小規模LLMを1つのインスタンスで効率よく動かすにはどうすればいいのか気になったのでメモ
はじめに
AI推論の現場では、コスト効率とパフォーマンスの両立が大きな課題です。特に、小規模なLLM(Large Language Model)を複数同時に運用したい場合、GPUリソースをいかに有効活用するかが重要になります。
本記事では、Amazon SageMakerのMulti-Model Endpoints(MME)とNVIDIA Triton Inference Serverを活用し、GPUリソースの効率的な活用方法を具体的な設定例とともに解説します。
「小規模LLMをコスト効率よく動かしたい」「推論環境の最適化を目指したい」方はぜひ参考にしてください。
基本用語の解説
Multi-Model Endpoints(MME)とは?
Amazon SageMaker Multi-Model Endpoints(MME) は、AWSの機械学習サービスであるSageMakerが提供する機能のひとつです。
従来、SageMakerでモデルをデプロイする場合、「1つのエンドポイントにつき1つのモデル」という制約がありました。
MMEを使うことで、1つのエンドポイント上に複数の機械学習モデルを同時にホスト・管理できるようになります。
このMMEにはNVIDIAのTriton Inference Server が活用されております。
by Run multiple deep learning models on GPU with Amazon SageMaker multi-m...
なお、SageMaker Multi-Container Endpoints(MCE)はGPUインスタンスを選ぶことができません。(2025/06/23現在)
Triton Inference Serverとは?
Triton Inference Server は、AI モデルのデプロイと実行をあらゆるワークロードで標準化するオープンソース ソフトウェアです。
NVIDIA Triton を使用すると、任意のプロセッサ (GPU、CPU、その他) 上で、任意のフレームワークからトレーニング済みの機械学習やディープラーニング モデルの推論を実行できます。
GPU利用効率化の2つのアプローチ
1. Concurrent model execution(並列モデル実行)
同じGPU上で複数のモデルインスタンスを同時に動かす機能です。
これにより、リクエストの混雑時にも効率よくリソースを使えます。
設定例
Triton Inference Serverがモデルをロード・実行する際に必要な設定情報を記述するファイル config.pbtxt に instance_group を設定することで実現できます
例)
instance_group [
{
count: 2. # GPU 0上に2インスタンス
kind: KIND_GPU
gpus: [0]
},
{
count: 3
kind: KIND_GPU
gpus: [1, 2] # GPU 1と2上に3インスタンスずつ
}
]
