TL;DR
- ZOZOSUITで計測したデータを扱うサーバーは、元々Pythonで実装していた
- それをScalaで実装し直した
- 結果、レイテンシにおけるパフォーマンスが向上した
- さらに、リソース面におけるサーバーコストも削減できた
技術選定における背景
ここ数年、機械学習の文脈やサービスの立ち上げ期のプロトタイプ実装のため、Webアプリケーションの分野においてもPythonが選択されることは本当によく聞かれるようになりました。
事実、難しいビジネス要求や急な仕様変更への柔軟な対応においては、比較的実装コストの低い言語やフレームワークを選択するメリットはとても大きいと言えます。
利用できるすべての変数やメソッドの型をプログラムの実行中に決めなければならない場合、ランタイムのオーバーヘッドは甚大になります。静的型付け言語では、そのオーバーヘッドが不要になります。Python、Perl、Rubyといった昔からの動的言語の多くは、静的型付け言語よりも実行がかなり遅いものでした。
一方で、これは昨年末にOracle社が発表した記事、「動的型付けの衰退」からの抜粋ですが、ここで説かれているように、パフォーマンスの観点においてPythonをはじめとする動的型付け言語で構築されたアプリケーションの実行速度は、比較的に遅いということも長い間言われ続けてきました。有名なところでは、TwitterがRubyからScalaへシフトしたことはこの辺りの事情がモチベーションとしてあった代表例と言えます。
動機
ZOZOTOWNが提供するZOZOSUITのデータを扱うサーバーも、当初、NumPyのような数値計算モジュールや機械学習のモジュールを使う想定があり、Pythonを使って開発をスタートさせました。チームのメンバーとしてはScalaの経験者が多かったこともありましたが、先述の通り、サービスの立ち上げ期において、Pythonでサーバー構築することはローンチへのスピードの担保という点で、とても大きな貢献を果たしたと思っています。
しかし、その当初の要件からZOZOSUIT自体の仕様も変わり1、元々のPythonで実装することの必要性は開発途中で無くなっていました。また、サービスの提供から約1年が経過したところで、AWSで稼働しているサーバー群の最適なインスタンスタイプの見積もりをしていたところ、他案件で扱ってきたScala製のアプリケーションが稼働するサーバーと比較して、捌いているリクエストの量と質に対する選択すべきインスタンスタイプがとても大きく感じることがありました。
このような経緯から、もし今後の運用フェーズにおいて、長期に渡りこのPythonで構築したサーバーを維持していくことを考えた時に、これをScalaで実装し直したら、どれくらいの性能差が生まれるかということを検証したいと考えはじめました。また、先のOracleの記事にあるような動的型付け言語が遅いということも、実際にはどれくらい遅いのか、それが2割程度遅いのか、それとも2倍以上の差がつくほど遅いのか。その問いに答えるための記事や資料を見つけることはできませんでした。そのため、個人的に長い間、数値データとしてこの問いに答えられるような検証をしたいと思っていました。
