おまけ
stair captionsでいくつか試して見ました
キャプションの付け方の例として以下のページから検索できるようになっています。
なんとなく3番目の画像のキャプションは日本語としてなんとなく違和感を感じます。いや、間違ってはいないんですが・・・
http://captions.stair.center/explore/

早速、試して見ましょう
http://captions.stair.center/demo
ループ系
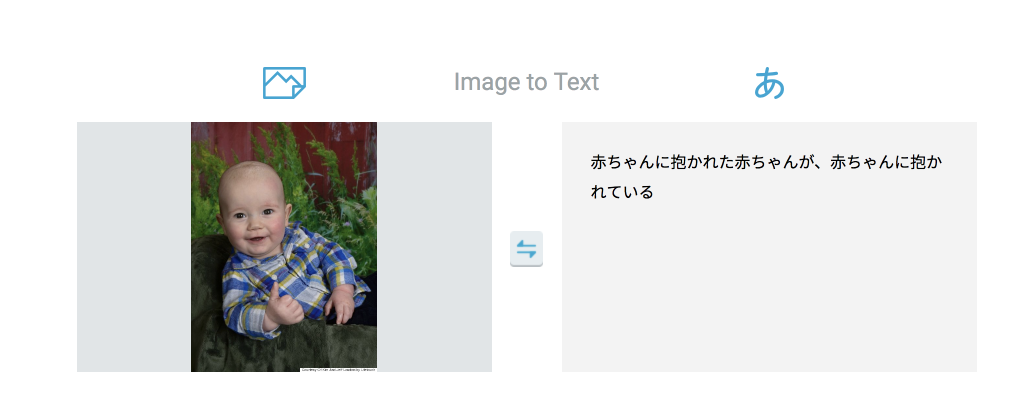
再帰的赤ちゃん
背景に反応したのでしょうか
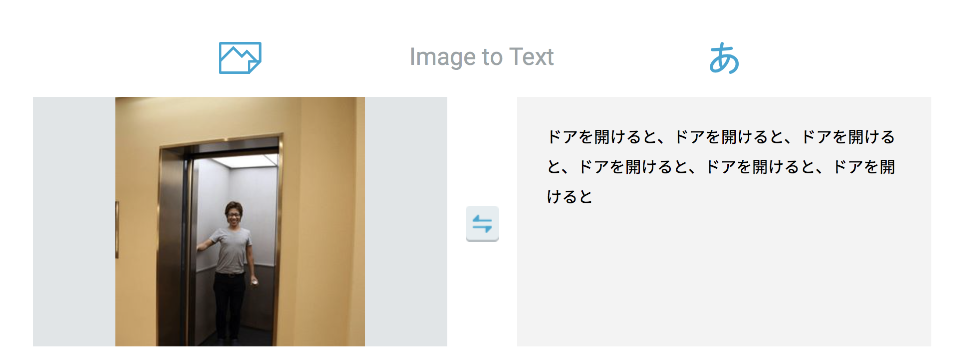
マトリョーシカ状態
大量検出系
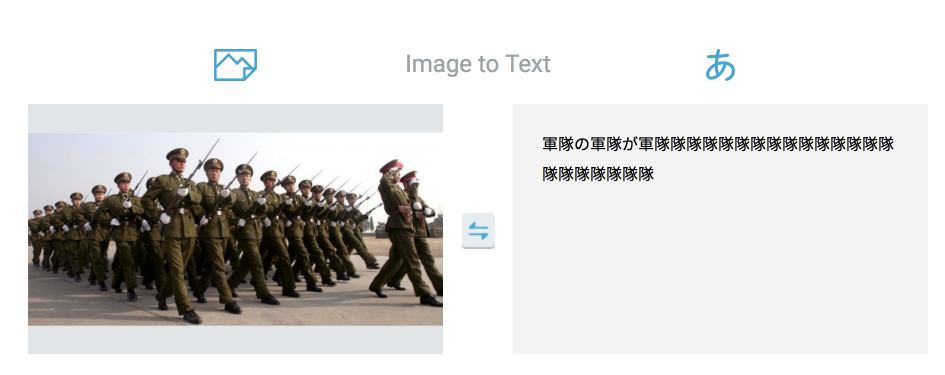
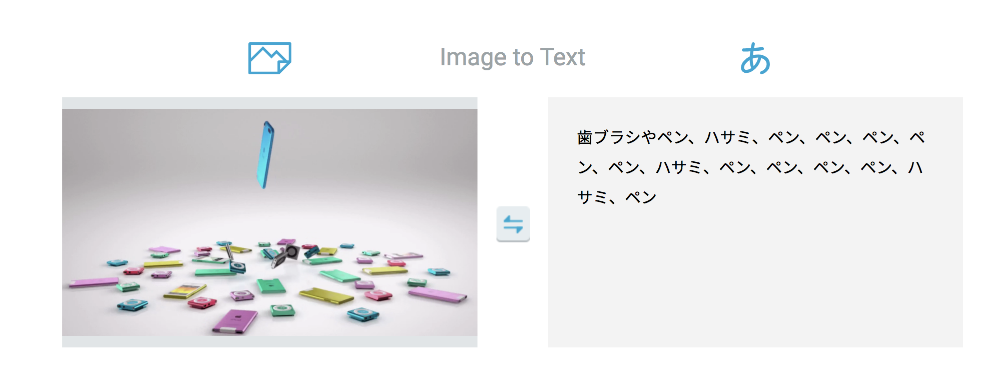
複数の物体を見つけると全てにキャプションをつけようとするのか、文章がすごいことになります。
