自分は、1年前からPythonを使い始めました。Pandasを始めとするPythonのデータサイエンス用のライブラリーは便利です。
つい最近、マイクロソフトがExcelにPythonを搭載することを検討しているというニュースが流れました。VBAとは長い付き合いなので、前半でVBAよりPandasが数倍便利だということを書いて、後半でExcelにPythonを搭載されることへのコメントを書くことにします。自分は、ExcelはデータのためのGUIツールとしては便利で役に立つツールだと思っています。ただ、VBAの方が長年放置されていて最近の言語としては落第なのでPythonが搭載されることを期待したいと思っています。急遽テーマを変更したので、時間がなくて以下は「Excel VBA Advent Calendar 2017 20日目」の記事と同じにしてしまいました。
「ExcelにPythonが搭載?その後 - xlwings を使おう」では、Excel から Python を利用する方法を書いたので、そちらも参考にしていただければと思います。(2018/12/29追記)
Pandasを使ってみる
Pandasの最も重要なデーター構造がDataFrameですが、DataFrameはExcelのデータテーブルとほぼ同じものです。構造が似ているので、Pandasを使うとExcelのデータを1行で読み込みことができ、1行でExcelに書き出すことができます。データの処理をしたい場合だと、ExcelとPandasの間のやり取りは至って簡単にできます。
import pandas as pd
# Excelファイルを読み込む
df = pd.DataFrame.read_excel('sample.xlsx')
# 処理をする
# Excelファイルに書き込む
df.to_excel("sample2.xlsx")
そして、Pandasは、そのDataFrameを処理するための機能が充実しています。「Excel VBA Advent Calendar 2017」の記事で、データを扱っているものが3つあったので、Pandasで書き直して見ました。Pandasが便利ということが分かると思います。
使用したデータ等は、GitHubに置いておきます。自由に使ってください。
https://github.com/timej/pyexcel
例1
1日目の「シート上のデータを配列に格納する際、一意になるように格納する方法」
import pandas as pd
df = pd.read_excel('data/sample1.xlsx')
nd = df['顧客'].unique()
pd.Series(nd).to_clipboard()
pandasには、重複を除くために使えるメソッドに、DataFrame.drop_duplicates、Series.unique、Series.value_count等が既にあって、自分でコードを書く必要はありません。ここでは、Excelの出力するのではなくて、クリップボードに出力しています。クリップボードへの出力はExcelに貼り付けができるので、Excelで作業している時にはファイルに出力するよりも意外に便利です。
例2
14日目の「utf-8のcsvファイルをExcelで読み込むまで」です。
import pandas as pd
# 入力ファイルを指定
path = 'data/sample2_lf.csv'
# 出力ファイルを措定
out = 'data/sample2_crlf.xlsx'
df = pd.read_csv(path, header=None, dtype=object)
df.to_excel(out, header=False, index=False)
# GDPのデータを内閣府のホームページからダウンロードしてみました
# http://www.esri.cao.go.jp/jp/sna/data/data_list/sokuhou/files/2017/qe173_2/gdemenuja.html
url1 = 'http://www.esri.cao.go.jp/jp/sna/data/data_list/sokuhou/files/2017/qe173_2/__icsFiles/afieldfile/2017/12/07/gaku-mg1732.csv'
df1 = pd.read_csv(url1, encoding='cp932', header=None)
print(df1)
