はじめに
2024年10月以降、ChatGPTやGeminiなどでliveという機能が次々にリリースされ、これまで以上に軽快なテンポでAIとの会話が楽しめるようになっています。個人的には英会話の練習としての活用が気にいっています。
そんな中、最近Sesame社の音声AIのデモ(2025年2月公開)を体験したのですが、その音声のリアルさに驚愕しました。ChatGPTやGeminiのlive機能での会話も自然なテンポではあるものの、音声自体はどこか無機質な印象でした。しかし、Sesame社の音声AIは、発話の強弱、抑揚、間のとり方、鼻で笑うような感情混じりの微妙なニュアンスの表現など、まるで実際にネイティブスピーカーと対峙しているようで(自分が非ネイティブであることによる)若干の居心地の悪さのようなものを感じるほどでした。
先程のデモのページに技術的な内容も書かれており、よい機会なので勉強してみました。本記事では、私の理解を書き留めます。
なお、私の専門はビジョン系で、音声分野は詳しくなかったのですが、ChatGPTに教えてもらながら理解を深めました。初歩的なところから、ちょっと気になった些末なところまで、気兼ねなく質問できる点で非常に良いChatGPTの使い方だと感じました。本記事の執筆に当たってもChatGPTをフル活用しています。(間違っている部分があればコメント欄にてご指摘いただければ嬉しいです。)
Transformerや自己回帰モデルなどの基本的な内容の説明は本記事では省略します。
従来の音声合成の課題
従来のText-to-Speech(TTS)技術(本記事では音声合成技術と同義)では、テキストから音声を直接生成していました。しかし、以下のような重大な課題が存在していました:
- 同じテキストでも話し方(抑揚、テンポ、口調)には多様なバリエーションがある(いわゆるOne-to-Many問題)
- 現在の発話だけでなく、それまでの文脈や感情を反映することができない
- 音声の生成がバッチ処理前提で行われており、リアルタイム対話には不向き
こうした課題を克服するために、Sesame社のConversational Speech Model(CSM)は会話の流れや話者の履歴を考慮した音声生成を行い、リアルタイムで自然な応答ができるAI音声体験を提供することを目指しています。
CSMの主な特徴と構成
特徴 1. 音声とテキストの両方を入力とするマルチモーダルモデル
CSMは、音声とテキストの両方を同時に処理可能なTransformerアーキテクチャを採用しています。テキストを表すトークンと音声を表すトークンを交互に入力することにより、音声の内容だけでなく、抑揚や間のとり方など言外の文脈や話者の意図を反映した出力が可能になります。
特徴 2. 二段構成のTransformer設計
CSMは以下の二つのTransformerモジュールで構成されています:
- バックボーン(Backbone):意味や文脈の理解、Semantic token(後述)の生成を担います。これまでの会話履歴をもとに、回答の意味的な骨格となるtoken列を生成します。この時点では話し方の特徴(個性)の情報は含みません。
- デコーダ(Decoder):声の質感や音響的な特徴(Acoustic token)を再現し、実際の音声として出力可能な形式に整えます。バックボーンの生成した骨格にリアリティのある色付けをしていくイメージです。バックボーンより軽量・高速なモデルが用いられます。
従来の問題への対応
- 同じテキストでも話し方(抑揚、テンポ、口調)には多様なバリエーションがある(いわゆるOne-to-Many問題)
- 特徴2で、話者不変な音声骨格(Semantic token)と話者依存のAcoustic tokenを分離。音声骨格(Semantic token)のブレは少ないので高品質に学習可能
- 現在の発話だけでなく、それまでの文脈や感情を反映することができない
- 特徴1でこれまでの会話履歴の音声(どもりなど言外の意味を含む)も入力可能
- 音声の生成がバッチ処理前提で行われており、リアルタイム対話には不向き
- 特徴2により品質と速度を両立
前提知識:音声のトークナイズ
CSMに限らず昨今のTTSでよく使われる音声の潜在表現手法としてがあります。
そもそも音声は1次元の時系列の波形データです。これを例えば80ms間隔のフレームに分割し、その区間(フレーム)の音高や大きさを特徴ベクトルとして表現します。しかし、このままのベクトル表現ではTransformer等の入力に適さないことがわかっており、前後の音も踏まえた、より高度な意味を持つ表現である「潜在表現」に変換してからTransformerに入力することが一般的です。これはVisionの分野でも一般的なアプローチです。
音声のトークナイズ手法:Residual Vector Quantization(RVQ)
