こんにちは!GoogleAppsScriptを使った業務効率化に夢中の初心者プログラマー、太郎です。
今日はGoogleAppsScriptでスクレイピングする方法について書いていきたいと思います。
これから実際に実装にトライするため、途中詰まるところもあれば、心の声がだだ洩れになるところもあるかと思います。結論から知りたい方は、最後のまとめをご覧ください。
初心者向けですが、HTML、CSS、javascriptの基本的なルールは押さえておいた方が理解はしやすいと思いますので、まだの方はProgateでサクッと学習してみてください。
また、スクレイピングする際に正規表現を使っています、こちら非常に便利なので、ぜひ学習してみてください。非常にシンプルなのでこちらの本がお勧めです。
JavaScriptで正規表現のニガテを克服するための本
では、早速トライしていきましょう!
UrlFecthAppを使ってみる
GASでスクレイピングをするための方法は、検索するとけっこう出てきますね。UrlFetchAppというクラスを使ってこんな風に書くと良さそうです。
const html = UrlFetchApp.fetch(url).response.getContentText('UTF-8');
このように書くと、URLで指定したページのHTMLを取得できます(データ型はString)。
urlには取得したいページのURLを入力してください。今回は、Googleで検索した結果を取得したいと思います。
Googleでの検索結果を表示するURLはこんな構造。(参照はこちらの記事)
https://www.google.com/search?q=(検索ワード)&num=(1ページ当たりの表示数)
この検索ワードは、URIの形にエンコードしなければなりません。そのためのメソッドもGASには用意されています。今回は、「GAS スクレイピング」と検索することにしましょう。
検索ワードをエンコードしてURLに入れるコードは以下。
const firstWord = "GAS";
const secondWord = "スクレイピング";
const encodeFirstWord = encodeURI(firstWord);
const encodeSecondWord = encodeURI(secondWord);
const displayNum = 20;
const url ="https://www.google.com/search?q=" + encodeFirstWord + "+" + encodeSecondWord + "&num=" + displayNum;
複数検索する場合は、エンコードした検索ワードを『+』でつないであげればOKです!
得られるURLはこのように検索ワードがエンコードされます。
https://www.google.com/search?q=GAS+%E3%82%B9%E3%82%AF%E3%83%AC%E3%82%A4%E3%83%94%E3%83%B3%E3%82%B0&num=20
あっ、『GAS』はされないんですね。あんまり知識ないので知りませんでしたが、、、
このURLを出力してみると、
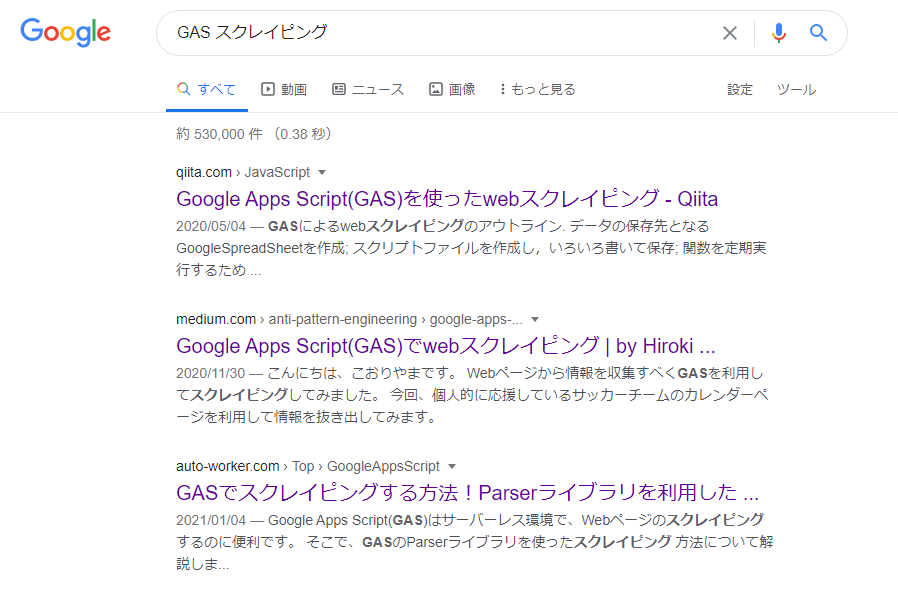
はい、このように検索結果のページを表示できます。あとはこのURLからfetchメソッドでHTMLを取得
します。
const html = UrlFetchApp.fetch(url).getContentText("utf-8");
はい、できると思ったのに謎のエラー出ました。。。

Exception: Request failed for https://www.google.com returned code 429.