リクエスト仕様
ZOZOSUITの計測データは、3Dのメッシュデータをクライアントアプリ(iOS/Android)側で生成しています。そのクライアントで生成した3Dデータはサーバーに保存され、必要に応じて以下のような体型データの表示に使用しています。

主なデータとして、faces/verticesという面と点の情報に加え、実際の測定箇所を示すringsという固有の情報を扱います。
{
faces: (約24,000のInt値から構成される二次元配列),
vertices: (約12,000のFloat値から構成される二次元配列),
rings: (約2,700のFloat値から構成される三次元配列)
}
このデータは、jsonデータとしては約500KBにもなるため、Messagepackによる圧縮をしていますが、サーバーサイドで扱うデータとしてはとても大きなものに分類されるのではないかと思います。
負荷テスト
検証環境
Scala
- Scala 2.12.8
- Playframework 2.7.0
Python
- Python 3.7.3
- Flask 1.1.1
- uwsgi 2.0.18
AWS(共通)
- t3.large
- Dynamodb Write Capacity 3,600
※ この記事で公開する検証に使用したサンプルアプリケーションでは、認証処理やデータスキーマの一部を実際のプロダクション環境で実装されているものから割愛しています。細かいチューニングや選択するフレームワーク、ライブラリ、および実装方法によって、この記事で扱う結果は変化するものになりますが、ここではそこにフォーカスすることはしません。
方法
テストでは、2つのアプリケーションサーバーに対し、上記のリクエスト仕様で定義したデータをPOSTするリクエストを5分間、一様に発行し続けます。次いで、リクエスト量を徐々に増やしていき、どちらかのレスポンスが悪化した状態になれば、そこでテストを終了します。各環境には、事前に十分なWarmUpが、別途行われているものとします。
なお、負荷テストツールには、gatlingを採用します。
通常、gatlingで負荷テストを実施する際には、以下のようなレポートがテスト結果として出力されます。
================================================================================
---- Global Information --------------------------------------------------------
> request count 60 (OK=60 KO=0 )
> min response time 2668 (OK=2668 KO=- )
> max response time 3095 (OK=3095 KO=- )