潜在表現への変換手法としては、ディープラーニングを用いない手法、拡散モデルを用いた手法など多数存在するようですが、昨今、CSMを含め多くのTTSで用いられている手法としてResidual Vector Quantization(RVQ)があります。
RVQは、入力フレームの音声特徴ベクトルにそれぞれに対して、何らかのラベルを与えます。すなわちone-hotベクトルに変換していると捉えることもできます。この変換のことをコードブックと読んでいます。
RVQの特徴的な点は、各入力フレームに対し、大まかな分類(ラベル付け)をするコードブックから、より詳細な分類をするコードブックまで階層的にコードブックを持つことで高品質な表現の獲得を可能にしています。この階層のことをレベルXXのコードブックと言います。レベルは0が一番粗く、レベルが大きくなるほど細かい特徴を表します。
下図はコードブックの階層のイメージです。外側の5x5のセルはレベル0のコードブックを示し、中央セル内部の更に細かい5x5のセルがレベル1のコードブックを示すイメージです。レベル1以降は、ひとつ下のレベルのコードブックのラベルからの残差を表現します。
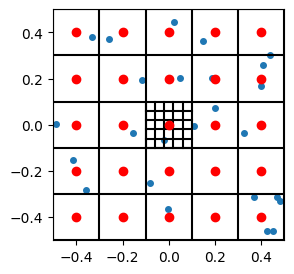
画像出典:Residual Vector Quantization
例えば、コードブック数=4で100フレームの音声が入力された場合、出力は以下のようになります。
出力 = 整数インデックスの配列(サイズ:100フレーム × 4コードブック)
例:
[
[23, 104, 310, 15], ← 1フレーム目のコードブック0〜3のインデックス
[51, 88, 199, 31], ← 2フレーム目
...
[90, 77, 145, 10] ← 100フレーム目
]
RVQ における Semantic token と Acoustic token
CSMでは、RVQによるレベル0のコードブックの出力をSemantic token、レベル1以降のコードブックの出力をAcoustic tokenとして、以下のような役割があるとしています。
- Semantic token(codebook 0):話の内容・意味・抑揚など、話者に依存しない抽象的な特徴を表します。
- Acoustic token(codebook 1以降):声色・話者の癖・音響的特徴などを表し、高い忠実度で音声を再現するために使用されます。
発話中の「うーん」「えっと」などもSemantic tokenとして取り扱えるので、より人間らしい間合いやイントネーションも再現可能なのが強みです。
例(イメージ):
「うーん、それはちょっと…考えさせて」
- Semantic tokenの段階:
- ためらいあり
- ゆっくり
- 複雑な感情の含み
- Acoustic tokenの段階:
- 「うーん」が鼻声っぽい
- 語尾が下がる
- 声の強さが弱い
RVQにより、潜在表現から音声の逆変換(逆RVQ)も可能です。これにより、高品質な音声合成が可能になります。
RVQの課題
しかし、RVQには各コードブックを逐次的に計算する必要があるため(並列処理できないため)、初期応答までに時間がかかり、リアルタイムの音声合成には向かないという課題があります。
特にリアルタイムの会話の場合、単に音声波形をtokenに変換するのではなく、新しい発話内容に相当するtokenを全コードブック分、Transformerによる自己回帰で生成する必要があります。
単純なアプローチでは、ユーザの発話終了後、これまでの発話履歴をトークナイズしたトークン列をTransformerに入力し、1ステップ先のトークンをcodebook0からcodebookN-1まで生成し、次に、その生成した1ステップ分のトークンも入力として、さらに1ステップ先のトークンをcodebook0からcodebookN-1まで生成し…、という自己回帰プロセスを繰り返すことになります。
CSMの工夫
そこで、Sesame社のConversational Speech ModelはTransformerを2段階にすることでRVQの処理時間の課題を解決しました。
-
最上位のSemantic token(codebook 0)のみをまずバックボーンで生成することで、音声の「意味」「長さ」「構文」「話し方のスタイル(間・ためらい・強調など)」を決定。
-
残りのAcoustic tokenは軽量なデコーダで並列または高速に生成。Semantic tokenを補完し、「声の質感」「話者らしさ」を表現する役割。
これにより、全体の生成時間が大幅に短縮され、リアルタイム会話が可能になります。

画像出典:Sesame社プロジェクトページの画像に赤字追記
CSMによるリアルタイム音声生成処理の流れ
これまでの内容の理解を深めるためにも、ユーザとの会話の中でリアルタイムに音声を合成する流れを整理して説明します。
ステップ①:ユーザーの発話終了を検出
CSM自体は「ユーザーが話し終わった」ことを検出する仕組みを内部には持っていません。そのため、CSMが音声生成を開始するトリガー(ユーザー発話の切れ目)は、外部の音声認識・VAD(Voice Activity Detection)モジュールなどが検出した「発話の終わり」です。例えば、一定時間の無音状態をもって「発話の終わり」と判定します。