う~む、どういうことか分からない。。。
試しに全く別のサイトで試してみたところ、普通に動きました。。。これはGoogle特有なのでしょうか???
調べてみると、429エラーというものは、一定期間に大量のHTTPSリクエストをしてしまった場合に起こるエラーみたいです。
もしかしたらGoogleの規約上、そもそもアウトな可能性があるのか???
必死に検索したところ、こんな記事がありました!どうもmuteHttpExceptionsというものを指定してあげればよいそうで。。。
試しに以下のように書いてみると。
const options = {muteHttpExceptions:true};
const html = UrlFetchApp.fetch(url, options).getContentText("utf-8");
無事HTMLを取得できました!!!取得したHTMLは長いけれどこんな感じ。
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head><meta http-equiv="content-type" content="text/html; charset=utf-8"><meta name="viewport" content="initial-scale=1"><title>https://www.google.com/search?q=GAS+%E3%82%B9%E3%82%AF%E3%83%AC%E3%82%A4%E3%83%94%E3%83%B3%E3%82%B0&num=100</title></head>
<body style="font-family: arial, sans-serif; background-color: #fff; color: #000; padding:20px; font-size:18px;" onload="e=document.getElementById('captcha');if(e){e.focus();}">
<div style="max-width:400px;">
<hr noshade size="1" style="color:#ccc; background-color:#ccc;"><br>
<form id="captcha-form" action="index" method="post">
<script src="https://www.google.com/recaptcha/api.js" async defer></script>
<script>var submitCallback = function(response) {document.getElementById('captcha-form').submit();};</script>
<div id="recaptcha" class="g-recaptcha" data-sitekey="6LfwuyUTAAAAAOAmoS0fdqijC2PbbdH4kjq62Y1b" data-callback="submitCallback" data-s="dwQ8X62iEo09Yopv_kNpT_aCQ-dhhSNTQSwxg_QncMjhK7ierGbZsaEHYHC3XZ2fkHOnk0FOs8OBG4v9OtgtUREWuH9n7XKJQ1478-hMhBB-uPQ4tXjTOXNCo2Uggd3tFxGWvCkYyKOFNEO4YEwFpi5zV8f_UBq2BeTyXEuy1oIUr4vgwmFMvJvtGIhs4Pmf2rK3IloGKxs1Di-omSJdJnZ0VREP54mnfqnbIV0BvBAcAw0G2WpJXu4"></div>
<input type='hidden' name='q' value='EgQju4QaGL_EloEGIhkA8aeDS_zefxaMwiWdDqr_PwrV2UEBw0_9MgFy'><input type="hidden" name="continue" value="https://www.google.com/search?q=GAS+%E3%82%B9%E3%82%AF%E3%83%AC%E3%82%A4%E3%83%94%E3%83%B3%E3%82%B0&num=100">
</form>
<hr noshade size="1" style="color:#ccc; background-color:#ccc;">
<div style="font-size:13px;">
<b>About this page</b><br><br>
Our systems have detected unusual traffic from your computer network. This page checks to see if it's really you sending the requests, and not a robot. <a href="#" onclick="document.getElementById('infoDiv').style.display='block';">Why did this happen?</a><br><br>
<div id="infoDiv" style="display:none; background-color:#eee; padding:10px; margin:0 0 15px 0; line-height:1.4em;">
This page appears when Google automatically detects requests coming from your computer network which appear to be in violation of the <a href="//www.google.com/policies/terms/">Terms of Service</a>. The block will expire shortly after those requests stop. In the meantime, solving the above CAPTCHA will let you continue to use our services.<br><br>This traffic may have been sent by malicious software, a browser plug-in, or a script that sends automated requests. If you share your network connection, ask your administrator for help — a different computer using the same IP address may be responsible. <a href="//support.google.com/websearch/answer/86640">Learn more</a><br><br>Sometimes you may be asked to solve the CAPTCHA if you are using advanced terms that robots are known to use, or sending requests very quickly.
</div>
IP address: 35.187.132.26<br>Time: 2021-02-11T21:31:43Z<br>URL: https://www.google.com/search?q=GAS+%E3%82%B9%E3%82%AF%E3%83%AC%E3%82%A4%E3%83%94%E3%83%B3%E3%82%B0&num=100<br>
</div>
</div>
</body>
</html>
ん???よく読んでみると日本語の情報が一切ないぞ。。。あっ、こんな記述が、、、
Our systems have detected unusual traffic from your computer network. This page checks to see if it's really you sending the requests, and not a robot.
