれる複数人の顔を検出します。顔の位置はもちろん、感情や顔のパーツの位置など様々な顔に関する属性情報も取得することができます!
下の画像は、左の画像をこのFACE_DETECTIONに通した結果です。

レスポンスとしては、
- boundingPoly : 顔が位置するバウンディングボックスの四隅の点のx,y座標 ((12,42),(439,42),(439,285),(12,285))
- landmarks : 顔のランドマークの位置 (x,y,z座標でzは奥行きを表す)
ランドマークの種類としては、左目・右目、眉毛の左端・右端・上端中央(左右それぞれ)、目の間の中間点、鼻の先端、上唇・下唇、口の左端・右端・中央、鼻の右下・左下・中央の下、目の上端・下端・左端・右端(左右それぞれ)、耳、瞳(左右それぞれ)、眉間、下唇の下端・左端・右端の 全34つのパーツである
- Angle : roll,pan(ヨー), till(ピッチ)角を表す
- detectionConfidence : 顔検知の信頼度
- landmarkingConfidence : 顔のランドマークの検知に対する信頼度
- Likehood : 各感情(喜び、悲しみ、怒り、驚き)の度合いや肌の露出やぼやけ、帽子をかぶっているか否かに対する度合いを表す
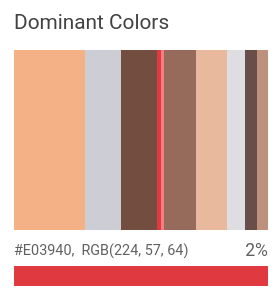
4. IMAGE_PROPERTIES
この機能では、ドミナントカラーなどの領域内の色や、画像内での一般的な特性を検出するものです。
1枚目の写真を入力として、この機能を用いたのが2枚目の画像になります。画像内で使われている色や配色が反映されていますよね!

https://cloud.google.com/vision/docs/images/bali_small.jpeg?hl=ja
https://cloud.google.com/vision/docs/images/bali_colors.png?hl=ja
レスポンスとしては、
- color : RGB表記でそれぞれの値
- score : 信頼スコア
- pixcelFraction : 画像全体に占める該当色が占める割合
これに加えて、CropHintについてのレスポンスもあり、
- boundingPoly : バウンディングボックスの四隅の点のx,y座標 ((12,42),(439,42),(439,285),(12,285))
- confidence : CropHintの信頼度
- importance Fraction : 画像に対するクロップした領域の重要度
5. LABEL_DETECTION
ラベルの検出
画像に含まれる物体だけでなく、場所や活動、動物、商品など幅広いカテゴリを識別することが可能。
下の画像の入力からは、
街路やスナップショット、町、夜、路地などを読み取ることができ、画像から特定の物体だけでなく、背景としての要素も抜き出すことができることがわかる。

https://cloud.google.com/vision/docs/images/setagaya_small.jpeg?hl=ja
レスポンスとしては、
- mid : MID値 (/m/01c8br)
- description : 検出物の名前 (Street,Snapshot,Town など)
- score : 信頼スコア
- topicality : 画像における、ある物体における重要度や関連度
(公式ドキュメントによると、画像に対する ICA(Image Content Annotation)ラベルの関連度。)
6. LANDMARK_DETECTION
ランドマークの検出
ランドマークの検出では、有名な人工建造物であったり、自然のランドマークなどを画像から検出するといったものです。
また、これはランドマークの識別やバウンディングボックスの表示だけでなく、ランドマークがどこにあるか?を緯度・経度で返してくれます!なので、Google Mapと組み合わせて画像の場所はどこにあるのか?といった情報まで結びつけられるかもしれませんね!