🔹 出力: 発話区間(start time ~ end time)の音声波形
ステップ②:音声をRVQトークンに変換
- 発話単位のwaveformを、MimiなどのRVQによってSemantic tokenとAcoustic tokenに分解
- 必要であれば、ASR(自動音声認識)によってテキスト化も行います
🔹 出力:
- Semantic token(Ausentic tokenは使わない)
- (テキストが得られていれば)音声認識結果のトークン列も付加可能
ステップ③:CSMのバックボーンに入力
- 過去の会話履歴(テキスト+トークン列)と、最新のユーザー発話に対応するSemantic token(+テキスト)を連結し、入力として与える
🔹 入力形式:
[<text_start>, "今日は寒いですね", <text_end>,
<audio_start>, semantic_token [100個], <audio_end>]
ステップ④:応答の生成
-
④-1 バックボーン:次に発話すべきSemantic token(codebook 0)を逐次生成(=この時点で「応答の意味と長さ」が決定)。テキストや音声文脈をもとに、意味やリズムを自然に調整
-
④-2 デコーダ:上記のSemantic tokenを条件に、声の質を含むAcoustic token(残りの codebook(1〜N−1))を生成
🔹 出力: 全codebook(semantic + acoustic)で構成された完全な音声トークン列
ステップ⑤:音声として再構成
- トークン列を デトークナイザー(逆RVQ) で波形に変換
- 生成された音声がユーザーに再生される
👉 対話の応答として聞こえる
処理の流れの概略図
全体の流れを図にしてみました。

青がRVQの出力のトークン(最下段がcodebook0で最上段がcodebookN-1)、緑色がテキストトークンを表しています。
(手書きのラフスケッチをChatGPTにきれいにしてもらおうと試みましたが全然だめでした)
学習方法
以上は推論時の流れです。以下では学習方法について説明します。
基本的にはバックボーン・デコーダともにクロスエントロピーによる教師あり学習によって行われます。
バックボーン
- 入力:
- 過去の会話履歴(text & audio tokens)
- 現在の話者発話の直前までのcodebook0(semantic token列)
- 出力:
- 次に発話すべきcodebook0のトークン列(autoregressive予測)
デコーダ:
- 入力:
- 予測済みcodebook0(semantic token)
- 話者プロンプト音声(speaker embedding)
- 特定の話者の話し方・声質・イントネーションなどの特徴
- 話者プロンプト音声は別のモデルで算出するようです。
- 出力:
- 各フレームに対するcodebook1〜Nのトークン列
ここで、正解となる各レベルのcodebookが必要ですが、これは学習済みRVQを用いて予め計算しておきます。RVQがトークナイザとして機能するイメージです。CSMではMimiを用います。
計算量削減の工夫:Compute Amortization
RVQトークンの階層的な予測を 全フレーム × 全階層 で学習しようとすると:
- B × S × N という莫大な計算量とメモリ消費が発生
- B = バッチサイズ
- S = 音声フレーム数(時系列長)
- N = コードブック階層数(例:32)
これにより、次の問題が発生します:
- 学習が遅い
- モデルスケーリングが困難
- 実験サイクルの高速化ができない
これらの問題を解決するために、"すべてのフレームで全codebookを予測するのではなく"、以下のような学習方法が採用されます。
| 処理対象 | 処理内容 | 備考 |
|---|---|---|
| Codebook 0(最上位) | すべてのフレームで予測・学習 | 意味・文構造の予測に関与する重要な階層なので省略しない |
| Codebook 1~N-1(残り) | ランダムに選ばれた1/16のフレームだけで予測・学習 | 学習効率アップ。実際の損失(loss)にもこのサブセットだけが反映される |

実験と評価
評価実験について記載されていた内容を以下簡単に記します。
データセット
- 公開音声データをベースに約100万時間分の英語音声を収集・前処理。
- 音声は書き起こし、話者分離(diarization)、セグメンテーション済。
モデルサイズ
| モデル | Backbone | Decoder |
|---|---|---|
| Tiny | 1B | 100M |
| Small | 3B | 250M |
| Medium | 8B | 300M |
