はじめに
こんにちは!
これまで新人プログラマの視点で同じく新人プログラマ向けに記事を書いていましたが、この記事で一旦画像分類に関する内容は終了にしようと思います。なぜかというと、、、
ワンパターンになってしまう!!
と思ったからです(笑)
僕が最初に勉強し始めたのが画像分類だったので、ついついその内容をたくさん記事にしてしまいました、、、まあ少しでも皆さんのお役に立てたならそれでいいのですが、、、。
これからは画像分類以外の内容を学習して、最初につまづいた部分などをどんどん記事にしていき、同じように苦しんでいる人のためになる記事作成を心がけようと思います!
今回のテーマ
今回のテーマはおなじみのVGG16です。
「あれ、君この前もVGG16の記事書いてなかった?」
そう言われたら何も言い返せないのですが、今回は色々と改良を加えてみました。もちろん精度も上がっています。結構変わってしまったので前の記事を編集するより新しく書いた方が良いと思い今に至ります。それでは進めていきましょう!
筆者の開発環境
・macOS Mojave バージョン10.14.3
・MacBook Air(11-inch, Early 2015)
・プロセッサ 1.6 GHz Intel Core i5
・Python 3.7.1
これで問題なく動きました!
手順
その1
まずGoogle Colaboratoryを開きます。
開いたらまず、ランタイムをGPUに変更して保存しちゃいましょう。
これがあるのとないのではコードの実行にかかる時間が大幅に違います!
次に、Google Driveをマウントします。以下のようなコードを入力して実行。
from google.colab import drive
drive.mount('/content/gdrive')
そして表示されたURLをクリックし、今回使う画像が保存されているマイドライブを選択して表示されるサクセスコードをコピペします。
その2
その1が終わったら、いよいよコードを入力していきましょう。
まず必要なモジュールをインポートします。
import numpy as np
from keras.preprocessing.image import load_img, img_to_array, ImageDataGenerator
from keras.applications.vgg16 import VGG16
from keras.models import Sequential, Model
from keras.layers import Input, Dense, Dropout, Activation, Flatten
from keras.optimizers import SGD
from keras.utils import np_utils
import os
import matplotlib.pyplot as plt
from keras.callbacks import EarlyStopping,ModelCheckpoint
import time
今回使うのはこんな感じのモジュールたちです。
画像分類にはおなじみのものばかりですが、以前の記事から変更した点はEarlyStoppingとModelCheckpointです。
この2つについては後ほど説明していきますのでお楽しみに。
次は画像を使うためにマイドライブへアクセスしていきます。
os.chdir("/content/gdrive/My Drive")
このコードを実行するだけでOKです。
ちなみに画像フォルダの構造はこんな感じです。
Animal
├─train
│ ├─lion 240 files
│ └─leopard 240 files
└─test
├─lion 60 files
└─leopard 60 files
今回も例によってAnimalフォルダにしてみました。
その3
次はVGG16の本質部分をコーディングしていきましょう。
# 分類クラス
classes = ['lion', 'leopard']
nb_classes = len(classes)
batch_size = 32
nb_epoch = 40
# 画像のサイズ
img_rows, img_cols = 224, 224
# モデルの構築
def build_model() :
# 画像の読み込み.今回はカラー画像の為,shapeの3番目の引数が3(ch)
input_tensor = Input(shape=(img_rows, img_cols, 3))
# VGG16はモデルの名前.引数weightsでpre-trainingしている
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# Sequentialは単純に,前の層の全ノードから矢印を引っ張ってくるモデルを意味している
# 矢印のつなぎ方を複雑にするには,Functional APIを使う
# https://qiita.com/Ishotihadus/items/e28dd461a8ba27a2676e
_model = Sequential()
_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
_model.add(Dense(256, activation='relu'))
_model.add(Dropout(0.5))
_model.add(Dense(nb_classes, activation='softmax'))
model = Model(inputs=vgg16.input, outputs=_model(vgg16.output))
# modelの14層目までのモデル重み
for layer in model.layers[:15]:
layer.trainable = False
# 損失関数と評価関数を指定
model.compile(loss='categorical_crossentropy',
optimizer=SGD(lr=1e-4, momentum=0.9), metrics=['accuracy'])
return model
if __name__ == "__main__":
# ImageDataGeneratorはリアルタイムにデータ拡張しながら,テンソル画像データのバッチを生成する
# 要はデータの水増し(Data Augumentation)に関するオプションを指定している
# https://keras.io/ja/preprocessing/image/#imagedatagenerator_1
train_datagen = ImageDataGenerator(
rescale=1.0 / 255
)
# train_generator: 指定したディレクトリから画像を読み込むときに使用する関数
train_generator = train_datagen.flow_from_directory(
directory= 'Animal/train',
target_size=(img_rows, img_cols),
color_mode='rgb',
classes=classes,
class_mode='categorical',
batch_size=batch_size,
shuffle=True)
# 評価用画像の用意
test_datagen = ImageDataGenerator(rescale=1.0 / 255)
test_generator = test_datagen.flow_from_directory(
directory= 'Animal/test',
target_size=(img_rows, img_cols),
color_mode='rgb',
classes=classes,
class_mode='categorical',
batch_size=batch_size,
shuffle=True)
# インスタンスの呼び出し
model = build_model()
この部分は丸写しで構いません。
要はVGG16を呼び出してImageDataGeneratorを使ってデータの水増しを行っているんですねえ。。。
精度を上げるためにはやっぱりできるだけ多くのデータが必要ですから!