テストしたら、Pandasのread_csvは、ダブルクォーテーション内にカンマ、改行があっても正常に処理ができているようでした。また、直接Webから簡単にダウンロードして使えるのは便利です。
例3
16日目の「行と列および交点で構成されるデータ表」です。クロステーブルには集計行を付ける場合が多いので、集計行が付いている場合でやってみました。
"""クロステーブルを入力用テーブルに変換"""
import pandas as pd
# Excelファイルの読み込み。2行をヘッダー及び2列をインデックス列に指定
df = pd.read_excel('data/sample3.xlsx', header=[0, 1], index_col=[0, 1])
# 計の行と列を除く
df = df.iloc[:-2, :-2]
# イテレータを使って1列に並べる
sr = pd.Series()
for index_id, row in df.iterrows():
row.index = row.index.map(lambda x, i=index_id: i + x)
sr = sr.append(row)
sr = sr.dropna()
# インデックスがtuppleになっているので、マルチインデックスに直す
sr.index = pd.MultiIndex.from_tuples(sr.index)
# Excelファイルに書き込み
sr.to_excel('data/sample3_result.xlsx')
# クリップボードにペーストできます
sr.to_clipboard()
# Qiitaの記事と同じ形式(タイトル無し、前の行と同じ項目名でも表示)
df2 = pd.DataFrame(sr)
df2 = df2.reset_index()
df2.to_excel('data/sample3_result2.xlsx', header=False, index=False)
SEやプログラマーはデータ加工が難しいと言ってクロステーブルを嫌がりますが、自分でデータを作成するのであればクロステーブルです。文字の入力が最小限で済みます。Excelでしていた作業をWebでシステム化すると大抵不便になりますがこの辺りがかなり影響していると思います。Pandasを使うとクロステーブルからデータベースに登録したりJsonに書き出すことが簡単にできます。
VBAとPandasの比較
以上の例を元のページのVBAのプログラムと比較すればよく分かるのですが、VBAでは、Range又はCellsをループで廻して処理をするしかないのです。一方Pandasの方は、DataFrameを処理するための機能が充実しているということです。公式マニュアルのDataFrameのページには、DataFrameのメソッドの一覧がありますが、充実ぶりがよく分かると思います。
そして、VBAはExcelが起動していないと使えないのですが、PandasはExcelが無くても動作します。それで、Linuxサーバーでも問題なく使えます。
また、VBAはExcelのソフト内のエディタ(VBE)で開発するので、バージョン管理やモジュールの共有化が難しいという問題があります。同じMicrosoftの製品ですがVisual Studio Codeは良くできています。VBEとは比較になりません。Pythonを編集する場合は、Visual Studio Codeを下の図のような感じで使っていますが、Visual Studio Code上で、デバッグも、Gitで保存することもできるし、ターミナルがあるので自分が作ったPythonのプログラムを起動したりJupyter Notebookを起動することもできます。
下のプログラムはPandas便利だと思った例です。SQL Serverから PostgreSQLへのデータベースの引っ越しに使いました。インデックス等の引っ越しはできないので手作業が残りますが、他の方法と比べると断然単純でした。この例のように、PandasだとExcelだけでなく総てのデータベースで活用できます
"""テーブルをSQL ServerからPostgreSQLに移動させるプログラム"""
import pandas as pd
import pyodbc
import psycopg2 as pg
from sqlalchemy import create_engine
cnxn = pyodbc.connect("DRIVER={ODBC Driver 13 for SQL Server};SERVER=localhost;DATABASE=database;UID=user;PWD=password;")