> mean response time 2847 (OK=2847 KO=- )
> std deviation 99 (OK=99 KO=- )
> response time 50th percentile 2837 (OK=2837 KO=- )
> response time 75th percentile 2918 (OK=2918 KO=- )
> response time 95th percentile 3018 (OK=3018 KO=- )
> response time 99th percentile 3066 (OK=3066 KO=- )
> mean requests/sec 0.201 (OK=0.201 KO=- )
---- Response Time Distribution ------------------------------------------------
> t < 800 ms 0 ( 0%)
> 800 ms < t < 1200 ms 0 ( 0%)
> t > 1200 ms 60 (100%)
> failed 0 ( 0%)
================================================================================
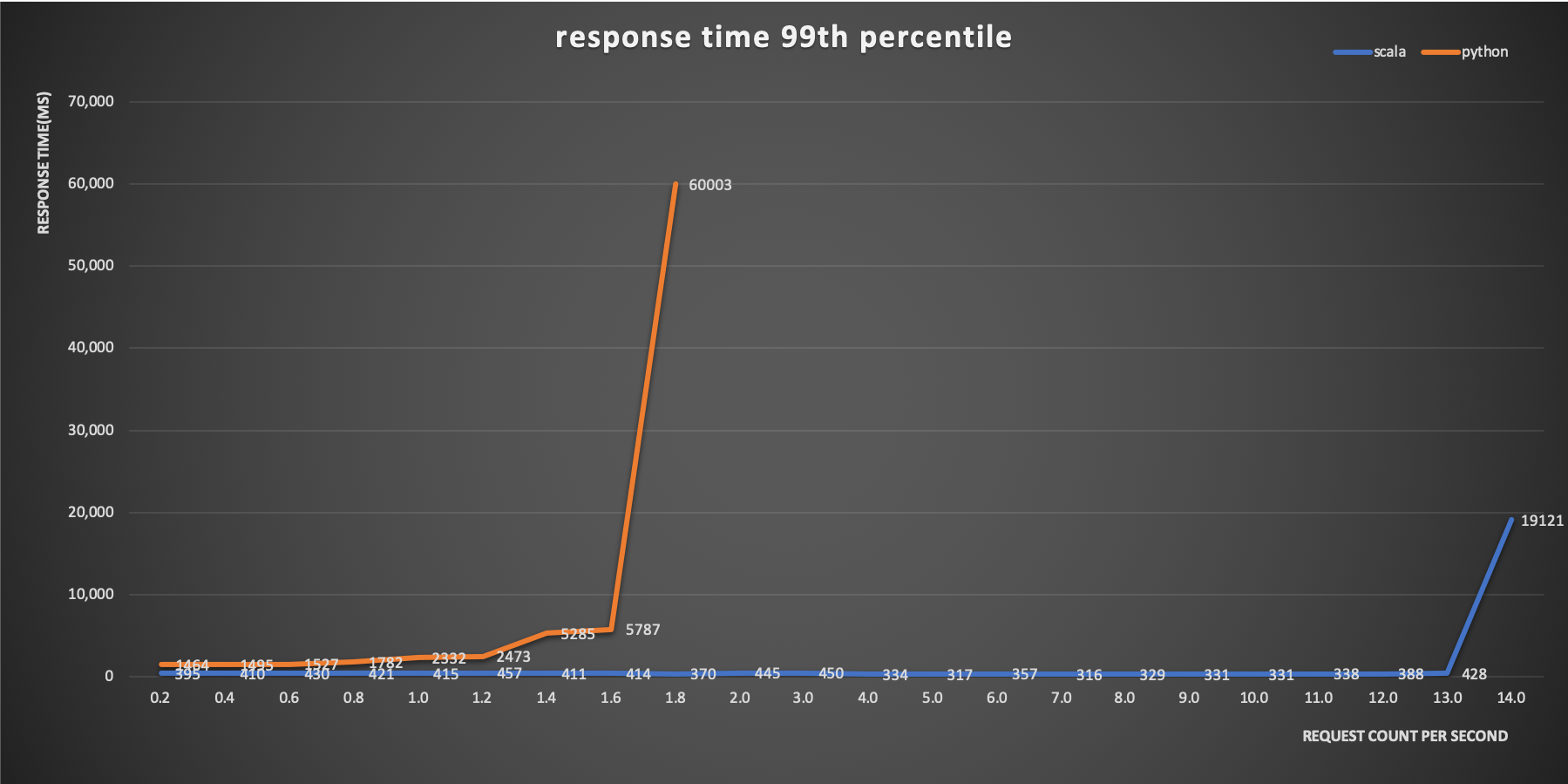
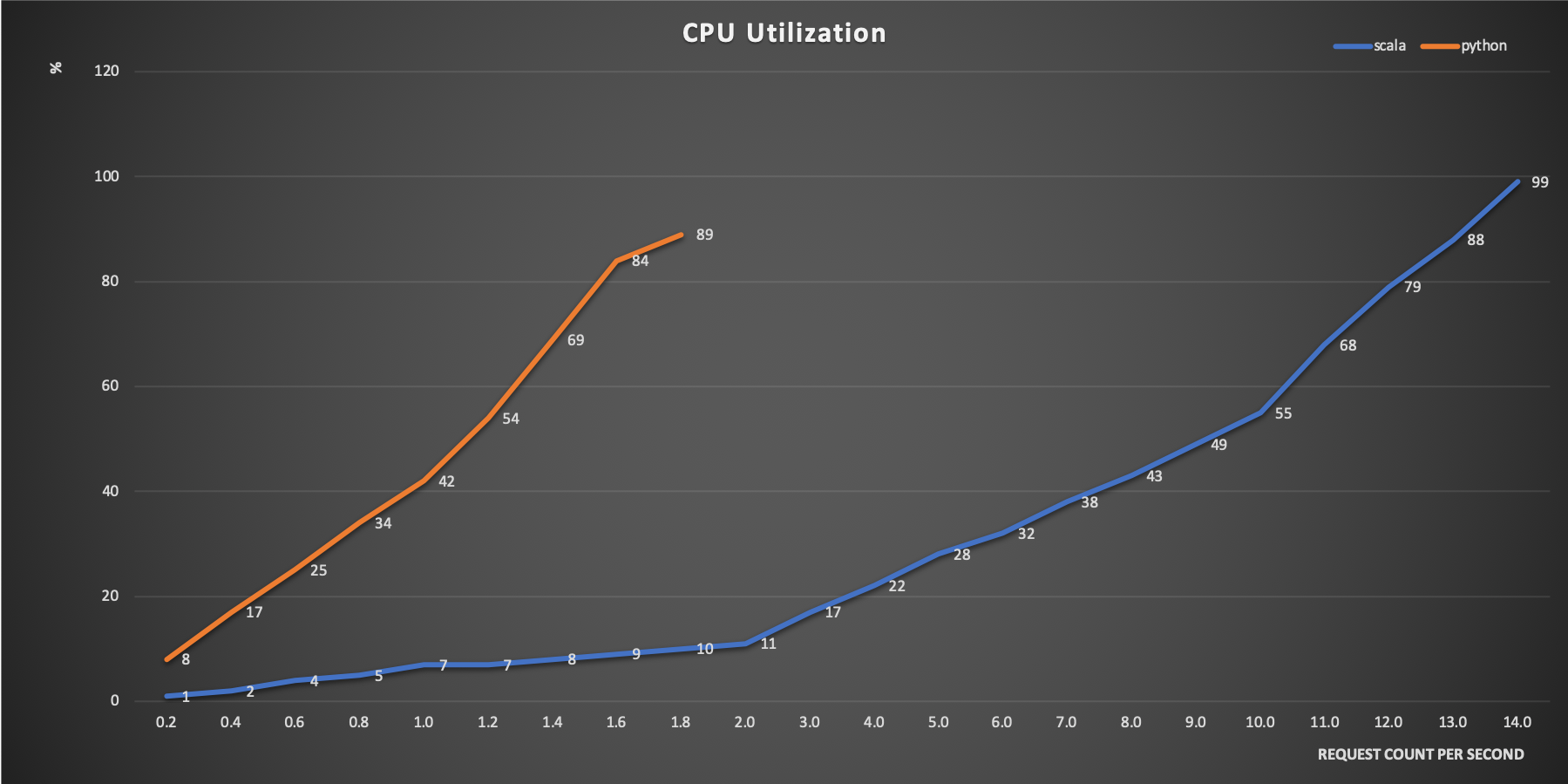
今回は、この中から、 response time 99th percentile の比較をするとともに、AWSのCloudWatchからEC2インスタンスのメトリクスである CPU Utilization の比較を行いました。
結果
Python側は、テストの開始値となる0.2rpsの時点で、Response Timeが1,464msになりました。その後、1.0rpsで2,000ms、1.4rpsで5,000msを超え、1.8rpsでgatlingクライアントのタイムアウトである60,000msにかかりました。CPU使用率も、0.2rpsごとに約8-15%上昇し、1.8rpsのところで約90%に達しました。
一方で、Scala側は0.2rpsから13.0rpsまで、Response Timeは500msを超えませんでした。CPU使用率については、14.0rpsのところで約100%に到達しました。
response time 99th percentile
CPU Utilization
考察
Response Timeについては、最低でも約1秒以上のレイテンシの差が生まれました。これは、Scala側の視点において基本性能としてPythonで実装すること自体が、レイテンシとして約3倍の性能劣化を発生させることを意味します。このことが、いわゆる動的型付け言語が遅いと言われるところの実態であると思います。