簡単に訳すと、『通常出ないリクエストを受けました。あなたロボット(プログラム)使って検索してないですか???』
ごめんなさい。しました。。。あっ、これダメなんですね。すみません。Googleさん。。。
クックパッドを検索することにした
そんなわけで、Google検索の方は、なんかダメそうなので、一旦、他のサイトを見てみたいと思います。とりあえずよく使用するサイト、cookpadさんで試してみます(スクレイピングしようとしているサイトの利用規約は念のため確認しましょう)。
クックパッドでレシピを検索する際のURLは
https://cookpad.com/search/(検索ワード)?order=date&page=(ページ数)
となっています。複数検索をしたい場合は、検索ワードの間に%20(空白を意味)を入れてあげると良さそうですね。
試しに、「豚肉」で検索してみた場合の1ページ目を取得してみます。
const searchWord = "豚肉";
const encodeSearchWord = encodeURI(searchWord);
const pageNum = 1;
const url = 'https://cookpad.com/search/'+ encodeSearchWord +'?order=date&page=' + pageNum;
const options = {muteHttpExceptions:true};
let responseText = UrlFetchApp.fetch(url, options).getContentText();
この結果を出力してみると分かるんですが、思ったように情報が取れません。。。
どうもログに出力するにはコードが長すぎたようですね。Googleドキュメントに出力すると、無事データ取れました!
さて、ここから欲しいデータを抽出していきましょう!!!
検索した結果を検索
クロームの標準機能、ページのソースから、抜き出したいデータの位置を確認します。
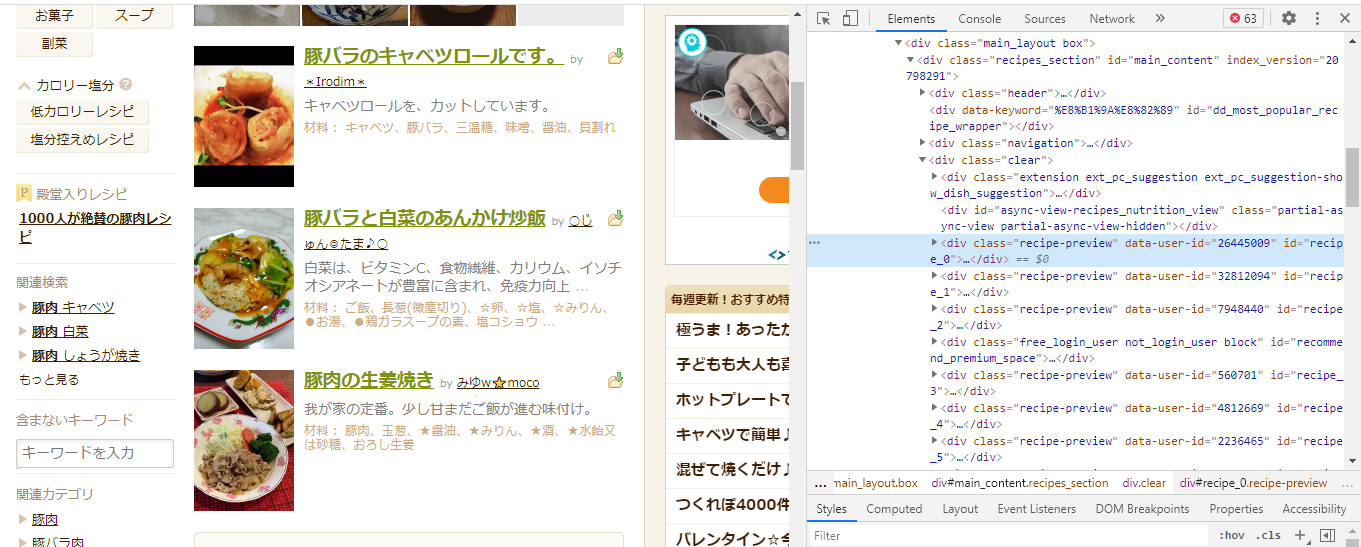
今回欲しいのは、検索結果の『タイトル』とその『URL』です。
その部分のソースを確認してみると(カーソルマークをクリックしてコードを見たい部分をクリックします)
<a class="recipe-title font13 " id="recipe_title_6649533" href="/recipe/6649533">圧力鍋で簡単トロトロ豚バラ白菜</a>
こんな感じで書いてあります。URLはレシピごとの番号、上の例でいう6649533をhttps://cookpad.com/recipe/の後に追加してあげればOKです。なのでこのaタグの情報を上手く抜き出せれば良さそうですね。
まず、おおざっぱに該当のaタグを抜き出します(変数の命名規則とか全然考えられてないのでめちゃめちゃです。。。)
let _recipeList = responseText.match(/<a class="recipe-title font13.*<\/a>/g);
matchの中に書いてあることを簡単に訳すと
<a class="recipe-title font13から始まって、</a>で終わる部分を抜き出します!