- 全モデル、2048トークン(約2分相当)で5エポック学習。
評価
客観評価(Objective Metrics)
既存の評価指標
- Word Error Rate(WER)
- Speaker Similarity
→ 既存モデルと同様、CSMもほぼ人間レベルの性能を達成。

新しい評価指標
既存の評価指標は精度がサチっていて差がわかりにくいため、以下の新しい指標を定義。
-
Homograph Disambiguation
- 同じ綴りで異なる意味・発音の単語を正確に発音できるか
- 例:「lead」(鉛 /lɛd/) vs(導く /liːd/)
-
Pronunciation Continuation Consistency
- 文脈によって発音が異なる単語を正しく発音できるか
- 例:「route」:/raʊt/ (イギリス英語) vs /ruːt/ (アメリカ英語)
→ Largerモデルほど高い正解率を示し、スケーリングの有効性を確認。

主観評価(Subjective Metrics)
AI音声と実際の人間の音声を被験者に聞いてもらい、どちらが自然な音声かを回答 (Comparative Mean Opinion Score)
-
評価内容
- 文脈なしで「どちらが自然な音声か」
- 90秒の文脈を与えて「どちらが自然な会話に感じるか」
-
結果
- 文脈なし:人間 vs CSMで 50:50
- 文脈あり:人間が優勢
→ 現状ではプロソディ(発話におけるアクセント、イントネーション、リズム、ポーズなど言外の表現)の完全な模倣は難しい

結果総括
- 従来の評価指標では差が見えにくい段階に入った
- より高度な理解(文脈、発音の一貫性)を測る新指標の導入が重要
- モデルのスケールアップ(Tiny→Medium)によって、理解と表現力の両面で性能向上
制約と今後の展望
記事に書かれていた現状の制約と今後の展望です。
現在の制約
-
英語偏重の学習データ
モデルは主に英語データで訓練されており、他言語に対しては十分な性能を発揮できない。データセットに偶発的に混入した非英語データ("dataset contamination")によって部分的な多言語性が自然に出現しているが、それは限定的。
課題: 真に多言語対応するためには、明示的かつ体系的な多言語データの導入が必要。
-
言語モデルの知識を活かしていない
現在のCSMは、音声生成において既存の大規模言語モデル(LLMs)の事前学習済み知識を活用していない。(パラメタ数 8B に留まっている)
例えばGPTのようなモデルが持つ、文法・意味・文脈知識を活かすことで、より意味論的に整った音声生成が可能になると期待される。
課題: 音声とテキストの「橋渡し」的なモデル連携の研究が未着手。
-
会話の“構造”そのものは理解できない
CSMは「話す内容」と「どう話すか(音声)」はモデル化できるが、会話における構造的な要素(例:ターンの切り替え、間、タイミング、相槌など)までは学習していない。
人間の会話は非常に動的で相互作用的なプロセスであり、話す順序や間合いを含めて初めて“自然な会話”が成立する。
課題: 音声単体ではなく、「対話」そのものをモデル化する必要性。
今後の展望
✅ モデルのスケーリング
モデルサイズとデータ量をさらに拡張予定(より大規模なCSM)。
音声の表現力・言語理解力ともに、モデルのスケールアップで向上が期待される。
✅ 多言語対応の拡張
対応言語を20以上へ拡大予定。
明示的な多言語データの導入により、真の多言語対応TTSを目指す。
✅ LLMとの統合
今後は事前学習済みLLMの統合(例えば、GPTやPaLMのようなモデル)を検討。
音声生成に言語的・意味的知識を加えることで、より自然かつ文脈に沿った話し方が可能に。
✅ 真の“会話AI”への進化(Full-Duplex Conversation)
将来的には、会話の構造そのものを理解し、相手の発話と同時に応答を生成できるような“全二重(full-duplex)モデル” を目指す。
これは以下のような能力を含む:
- リアルタイムのターン制御
- 相槌・感嘆などの挿入
- 非言語的間(pause)や重ね発話の処理
これはモデルだけでなく、データ収集、学習手法、後処理までを含めたシステム全体の革新が必要とされる。
まとめ:CSMがもたらす革新性と今後の展望
CSMは、従来のTTSシステムの限界を超え、リアルタイムに人間のような自然な対話を可能にする革新的な音声生成モデルです。
日本語でもSesameと同等の会話が可能になるのが待ち遠しいです。
人間と区別がつかないくらいのクオリティで機械とコミュニケーションが可能になることによって、様々な革命が予想されます。機械であれば同時に何百、何千人と会話することも可能ですし、24時間365日即座に反応することができます。これまで通り人間のオペレータと会話していたと思ったらいつの間にかAIにすり替わっていた、ということがそこら中で起こると思われます。私達の暮らしがどのように変わっていくか、非常に楽しみです。