はじめに
こんにちは。42 Tokyoというエンジニア養成機関の 2023 年度アドベントカレンダー 4日目を担当します、在校生のyokawadaと申します。
この記事では、ハッシュ関数に対する伸長攻撃という攻撃手法について短くまとめてみます。
本当はこんな記事書いている場合ではないんですが・・・
Excuse - 1
本来は12/9分のアドカレ記事の一部だったのだが、かなりややこしい内容になったので単体記事として分離した。
(そのため全体的に勢いで書いた内容になっている。)
さらにアドカレの12/4の枠が空いていたのでぶち込んだ。
Excuse - 2
筆者はセキュリティミリ知ら勢なので、記事の間違いなどに関する指摘・訂正は遠慮なくお願いしたい。
今北産業
- 計算前処理としてパラメータの前に秘密情報(ソルト)を付加するタイプのハッシュ関数※に対して
- パラメータとそのハッシュ値、および内部実装の情報から「与えられたパラメータに対するハッシュ値」をソルトなしで予測する攻撃。
- ただし、予測できるパラメータには制限※※がかかる。
※ ソルトを付加しない場合でも攻撃できるが、その場合わざわざ攻撃する必要がない。
※※ 個人的な印象ではこの制限はあまりに強すぎると思うのだが、それでも使い道はあるらしい・・・
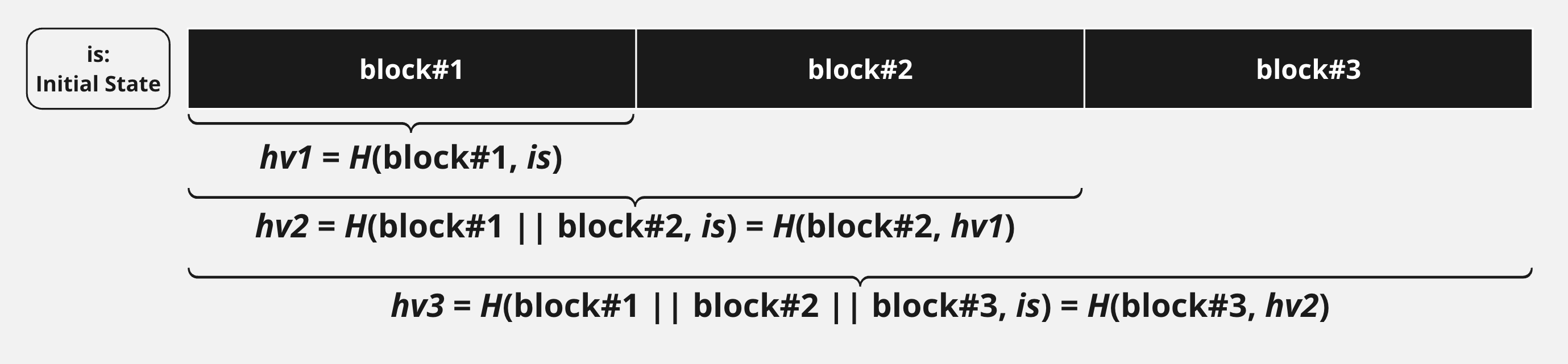
図解

上図における記号の定義はこの後の定義とほとんど同じなので、ノリで理解してください。
ハッシュ関数の定義
ハッシュ関数$H$を次のように定義する。
$$
hv = H(x, is)
$$
ここで、
- $hv$ ハッシュ値
- $x$ ハッシュ関数のパラメータ。
- $x$の長さを$L_x$とする。$L_x$はブロック長$M$の整数倍になっているものとする。
- $is$ 初期状態
- ハッシュアルゴリズムの仕様で定められた定数であるのが普通。
また、二項演算$||$をビット列の連結として定義する。
さらに、ハッシュ関数$H$の内部処理が以下のようになっているとする:
-
メッセージを$M$ビットごとのブロックに分割する。分割後のブロックの数は $n = L_x/m$ 個になる。
$$
m_p \rightarrow b_1, b_2, ..., b_n
$$ -
関数$h$を, ブロック1つと状態1つを受け取り, 状態を返す関数として定義する。
$$
s' = h(b, s)
$$ -
先頭のブロックから順に, 関数$h$を順番に適用していく。
$$
s_{i} = h(b_i, s_{i-1})\
s_0 = is
$$ -
全てのブロックを適用した後で、最後の状態$s_{n}$をハッシュ値とする。
$$
hv = s_n
$$
※ 実質これは「$H$がMerkle-Damgård構造を持つ」と言っている。
※※ 伸長攻撃はMerkle-Damgård構造だけに可能なわけではないが、もう色々面倒になったのでMerkle-Damgård構造に話を限定する。
伸長攻撃の目的
まず攻撃対象。
- $F(m)$: 以下の処理を順に行う関数:
- 入力メッセージ$m$の前に秘密情報(ソルト)$s$を付加する。
- さらに長さがブロック長$M$の整数倍になるようパディングデータ$p$を付加する。
- それをハッシュ関数H$に入力して結果を返す。
数式として書くと:
$$
F(m) = H(s || m || p, is).