また、1台あたりのサーバーが受け付けられる処理量の点においても、CPUのキャップを向かえるリクエスト量としては、約8倍もの差が生まれました。Pythonで13.0rpsのリクエスト量を捌くためには、8台のサーバーが必要になります。これは、単純に月間のコストでScalaで構築したサーバー群が100万円かかるとしたら、Pythonで構築する場合には800万円かかることになります。
総括
この検証を踏まえ、現在ではZOZOSUITのデータを扱うサーバーはPythonで実装されたものからScalaで実装し直したものに置き換えられました。これにより、レイテンシは向上し、サーバーの維持コストも下げることができました。
しかし、Pythonで実装したものをScalaによって実装し直すことによって、誰もがこれと同じ効果を享受するわけではもちろんありません。今回の結果は、リクエスト仕様、フレームワーク、ライブラリ、実装の組み合わせにより生まれた結果であって、この組み合わせが異なれば、この効果がこれよりも小さくなる場合もあるかもしれないし、大きくなるかもしれません。ただ、いずれの場合でもPythonがScalaを上回るということは、意図的な実装をしない限り、起こり得ないのではないかと思います。
今回のテストで使用したScalaは、学習コストが高い、採用コストが高いと言われることがあります。しかし、このテスト結果については、言語によるものというよりは処理系によるところが大きいので、この結果はJVM系言語であるJavaで比較してもそれほど大きな乖離は生まれないと思います。ただ、Javaでさえも学習コストが高いと言われることがあります。そこで考えなければいけないことは、言語の学習コストは一過性であることに対し、サーバーコストはサービスが継続する限りにおいて、断続的に発生するものです。
リリース初期の段階では、こうしたコスト以上に、一日も早くローンチすることを価値とし、投資とみなすこともあるかもしれません。しかし、ユーザーが増え、長く運用していくサービスで扱う処理系、言語を考える場合には、サーバーのリクエスト量が膨らんでいくに連れて、サーバーを増やさなければいけないペースが早くなる技術選択をしていては、コストを圧迫させる可能性があることを忘れてはいけません。こういったインパクトは、損益分岐点で考える黒字化を向かえることを遅らせ、最悪の場合ではサービス維持のためにかかるコストによりビジネスを赤字に転じさせるという事態さえ招く可能性があります。
こうしたお金周りの問題が技術選択の背後に生まれていることは、小さいスタートアップのような規模の会社においては、なかなか気づかれることがありません。それは、ほとんどの場合、関わるエンジニアの嗜好や慣れによって技術選択されることが実態としては多く、多岐にわたって技術選択をするための検証に使う時間やスタッフが足りないこともその要因としてはあるからです。
この記事が、そのような余裕を持つことのできないエンジニア組織、もしくは経営層の方のご参考になれば、幸いです。
-
伸縮センサー方式から画像認識方式へシフトしました。 ↩