2018/2/6追記
Twitter等で質問を頂いたので、その回答などを末尾に補足として追記しました。
2018/2/9追記
ソースコードを公開しました。
https://github.com/coz-a/Audio-Effect-Replicator
サマリ
- LSTMを使って、ギターアンプの音をシミュレートした。
はじめに
昨年の夏にCNNを使ったギター画像の分類にチャレンジしましたが、引き続きギター関連のネタです。今回は音で遊びます。
ご存知の方が多いかと思いますが、さまざまな音源で聞けるエレクトリック・ギターの音は、通常、ギターアンプから出た音です。ギターの出力を直接ミキサーやパソコンのオーディオIFに入力して録音しても、所謂「エレキギターの音」にはなりません。ギターの信号が、アンプの真空管やスピーカーを通して歪むことで、初めてエレキギターらしい音になるのです。
このアンプの歪みをシミュレートするデジタルフィルタは、宅録向けに古くから市販されており、アンプシミュレータと呼ばれています。今回はシンプルな機械学習を使ってこれを実装してみたいと思います。
市販のアンプシミュレータは、様々なノウハウや、人の手と耳によるチューニングでモデルを作りこんでいると思いますが、ここでは機械任せでどこまでいけるかを試してみます。
「フィルタ特性の模倣」は、本質的に機械学習が最も得意とする類のタスクなので、うまくすれば良い結果が得られるはずです。
環境
自宅のパソコンです。
Intel(R) Core(TM) i7-2600 CPU @ 3.40GHz
Memory: 32GB
Geforce GTX 1080 (Founders Edition)
Ubuntu 16.04
Python 3.6.3 :: Anaconda
Keras (backend: Tensorflow)
学習用データセットの準備
今回のチャレンジではギターアンプのモデリングを回帰問題として解きます。説明変数Xはギターからのライン信号、目的変数Yはギターアンプからの出音です。つまり、ライン録音とアンプ録音を同時にして、そのペアを学習用データにします。
本来は本物のアンプを使うべきだと思いますが、今回は面倒なので、市販のアンプシミュレータ(Amplitube 4)を使って教師データを作成します。(つまり、正確にはアンプシミュレータ・シミュレータを作ります)
こちらが入力X。
Guitar Amp Modeling by Machine Learning - Input X https://t.co/issybDBztA
— coz a (@coz_a_1980) 2018年2月4日
そして、こちらが出力Yの教師データです。
Guitar Amp Modeling by Machine Learning - Output Y (Teacher) https://t.co/Ba0rVK3lqB
— coz a (@coz_a_1980) 2018年2月4日
こんな感じのデータを何種類か用意して、学習に利用します。
なお、学習に使うデータは私が適当に弾いたギターをライン録音したもので、16bit 48kHz モノラル、トータル数分程度のWaveファイルです。waveパッケージ経由でNumPyに読み込んだ後、±1.0に正規化して使用します。
学習時には、ここからランダムクロッピングしたデータをモデルに食わせます。
モデルの構築
時系列データといえばRNNですね。(安直)
手軽に使えて幅広く実績のあるものという観点で、今回はLSTMを使います。
LSTMは、そのままだと入力データ長と同じ長さの出力が出てきますが、今回は110ms(=5280サンプル)のデータを入力した際に、モデルから出力されたデータの末尾10ms(=480サンプル)を最終出力として使うことにします。(1サンプルずつだと激遅なので)
推論の際には、入力ストリームに対して10msずつずらしながらSliding-Windowでモデルを適用していくことで、完全な出力ストリームを得ます。(つまり、1秒の出力を得るのに、100回の推論が必要です。)
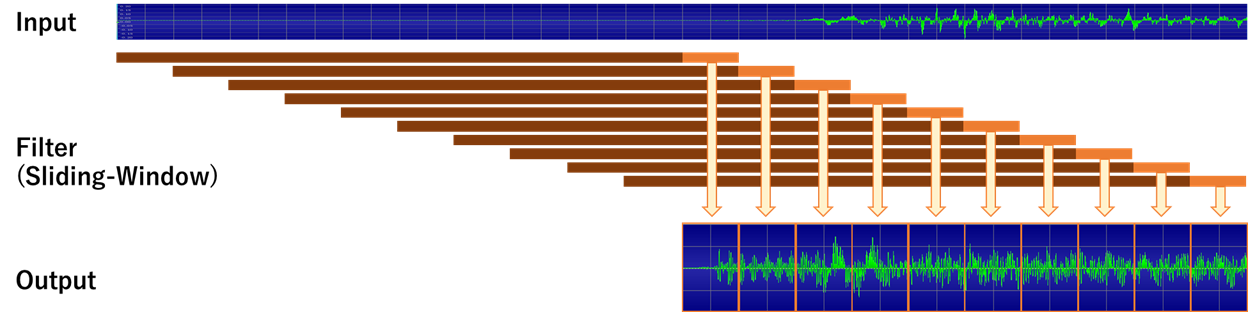
ちなみにWindowサイズが110msというのは、アンプが100ms以上過去の入力に直接影響を受けるような挙動は持たないだろう、という直感からです。ルーム・シミュレーションやスプリングリバーブなどのエフェクトが入ってくればその限りではないと思いますが、今回はドライな音なので、とりあえず良しとします。