「AがBで、CがDである」というキャプションのルールなのか、三つ以上の物体を判定した時に文章が崩れやすい印象を受けます。
原因として
- このデータセットでは画像に対し計5個のキャプションをつけている
- このとき、一つの画像に複数キャプションをつける場合に人間は、画像の一部を切り出して説明しようする。
- 結果、画像全体を見たキャプションではなく、画像一部を見たときのキャプションで学習することになる。
人間は画像の一部分にもキャプションをつけることができます。
しかし、このモデルでは画像全体を見てしまうようでLSTM側で全ての物体に対して無理やりキャプションしようとした結果、日本語としておかしくなってしまった印象を受けます
二次元系
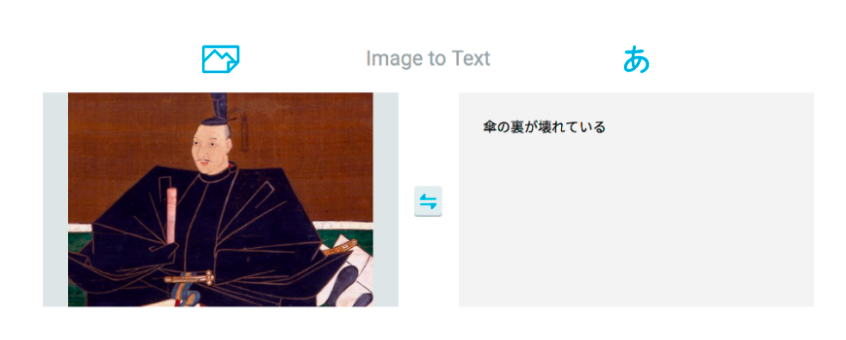
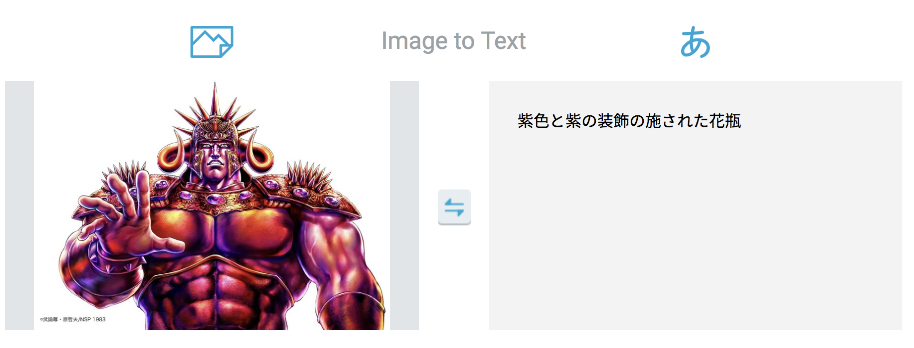
シワが傘の裏に、光沢が花瓶に見えたのでしょうか?
