はじめに
ここ最近 kubernetes (k8s) 上でのアプリ開発なんかにも関わるようになったのですが、EKS 上で動かしていたシステムをローカル環境 (microk8s) に持ってきたら特定のコンテナだけ名前が引けなくなって動かない、という現象にぶち当たって数日溶かしてしまったので、その話をしようと思います。
要約
以下の要因が組みあわさることで、k8s 上の Alpine linux ベースのコンテナではうまく名前を解決できないことがあります。
- k8s はデフォルトではローカルドメインの名前を優先して解決する (
/etc/resolve.confのndots: 5) - k8s 外部へ名前を問い合わせるときに、問い合わせ先の DNS サーバが本来 NXDOMAIN を返すべきところ、そうなっていないケースがある
- Alpine linux は一般的な lInux ディストリビューションで使われている glibc ではななく musl libc が使われており、DNS名前解決(を含むいくつかの点)で glibc と動作が異なる
Workaround
-
/etc/resolv.confでndots: 1に変更する
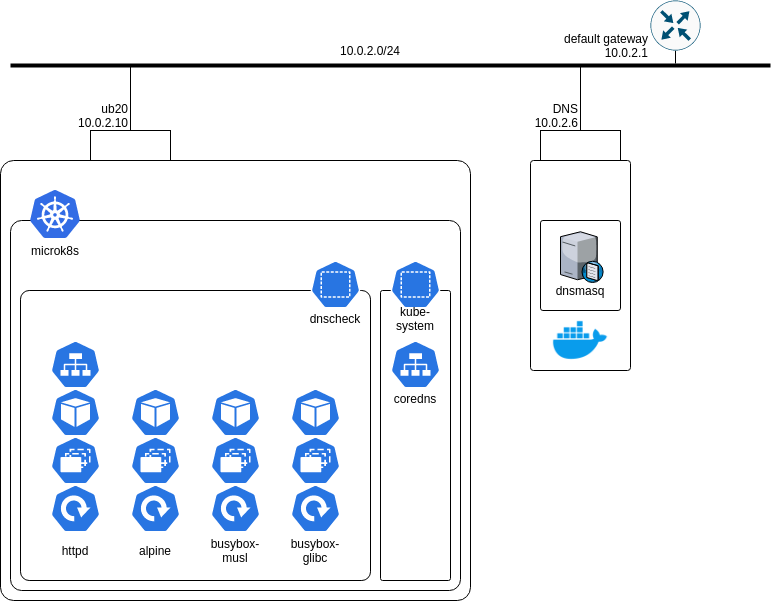
検証環境
Virtualbox でふたつのVMを立てています。
- ub20
- Ubuntu 20.04.1 + microk8s 1.19.3
- alpine 3.12.1, busybox 1.32.0
- DNS
- Ubuntu 20.04.1 + docker 19.03.8 + jpillora/dnsmasq
---
apiVersion: v1
kind: Namespace
metadata:
name: dnscheck
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: alpine-deployment
namespace: dnscheck
spec:
replicas: 1
selector:
matchLabels:
app: alpine
template:
metadata:
labels:
app: alpine
spec:
containers:
- image: alpine:3.12.1
name: alpine
tty: true
---
apiVersion: v1
kind: Service
metadata:
name: httpd-service
namespace: dnscheck
spec:
type: NodePort
selector:
app: httpd
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
nodePort: 30080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpd-deployment
namespace: dnscheck
spec:
replicas: 1
selector:
matchLabels:
app: httpd
template:
metadata:
labels:
app: httpd
spec:
containers:
- image: httpd:2.4.46
name: httpd-webserver
図中、busybox コンテナなんかもおまけで入れてありますが本筋は alpine の名前解決動作について見ていきます。マニフェスト全文は gist に置いておきます。
httpd には外部からアクセス可能なサービスが設定されています。これにより、クラスタ内部では httpd.dnscheck.svc.cluster.local で httpd にアクセスできます。
ホスト側の DNS 関連設定はほぼいじっていません
user00@ub20:~$ cat /etc/hostname
ub20
user00@ub20:~$ cat /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity'
network:
ethernets:
enp0s3:
addresses:
- 10.0.2.10/24
gateway4: 10.0.2.1
nameservers:
addresses:
- 10.0.2.6
search:
- example.com
version: 2
user00@ub20:~$ cat /etc/resolv.conf | grep -v '#'
nameserver 127.0.0.53
options edns0
search example.com
user00@ub20:~$
microk8s は dns add-on (CoreDNS) を有効化して参照 (forward) 先を 10.0.2.6 に変更しています。
user00@ub20:~$ microk8s status | head
microk8s is running
high-availability: no
datastore master nodes: 127.0.0.1:19001
datastore standby nodes: none
addons:
enabled:
dns # CoreDNS
ha-cluster # Configure high availability on the current node
disabled:
ambassador # Ambassador API Gateway and Ingress
user00@ub20:~$ kubectl -n kube-system get configmap/coredns -o json | jq .data.Corefile | xargs printf
.:53 {
errors
health {
lameduck 5s
}
ready