皆さんはこのコード内の"Animal"の部分を、各自が使う画像フォルダの名前にしてください!
その4
さて、ここからは前回から改良を加えた点です。コードはこちら。
# 過学習の抑制
mc = ModelCheckpoint('weights.{epoch:02d}-{loss:.2f}-{acc:.2f}-{val_loss:.2f}-{val_acc:.2f}.h5',monitor="val_loss", verbose=1, save_best_only=True)
es = EarlyStopping(monitor='val_loss', patience=10, verbose=1)
# Fine-tuning
history = model.fit_generator(
train_generator,
samples_per_epoch=trainフォルダの合計枚数を入力,
nb_epoch=nb_epoch,
validation_data=test_generator,
nb_val_samples=testフォルダの合計枚数を入力,
callbacks=[mc,es]
)
#acc, val_accのプロット
plt.plot(history.history["acc"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_acc"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
#Final.pngという名前で、結果を保存
plt.savefig('Final.png')
plt.show()
この部分では過学習を防ぐためにEarleyStoppingを使用して、損失関数が収束したらエポックを止めるようにしています。
無駄にエポックが続いて過学習に陥るというのが、画像分類で最も怖いことです。
過学習というのは、人間でいうと「テストのために問題を丸暗記したけど、実際のテストで出題される新しい問題が解けない」みたいな状況です。要は訓練用画像を完璧に覚えてしまって、評価用画像が分類できないというなんとも悲しい状況、、、。
ですが、この一手間を加えるだけで過学習予防になります。
そして、ModelCheckpointは損失関数が前のエポックと比べて小さくなるたびにモデルを保存してくれる機能です。その時点でのaccとloss,そしてval-accとval-lossがファイル名となってマイドライブに保存されるので、コードを実行した後に確認してみてください!
最後のacc,val-accのプロットでは学習結果をグラフにして表示する処理を加えています。可視化するだけでプログラミングやった感が出るのでおすすめです(笑)
結果

うんうん、いい感じに学習できていますね。
グラフも見てみましょう。
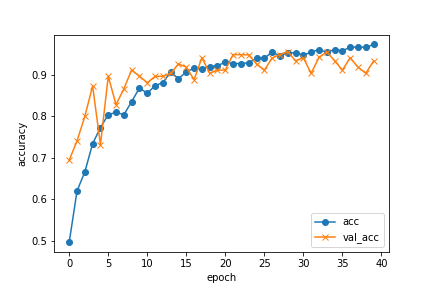
いいですねえ。。。学習できてます。val-accも申し分無しです。
終わりに
いかがでしたか?
前回がショボすぎたというのは否めないですが、今回の改良でだいぶ精度も上がって、コードもそこまで複雑でないものが出来上がりました。
ひとまずこれで画像分類は完了といったところでしょうか。
このコードを丸写ししていただければ速攻でできる内容となっております。
VGG16以外にもファインチューニングできるモデルは公開されているので、皆さんもぜひ各自で調べてお試しください。そして、精度が良いものがあったら僕にも教えてください(笑)
最後に、僕が所属しているツカザキ病院眼科AIチームのOrganizationページもご覧ください!
ツカザキ病院眼科AIチーム
チームメンバーはプログラミングに長けている人ばかりなので、興味深い記事がたくさんあると思います!
では、また次の記事で!