$$
そして、以下が既知であるとする:
- $H$: ハッシュ関数。具体的なアルゴリズムがわかっている、という意味。
- $m_0$: サンプル対象メッセージ。$F$への入力となる。
- $hv_0 = F(m_0)$: つまりサンプルメッセージによるハッシュ値。
- $F$に$m_0$を入力した時のパディング内容$p_0$
- $H$がわかっていれば比較的容易に総当たり可能なはずなので、最悪知らなくてもOK
そのもとで「任意の別のメッセージ$a$に対して、ハッシュ値$F(m_0 || p_0 || a)$ を、$s$を知ることなしに得る」のが目的。
※ $F(m_0||a)$が得られるわけではない。
※※ もちろん $F(a)$が得られるわけでもない。
※※※ $F(p_0 || a)$ が得られるわけでもない。
※※※※ $F(m_0) = F(a)$となる$a$が見つけられる(第2種原像攻撃)・・・わけないだろ!
伸長攻撃の手順
- メッセージ$m_0$とそのハッシュ値$hv_0 = F(m_0)$をなんとかして手にいれる。
- 初期状態を任意に指定可能、かつパディングを行わない$H$の実装をなんとかして用意する。
- 普通のハッシュコマンド(
shasum,opensslなど)は初期状態を指定できないはずなので、自作するかツールを引っ張ってくる。
- 普通のハッシュコマンド(
- $hv' = H(a || p_a, hv_0)$を計算する。
- ここで$p_a$は, $F$に$s || m_0 || p_0 || a$を入力した時のパディング内容。$p_0$がわかるならこれもわかるはず。
- 初期状態の代わりに$hv_0$を使うところが核心。
もし$F$に対する伸長攻撃が可能であれば、計算した$hv’$が$F(m_0 || p_0 || a)$に等しいはずである。
なぜ H(a || pa, hv0) = F(m0 || p0 || a)が言えるのか
厳密に説明すると文章が長くなるのでお気持ちだけ述べる。
$s||m_0||p_0$の情報が$H$を通して$hv_0$に集約されるため、$H$において
「初期状態として$is$ではなく$hv_0$を使うこと」が
「$a$の前に$s_0 || m_0 || p_0$ を付加すること」とほぼ同じになる。
(ただし$s||m_0||p_0$の長さだけは$p_a$に影響する。)
対策
-
Merkle-Damgård構造を使わないこと
- Merkle-Damgård構造だけがダメなわけではないのだが、Merkle-Damgård構造のように「ある種の加法性」を持っていると伸長攻撃ができてしまう。
- SHA-3(Keccak)はMerkle-Damgård構造とは別の構造を持ち、伸長攻撃が効かない。
-
HMACを用いること
- 「ある種の加法性」を破壊できるため。
-
ハッシュ関数の結果を一部切り捨てること
- 例えばSHA-512/256は、SHA-512の結果(512ビット)の先頭256ビットだけをハッシュ値とするため、「ある種の加法性」が消滅する。
- 具体的には「全てのブロックを適用した後で、最後の状態$s_{n}$をハッシュ値とする。」が失われる。
- 例えばSHA-512/256は、SHA-512の結果(512ビット)の先頭256ビットだけをハッシュ値とするため、「ある種の加法性」が消滅する。
参考文献
伸長攻撃についてのWikipedia(en)記事
伸長攻撃についての日本語の記事。読みやすさと正確性のバランスがよい(主観)。
Merkle–Damgård構造についてのWikipedia(en)記事
おわりに
printf("明日は %s さんが %s について書いてくれる予定ですので、そちらの記事もお楽しみに!", next_author, next_title);
埋まるといいよね。