log . {
class error
}
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . 10.0.2.6
cache 30
loop
reload
loadbalance
}
user00@ub20:~$
kubectl のコンテキストを dnscheck namespace に変えておきます。
user00@ub20:~$ kubectl config set-context --current --namespace dnscheck
Context "microk8s" modified.
user00@ub20:~$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* microk8s microk8s-cluster admin dnscheck
user00@ub20:~$
発生した事象
元の環境で最初に問題になったのは、Node.js + gRPC なアプリで "DNS resolution failed" になることでした。そして、microk8s を動かしている手元のサーバ等に問題があるのでは、ということで EC2 上の Amazon Linux なインスタンスに microk8s を入れて同じようにセットアップしたところ、そちらでは問題がおきないという状態でした。
[2020-11-06T03:05:02.176] [ERROR] development - Cannot get graph profiles: Error: 14 UNAVAILABLE: DNS resolution failed
at Object.exports.createStatusError (/app/src/node_modules/grpc/src/common.js:91:15)
at Object.onReceiveStatus (/app/src/node_modules/grpc/src/client_interceptors.js:1209:28)
at InterceptingListener._callNext (/app/src/node_modules/grpc/src/client_interceptors.js:568:42)
at InterceptingListener.onReceiveStatus (/app/src/node_modules/grpc/src/client_interceptors.js:618:8)
at callback (/app/src/node_modules/grpc/src/client_interceptors.js:847:24) {
code: 14,
metadata: Metadata { _internal_repr: {}, flags: 0 },
details: 'DNS resolution failed'
}
上図の検証環境でも同様の名前解決できない事象が再現しました。alpine から httpd に wget してみますが "bad address" といわれてしまいます。ためしに ping してみますが同様。
/ # wget httpd.dnscheck.svc.cluster.local
wget: bad address 'httpd.dnscheck.svc.cluster.local'
/ # ping -c3 httpd.dnscheck.svc.cluster.local
ping: bad address 'httpd.dnscheck.svc.cluster.local'
/ #
でも nslookup してみるとちゃんと IP が取れます。
/ # nslookup httpd.dnscheck.svc.cluster.local
Server: 10.152.183.10
Address: 10.152.183.10:53
Name: httpd.dnscheck.svc.cluster.local
Address: 10.152.183.68
/ #
nslookup では名前を引けているのに、wget では名前が引けていないように見えます。
調査
DNS Query の確認
ためしに、alpine コンテナからの通信をキャプチャしてみましょう。microk8s の場合、コンテナからの足が直接ホスト側から見えます。
user00@ub20:~$ kubectl get pods -o json | jq '.items[] | select(.metadata.labels.app=="alpine").status.podIP'
"10.1.90.169"
user00@ub20:~$ ip route | grep 10.1.90.169
10.1.90.169 dev cali7c1dd98133b scope link
user00@ub20:~$
キャプチャしてみます。
user00@ub20:~$ sudo tcpdump -i cali7c1dd98133b
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on cali7c1dd98133b, link-type EN10MB (Ethernet), capture size 262144 bytes
03:21:16.205087 IP 10.1.90.169.50434 > 10.152.183.10.domain: 10660+ A? httpd.dnscheck.svc.cluster.local.dnscheck.svc.cluster.local. (77)
03:21:16.205121 IP 10.1.90.169.50434 > 10.152.183.10.domain: 10892+ AAAA? httpd.dnscheck.svc.cluster.local.dnscheck.svc.cluster.local. (77)