レスポンスとしては、
- description : ランドマークの名前(Saint Basil's Cathedral)
- score :信頼スコア (0.980325)
- boundingPoly : バウンディングボックスの四隅の点のx,y座標 ((12,42),(439,42),(439,285),(12,285))
- mid : MID値(/m/045c7b)
*latLng : ランドマークのある緯度・経度
7. LOGO_DETECTION
ロゴの検出
よく知られている企業だったり、商品のロゴを画像から検出するという物です。
下の例だと、Googleの「ロゴ」を検出していて、バウンディングボックスも表示していますね!

レスポンスとしては、
- description : ロゴ名(Google)
- score :信頼スコア (0.980325)
- boundingPoly : バウンディングボックスの四隅の点のx,y座標 ((12,42),(439,42),(439,285),(12,285))
- mid : MID値(/m/045c7b)
8. OBJECT_LOCALIZATION
画像の複数の物体に対して物体の識別の場所の特定を行うことができる。4,7のラベルやロゴのでは、対象物の識別のみで合ったが、この機能は画像内のどこに対象物があるかの情報まで識別することができる。

レスポンスとしては、
- name : 検出物の名前(Bicycle)
- score :信頼スコア (0.980325)
- boundingPoly : バウンディングボックスの四隅の点のx,y座標 ((12,42),(439,42),(439,285),(12,285))
- mid : MID値(/m/045c7b)
9. SAFE_SEARCH_DETECTION
不適切なコンテンツを検出(セーフサーチ)
画像の要素として不適切なものがないかを判定するものである。
5つのカテゴリがあり、adult, spoof, medical, violence, racyの面から適切度合いを5段階で分けられ、「VERY_LIKELY」、「LIKELY」、「POSSIBLE」、「UNLIKELY」、「VERY_UNLIKELY」または判別できない場合は「UNKNOWN」と分類される
レスポンスとしては、
1つの画像に対して5つのカテゴリでの適切度合いが返ってくる。
10. TEXT_DETECTION
テキストを検出
この機能では、画像内に含まれるテキスト(文章)を検出するものである。
似たような機能でDOCUMENT_TEXT_DETECTIONがありましたがこれは高密度のテキストやドキュメントなどの文書からの画像認識を行なっているのに対し、TEXT_DETECTIONでは、任意の画像からテキストを抽出することができます!
ですので、下の画像のように標識から文字を認識するといったこともできていますね〜 文書を読み取るという目的ではなく、写真に写っている文字を読み取りたい時に良さそうですね!