という感じです。そんなに複雑な記述ではないので正規表現を少し学んだ方なら簡単に理解できると思います(というかそんなに複雑なことはまだ記述できない)。
この結果を出力するとこんな感じ。
[
<a class="recipe-title font13 " id="recipe_title_6643532" href="/recipe/6643532">豚バラのキャベツロールです。</a>,
<a class="recipe-title font13 " id="recipe_title_6649533" href="/recipe/6649533">圧力鍋で簡単トロトロ豚バラ白菜</a>,
<a class="recipe-title font13 " id="recipe_title_6646968" href="/recipe/6646968">豚肉の生姜焼き</a>,
//(以下略)
]
aタグを無事配列として取得できました。欲しいのは、レシピごとの番号とタイトルです。これを正規表現を使って抜き出していきます。こんな風に書くと
let _a = '<a class="recipe-title font13 " id="recipe_title_6643532" href="/recipe/6643532">豚バラのキャベツロールです。</a>';
let a = _a.replace(/<a.*recipe\/|<\/a>/g, "");
Logger.log(a);//出力結果 6643532">豚バラのキャベツロールです。
let b = a.split('">');///レシピ番号とタイトルの間の記号を除去し、配列で取得
Logger.log(b);//出力結果 [6643532, 豚バラのキャベツロールです。]
きっともっとうまく書く方法はあると思うのですが、いずれにしてもこの書き方でレシピ番号とレシピタイトルを取得できました!
あとは、レシピ番号をURLの形にしてあげればOKです!まとめるとこんな感じですね。
for (i = 0; i < _recipeList.length; i ++ {
let _recipeData = _recipeList[i].replace(/<a.*recipe\/|<\/a>/g, "");
let recipeData = _recipeData[i].split('">');
let recipeName = recipeData[1];
let recipeUrl = "https://cookpad.com/recipe/" + recipeData[0];
}
_recipeListには10個のデータが格納されているので、for文で繰り返してあげましょう。ここまで出来たら、あとは、取得したレシピタイトルやレシピURLを使いたいように使いましょう。ちなみに、現在は検索1ページ目までしか検索で来てないですが、10ページまでデータを取得したいので、そのように書いてみますね。
まとめ-Webページをスクレイピングする方法
今回、クックパッドの検索結果を取得するコードを書いてみました。まとめるとこんな感じです。
function getRecipe() {
const searchWord = "検索したいワードを入力";
const encodeSearchWord = encodeURI(searchWord);//ワードをエンコーディング
for (j=1; j<11; j++) {//10ページ目までの検索結果を取得
const pageNum = j;
const url = 'https://cookpad.com/search/'+ encodeSearchWord +'?order=date&page=' + pageNum;
const options = {muteHttpExceptions:true};
let responseText = UrlFetchApp.fetch(url, options).getContentText();
// レシピタイトルなどが書いてある部分をおおざっぱに抜き出す
let _recipeList = responseText.match(/<a class="recipe-title font13.*<\/a>/g);
if (j>1 && _recipeList === null) {// 検索ページが無くなった時点で処理を終了する
continue;
} else if (j===1 && _recipeList === null){// 検索結果が取得できなかった場合、処理を終了する
return Browser.msgBox("レシピが存在しません");
} else {
for (i=0; i<_recipeList.length; i++) {
let _recipeData = _recipeList[i].replace(/<a.*recipe\/|<\/a>/g, "");
let recipeData = _recipeData[i].split('">');
let recipeName = recipeData[1];
let recipeUrl = "https://cookpad.com/recipe/" + recipeData[0];
}
}
Utilities.sleep(1500);//サーバーに負担をかけないように。1.5秒のスリープタイムを取る
}
}
最後、情報量が増えてしました。大切なところは、Utilities.sleepのところですね。スクレイピングはやり過ぎると相手方のサーバーにかなりの負荷をかけてしまうようです。そのため、小さな処理を小出しに行うことが推奨されていて待機時間を1.5秒に設定します(for文を繰り返すたびに1.5秒インターバルが入ります)。
以上、参考になれば嬉しいです。今後も様々トライしてみた結果を記事に書いていきたいと思います!