それにしても、「傘の裏」というキャプションがついた元の画像とは一体。。。
哲学系
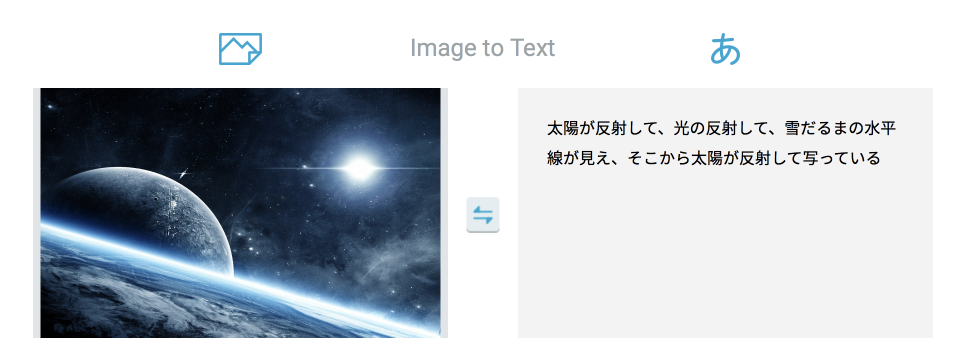
もはや哲学めいたものを感じます。
「雪だるまの水平線」なんてこの画像からちょっと出てきそうにありません。
見えないものを見ようとして

時計らしいことはわかったようです。
他にも時計が写った画像を試してみましたが、正確に当てたものは皆無でした。。。
まぁ、ものによっては傾いたりしますし。。。
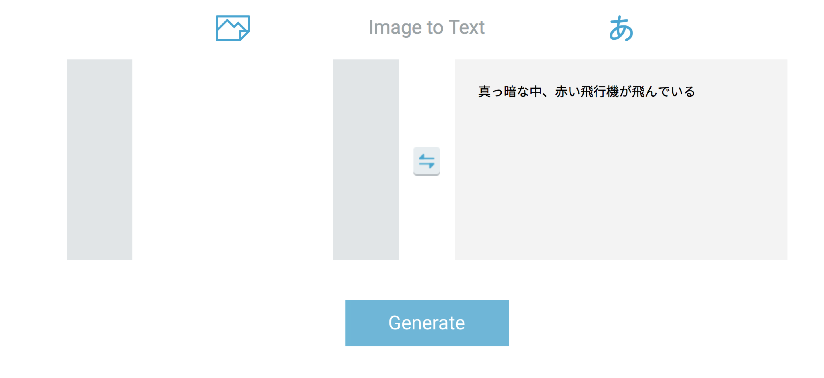
これに至ってはもはや何が見えたのでしょうか
固有名詞系
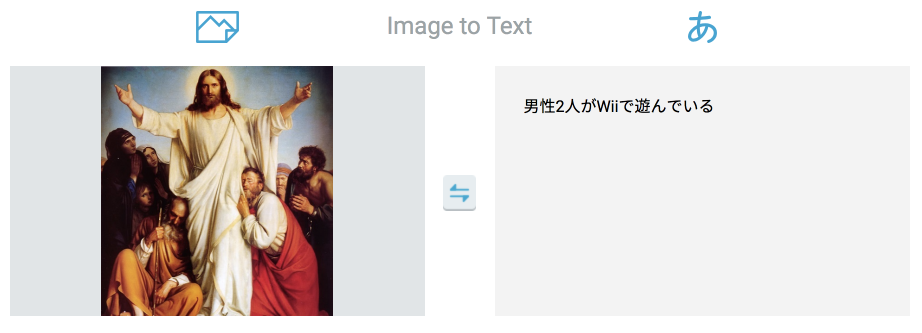
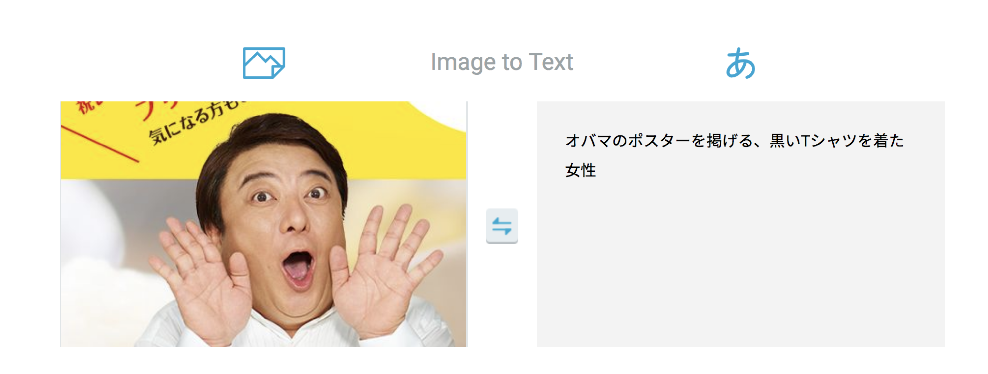
本来なら除かれているはずの固有名詞が含まれてしまっているパターンです。
キリストのことをwiiとみなしたり、どこに反応したか分かり兼ねますがオバマという単語が出てきてしまっています。