モデルの構成はとりあえず『Input ⇒ LSTM(64Cell) ⇒ LSTM(64Cell) ⇒ LSTM(1Cell) ⇒ Output』とします。
Tensorflow/Kerasには、CuDNNを使ってLSTMを高速に処理するCuDNNLSTMという(そのまんま)LSTMの実装が存在するので、これを使っていきます。
また、学習時のロス関数は、出力の末尾480sampleについてのMSEとします。
これは、簡単なロス関数を自作して実現します。
def loss_func(y_true, y_pred):
return mean_squared_error(y_true[:, -480:, :], y_pred[:, -480:, :])
MSEを計算する前に、時間軸でスライスしているだけです。
学習結果
16サンプルのミニバッチ学習100回を1ステップとし、ステップ毎に検証誤差を確認します。
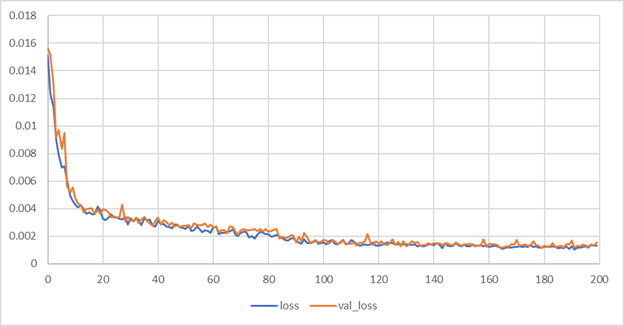
検証誤差は170ステップ程度でおおむね収束し、1.2e-3程度となりました。所要時間は2時間程度です。
推論
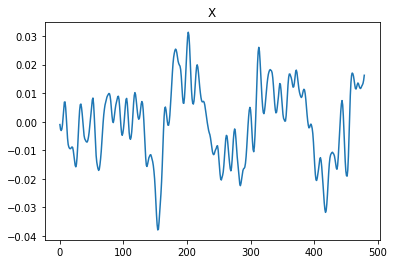
数字だけではよくわからないので、波形の見た目と音を確かめてみましょう。
まず波形の見た目です。
これが入力。
これが出力。
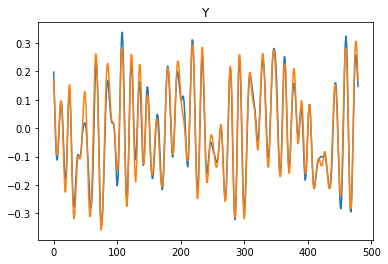
青が教師信号、橙が回帰モデルの出力です。
多少形状が変化するものの、おおむね追従できているように見えます。
聴感上はどうでしょうか。
これが回帰モデルの出力です。
Guitar Amp Modeling by Machine Learning - Output Y (Predicted) https://t.co/2VxZZodL5B
— coz a (@coz_a_1980) 2018年2月4日
上の方に載せた教師信号の音と比べてみてください。
若干ダイナミックレンジが狭いように感じますが、かなり再現性が高いことがわかります。
ほぼ完全にマーシャルの音です。
感想
こんな単純なモデルと手法でアンプのシミュレーションができてしまうという事に驚きを隠せません。
本物のアンプを使って真面目にこれをやったら、もしかすると市販のアンプシミュレータより良いものができてしまうかも。
色々と試した感じでは、LSTM層の数とセル数を増やすことで、ロス・音質はもう少し改善できそうです。
実用上は 1.リアルタイム性(遅延)、2.パラメトリックな音作りの2点が課題になるかと思いますが、前者については推論向けコプロセッサ(Movidiusとか)をうまく使えば解消できそうな気がしますし、後者はパラメータ(e.g.アンプのツマミの値)の変化も入力として食わせることで、パラメータ変化に対する挙動まで学習できそうです。
これ、マジでLine6・Boss・Zoomあたりで作りませんかね。(もう似たようなことを研究してるかもですが)
補足
Twitter等で質問を頂いたので、回答しておきます。
Q.
汎化性能はどうなの?トレーニングデータでなくても、ちゃんとアンプの音になるの?
A.
いくつか試した範囲では、どのギターの音でも破綻なく鳴ります。
簡単のために詳しくは書いていませんが、記事で掲載している音声データはすべてValidation用のデータで、学習には他の録音データを使っています。したがって、上で聞ける音源もまた汎化の一例です。
参考に、最初とは別のギター・別のフレーズの音源を追加で掲載しておきます。
Guitar Amp Modeling by Machine Learning - Part 2 https://t.co/xG15H2v388
— coz a (@coz_a_1980) 2018年2月5日
手持ちの音源を変換してみたいという奇特な方がいらっしゃいましたら、音声データを送りつけて頂ければ検証します。コンタクトはTwitterから。
ソースコードは、ちょっと整理してから公開するつもりです。(→2/9 公開しました。)
(あんまり綺麗じゃないので、下手なギターを晒すのと同じくらい恥ずかしい)