はじめに
こんにちは!
今回は今まで書いたことのない**「自然言語処理」**に関する記事です。
初学者は画像分類などに興味が向きがちですが僕も自然言語処理を勉強してみて面白いと感じた一人なので、初学者なりに面白さを共有できたらいいなと思います。
自然言語処理とは?
最近プログラミングを始めた方でも、一度は自然言語処理というジャンルを耳にしたことはあるのではないでしょうか?
そもそも**「自然言語」とは私たちが普段話している日本語や英語などの言語のことです。
具体的な処理ですが、まず形態素解析といって文章を可能な限り小さい単位(名詞、動詞、助詞など)に分割することから始まり、次にかがり受けなどの構造を明らかにする構文解析を行います。
そして最後に文の中で「誰がいつどこで何をした」という5W1Hを意味解析**で判定します。
「私はご飯を食べる」という例文で考えてみましょう
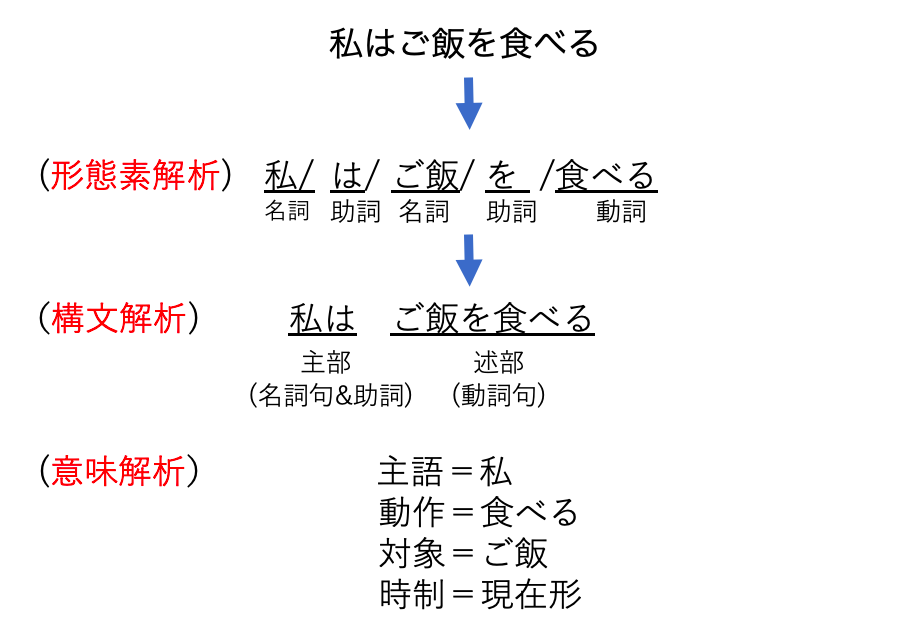
このような手順で文章を解析していくのが自然言語処理です。
次はさらに具体的な種類を見ていきましょう。
word2vec
word2vecとは、簡潔に言えば単語をベクトル化する技術のことです。
リンゴとバナナを例にとって考えてみます。
リンゴのベクトルが(0.3,0.4,0.7,0.9)
バナナのベクトルが(0.2,0.3,0.6,0.8)
だったとしましょう。
この場合、二つのベクトルの要素はそれぞれ似ていますよね?このように単語をベクトル化することで単語の関連性や類似度を目に見える形で判定できるようになるのです。
なおかつ、ベクトルで表現した単語は演算ができます。
例えば、
俳優(0.9,0.7,0.8,0.6)
男優 (0.5,0.3,0.4,0.2)
女優 (0.4,0.4,0.4,0.4)
のようなベクトルが存在するとき、俳優−男優=女優という計算ができます。
word2vecに用いられるのはCBOW(continuous bag-of-words)やskip-gramといったニューラルネットワークです。
seq2seq
seq2seqとは、系列(sequence)を受け取り、別の系列へ変換するモデルを指し、文章などの入力を圧縮するencoderと、出力を展開するdecoderからなります。
実際の活用例をあげると
機械翻訳(例:日本語→英語)
対話文生成(例:自分の発言→相手の発言)
文章要約(例:元の文章→要約文)
など様々なものがあり、どれも身近なものばかりです。パっと思いつくもので言えばSiriなどの会話botがありますね!
自然言語処理に使うライブラリ
ここまで説明されても、実際に自分のパソコンで自然言語処理をするために必要なものはわかりませんよね。
なので、これだけはインストールしておいて間違いないというライブラリをご紹介します。
・numpy
・matplotlib
・tensorflow
・keras
・nomkl
・gensim(word2vecで使う)
・janome(形態素解析で使う)
とりあえずこれさえあれば、さわりの部分は何とかなります。アナコンダなどでサクッとインストールして実際にやってみちゃいましょう!
実践(形態素解析)
では早速、最も簡単な形態素解析をやってみましょう。
先ほど挙げたライブラリをまだインストールしてない方はまずインストールを、インストール済みの方はjupyter notebook上で
from janome.tokenizer import Tokenizer
t = Tokenizer()
s = "私はご飯を食べる。そして学校へ行く。"
for token in t.tokenize(s):
print(token)
と入力してみてください。
するとこのような画面が出て、文章が単語ごとに解析されているのが確認できるかと思います。
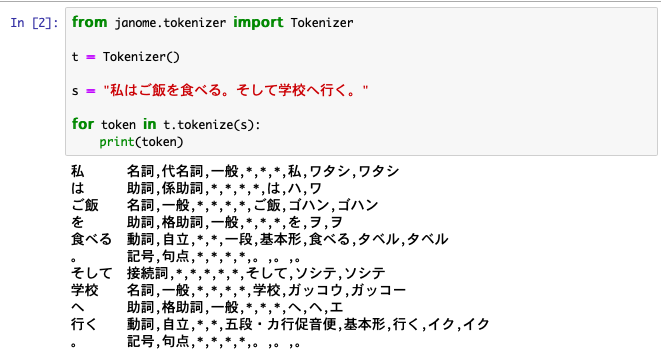
これができたら自然言語処理の仲間入りです。本当の本当に初歩的な部分ですが、自然言語処理の面白さが伝わるでしょう。
この他にも色々と調べて、word2vecやseq2seqなどを使って自分なりの対話botを作っても楽しいと思います!
終わりに
いかがだったでしょうか?
自然言語処理ってなかなか教材が少なくて、勉強しにくいというのが難点です。
この記事はそんな理由でお悩みの方には役立つかと思います。
特に、必要なライブラリの部分とか!
これからはさらに実践的な自然言語処理も記事にできたらいいなと考えていますので、ぜひ読んでみてください!
最後に、医学生である僕が所属しているツカザキ病院眼科AIチームのページも見ていただけたら幸いです!ぜひご覧ください!
ツカザキ病院眼科AIチーム DeepOculus
では、また次の記事で!