レスポンスとしては、
- locale : 認識した言語の言語コード(en,jaなど)
- description : 認識した言葉(文章)
- boundingPoly : 認識した言葉が位置するバウンディングボックスの四隅の点のx,y座標 ((12,42),(439,42),(439,285),(12,285))
- text : 文章の全文
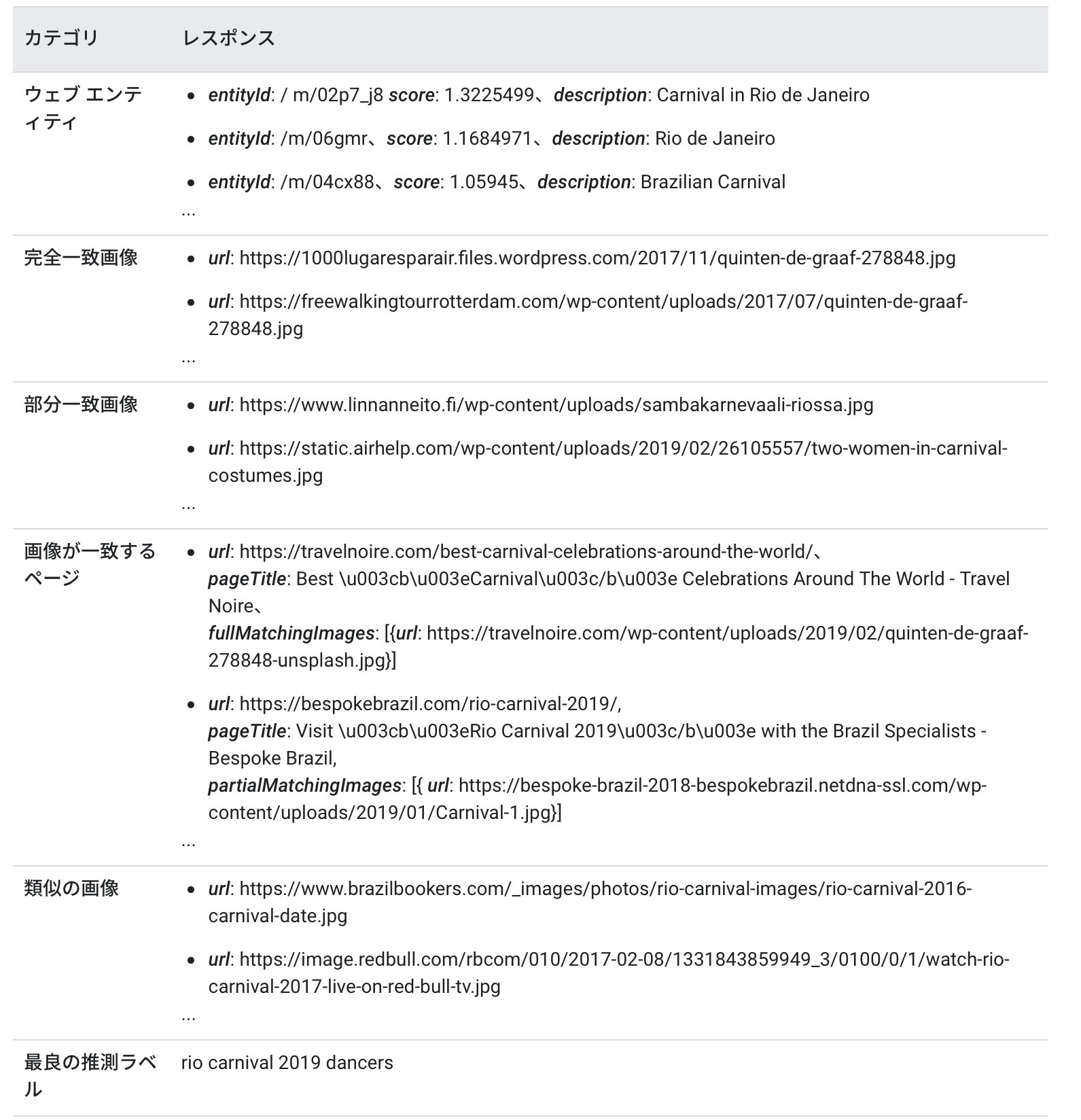
11. WEB_DETECTION
ウェブ エンティティとページの検出
この機能は巨大な検索エンジンを持つGoogleならではの機能であると思うが、画像に関する情報をウェブの情報を参照しながらデータを返してくれる。
例えば、下の画像を見てどのような情報が読み取れるでしょうか?
少し考えてみてください!

上の画像からは下記のようなレスポンスが得られます。
- ウェブエンティティ:画像に含まれる要素(リオデジャネイロのカーニバル、リオデジャネイロ、ブラジルのカーニバルなど)
- 完全一致画像:入力画像と完全に一致する画像をウェブ内から検索
- 部分一致画像:入力画像と部分的に一致する画像をウェブ内から検索
- 画像が一致するページ:URLとページのタイトル、部分的に合致する画像など
- 類似の画像
- 最良の推測ラベル:画像が示すものの推測ラベル(2019年のリオのカーニバルのダンサー)
まとめ
visionAPI一つをとってみても、このように多くの機能があります。
みなさん、一通り見てみて知っている機能はどのくらいありましたか? これはよくある分析だな~と思うものもあれば、このような解析もあるのかといったものもあったかと思います。これが多くの分野で、複数の企業がサービスとして提供していることを考えると、すべてを追っていくのは難しいですよね。そんな方々の一助になれれば良かったと思います!