2. Dynamic Batching(動的バッチ処理)
推論リクエストを動的に結合し、単一のバッチとして処理する機能です。クライアントから個別に送信されたリクエストをサーバーサイドで統合し、GPUの演算効率を最大化します。
動作プロセス
- リクエスト受信:クライアントから個別の推論リクエストが到着
- キューイング:max_queue_delay_microsecondsで設定した時間だけ待機
- バッチ形成:待機中に到着したリクエストをmax_batch_sizeまで結合
- 一括処理:形成されたバッチを単一の推論ジョブとしてGPUに送信
設定例
Triton Inference Serverがモデルをロード・実行する際に必要な設定情報を記述するファイル config.pbtxt に dynamic_batching を設定することで実現できます
例)
dynamic_batching {
max_queue_delay_microseconds: 100 # 100ms毎にバッチ処理
}
Concurrent model executionとDynamic Batchingの図解
Dynamic Batchingを利用した例
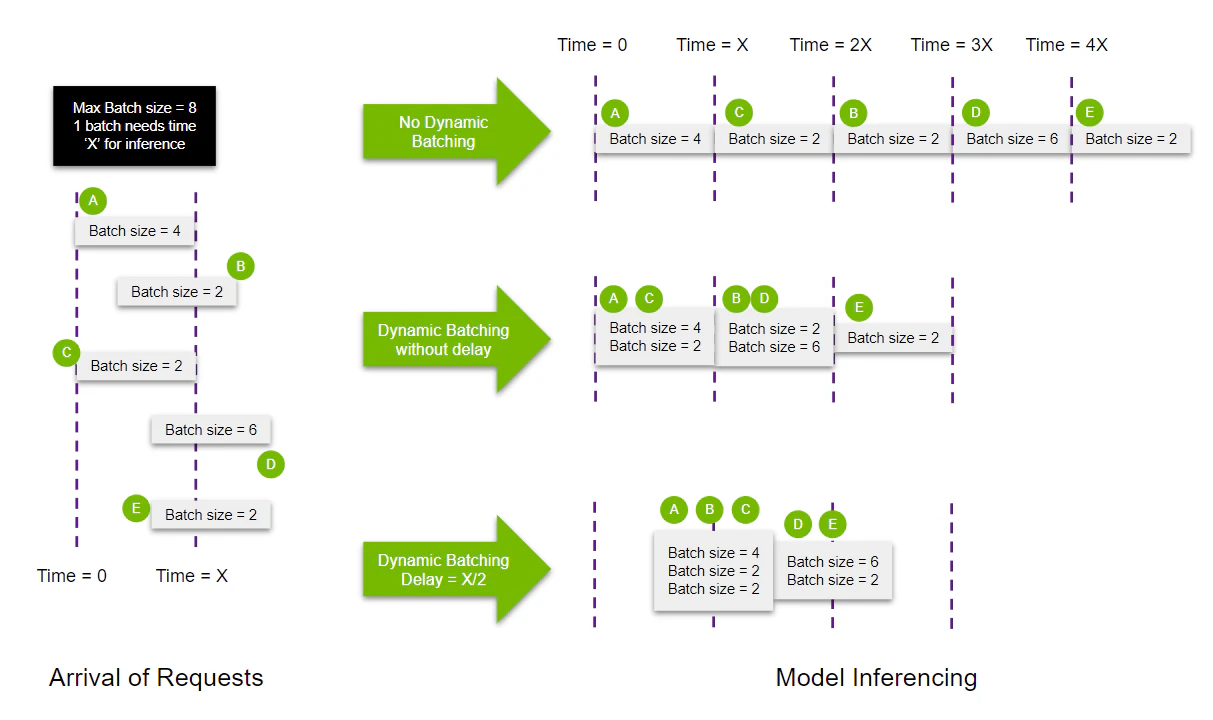
by https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/tutorials/Conceptual_Guide/Part_2-improving_resource_utilization/README.html#what-is-dynamic-batching
Dynamic BatchingとConcurrent model executionを組み合わせた例
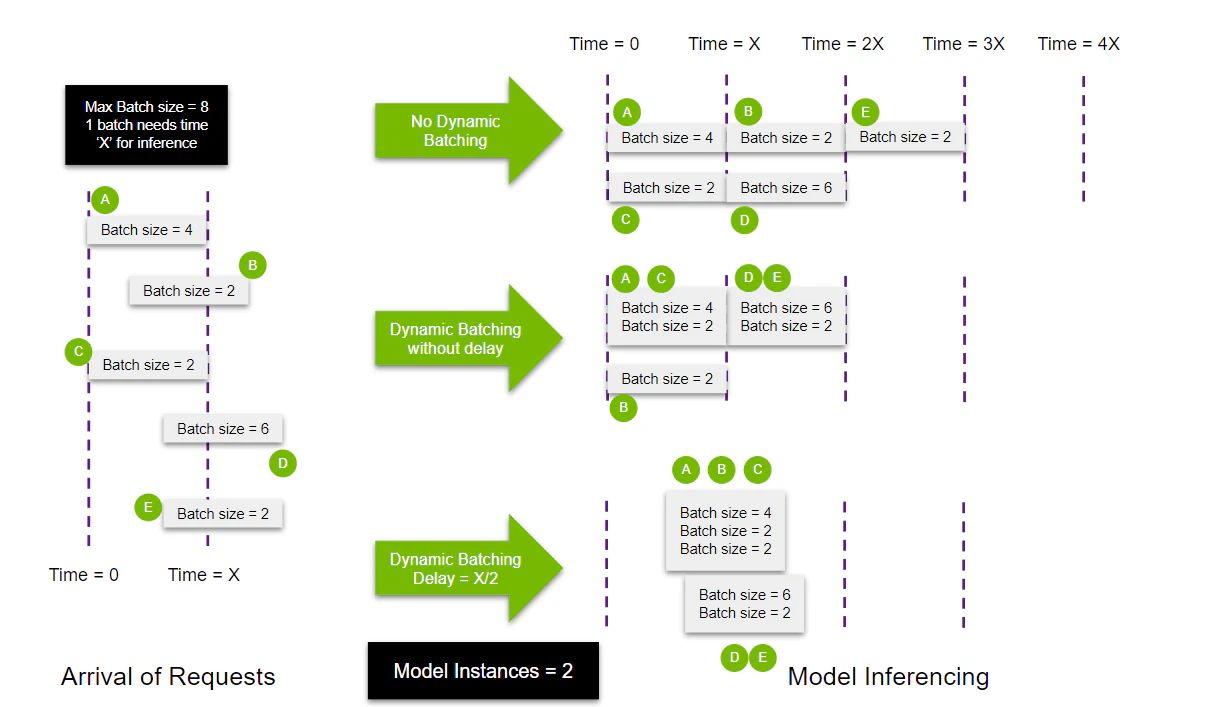
by https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/tutorials/Conceptual_Guide/Part_2-improving_resource_utilization/README.html#concurrent-model-execution
以下パフォーマンス測定では、何もしていない状態と比べ4倍近くスループットが上昇しレイテンシも約70%改善しておりGPUをより効果的に利用しています
まとめ
必要なGPUリソースが少ないモデルを推論するときは、モデルの必要なサイズに合わせるのではなくDynamic BatchingとConcurrent model executionを加味したインスタンス選定をすることでよりコスト効率の高い環境を用意することができます。
おまけ
複数のBERTモデルをSageMaker Multi-Model Endpoint (MME) 上にデプロイするノートブックを書いてみたのでもしよければどうぞ
お約束
Qiita上の私の記事・コメントは個人的な意見に基づくものであり、所属する組織、団体とは一切関係ありません。