engine = create_engine('postgresql://user:password@localhost:5432/database')
df = pd.read_sql('SELECT * FROM [dbo].[table] ', cnxn)
df.to_sql('table', engine)
Pandasについて
Pandasは、Pythonでデータ分析するのに必要なツールの一つで、Wes McKinney氏によって財務データの定量分析をするために2008年に開発されたものです。VBAに比べると比較にならないほど貧乏なところで誕生しましたが周囲からの愛情を受けて育てられたことで、今では、データ解析のためのツールとして広く使われており、最近流行の機械学習の分野においてはpandasは非常によく利用されています。
Pythonは、人気のあるプログラミング言語になっており、IEEE Spectrum の 「The Top Programming Languages 2017」では、最も人気があるプログラミング言語になっています。また、「PYPL PopularitY of Programming Language」のランキングでは現在2位ですが、グラフを見れば分かるのですが5年で10.9%増加して1位のJavaとの差が2.8%になっているので、近い将来に1位になると思われます。
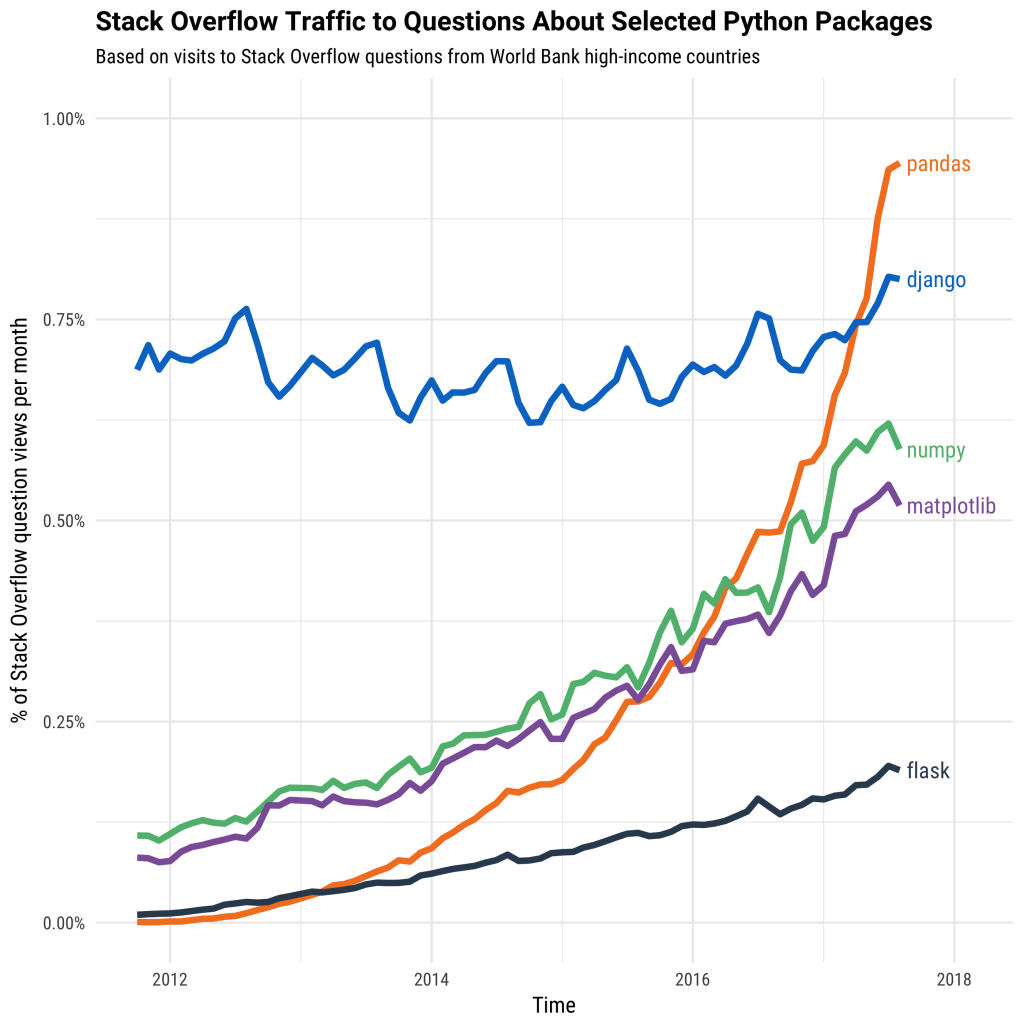
Pythonのツールの中で、急成長しているのがPandasです。Stack Overflowが発表した「この10年で急成長した開発技術」という記事「Dramatic Shifts in Technologies on Stack Overflow」では、Pandasは、5位になっています。また、同じStack Overflowの「Why is Python Growing So Quickly?」のグラフをみるとPandasが急成長しているのがよく分かると思います。
ExcelにPythonが搭載されることについて
ExcelにPythonが入いることについては、驚くべきことではありません。
- Visual Studioには、Python Tools for Visual Studioがあり、Visual Studio CodeにはPython拡張用のアドイン「Python」があり、開発環境を既に持っていること。
- SQL Server 2017に、In-Database Pythonが組み込まれたこと。
VBAはOffice 97以降実質的な機能の追加がされていません。20年間放置されていたので、今どきのプログラム言語と比較すると、古くさい言語になってしまっています。Stack Overflowが公開している「嫌われているプログラム言語やツール」では毎年トップクラスにランクされます(参照)。開発者は、放置されている言語を使いたくないと思うのは当然です。
そして、「AIファースト」を打ち出しているマイクロソフトにとって、AI用のフロントエンドが必要であり、Excelもその役割を担うと考えるのが自然です。それであれば、現状ではデータサイエンス用のライブラリーを含めてPythonを搭載するしかないです。OSSのオフィスソフトLibreOfficeの場合Pythonでマクロを書く事ができますが、それを使おうとは思いません。単にVBAをPythonに置き換えただけでは、それほど便利になるわけではありません。ExcelがAI用のフロントエンドとして便利なものになっていくことに期待したいと思います。
ソフトウェア開発者であれば、ExcelにPythonが搭載されるまで待つ必要はありません。ここに書いたようにPandasからExcelを扱えばいいのです。また、PythonにはExcelやそのファイルを操作できるopenpyxl, xlwingsというライブラリーもあるので大抵のことはできます。
しかし、ExcelにPythonが付属することで大きく変化することがあります。それは、サラリーマンの場合、ソフトを勝手にインストールしてはいけない職場が結構多いと思います。そういう職場だと、VBAはOfficeは入っていると使えるのですが、Pythonを使うとなると許可をもらうのが結構面倒だと思います。それに、Pythonの開発環境を作るのも教えてくれる人がいないと結構難しいことです。しかし、ExcelにPythonが入いれば、簡単に、そして堂々と勤務時間中にPythonを使えるようになります。そういうことを考えれば、Pythonがますます普及するのは間違いないと思います。