二枚目のこう判断した気持ちはわかる気がしますが、一切合切を外してくるキャプションにはもはや感動すら覚えます。
正解系
まれにドンピシャだったりするのですが、確率としてかなり低い印象です。
データセットの中に似た構図を持ってくると正解率が上がる印象を受けます。
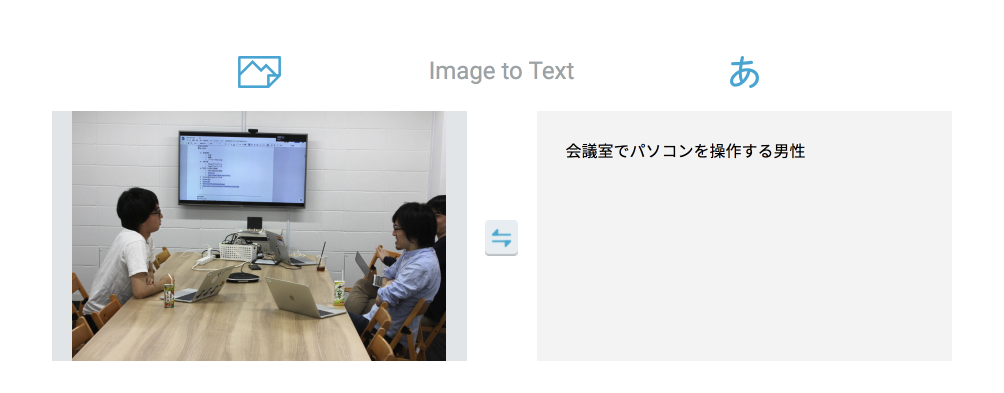
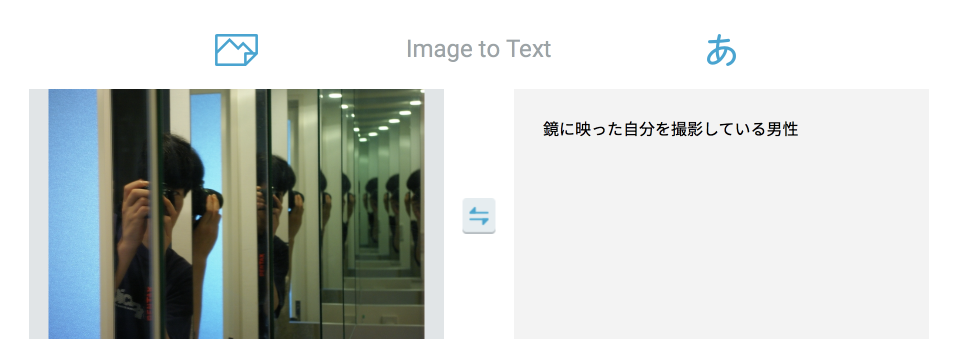
裏を返せばここまでの画像は、データセットからかけ離れたものだったということになります。
まとめ
データセットには少ないだろう宇宙の背景や小物だけが写っているデザイン重視の画像、アニメや漫画などの絵に対する精度は低くなったとしても仕方ないと言えます。
とはいえ傘の裏と認識する以上はデータセットに組み込まれいるはずで、なぜそれをデータセットに入れたのかが少し不思議に思いますが・・・
こういうところも含めて、検品作業は大事だなぁと思いましたまる