03:21:16.205265 IP 10.152.183.10.domain > 10.1.90.169.50434: 10892 NXDomain*- 0/1/0 (170)
03:21:16.205300 IP 10.152.183.10.domain > 10.1.90.169.50434: 10660 NXDomain*- 0/1/0 (170)
03:21:16.205347 IP 10.1.90.169.56739 > 10.152.183.10.domain: 18816+ A? httpd.dnscheck.svc.cluster.local.svc.cluster.local. (68)
03:21:16.205365 IP 10.1.90.169.56739 > 10.152.183.10.domain: 19001+ AAAA? httpd.dnscheck.svc.cluster.local.svc.cluster.local. (68)
03:21:16.205520 IP 10.152.183.10.domain > 10.1.90.169.56739: 19001 NXDomain*- 0/1/0 (161)
03:21:16.205599 IP 10.152.183.10.domain > 10.1.90.169.56739: 18816 NXDomain*- 0/1/0 (161)
03:21:16.205623 IP 10.1.90.169.49623 > 10.152.183.10.domain: 33123+ A? httpd.dnscheck.svc.cluster.local.cluster.local. (64)
03:21:16.205641 IP 10.1.90.169.49623 > 10.152.183.10.domain: 33300+ AAAA? httpd.dnscheck.svc.cluster.local.cluster.local. (64)
03:21:16.205708 IP 10.152.183.10.domain > 10.1.90.169.49623: 33300 NXDomain*- 0/1/0 (157)
03:21:16.205811 IP 10.152.183.10.domain > 10.1.90.169.49623: 33123 NXDomain*- 0/1/0 (157)
03:21:16.205903 IP 10.1.90.169.42803 > 10.152.183.10.domain: 50654+ A? httpd.dnscheck.svc.cluster.local.example.com. (62)
03:21:16.205939 IP 10.1.90.169.42803 > 10.152.183.10.domain: 50846+ AAAA? httpd.dnscheck.svc.cluster.local.example.com. (62)
03:21:16.206777 IP 10.152.183.10.domain > 10.1.90.169.42803: 50654 0/0/0 (62)
03:21:16.206838 IP 10.152.183.10.domain > 10.1.90.169.42803: 50846 NXDomain 0/0/0 (62)
IPv6 (AAAA) のクエリも混ざってしまっていてちょっとわかりにくいですが、「FQDN で指定しているのにそんなの引く必要あるんだっけ?」という名前を引きにいっています。名前の指定をもうちょっと変えてみます。
/ # wget httpd
Connecting to httpd (10.152.183.68:80)
saving to 'index.html'
index.html 100% |***************************************************************************| 45 0:00:00 ETA
'index.html' saved
/ # rm index.html
/ # wget httpd.dnscheck.svc.cluster.local.
Connecting to httpd.dnscheck.svc.cluster.local. (10.152.183.68:80)
saving to 'index.html'
index.html 100% |***************************************************************************| 45 0:00:00 ETA
'index.html' saved
/ # rm index.html
/ # wget httpd.dnscheck.svc.cluster.local
wget: bad address 'httpd.dnscheck.svc.cluster.local'
/ #
- short name だとちゃんと引ける
- 末尾に dot (root) をつけて厳密な FQDN にすると引ける (ref: インターネット用語1分解説~FQDNとは~ - JPNIC )
想定されるDNS Qeuryと実際の動作の比較
ここで名前の引き方についての話になります。alpine の /etc/resolv.conf を見てみましょう。
/ # cat /etc/resolv.conf
search dnscheck.svc.cluster.local svc.cluster.local cluster.local example.com
nameserver 10.152.183.10
options ndots:5
ということで要約に書いたひとつめの要素: ndots: 5 が出てきます (ref: Man page of RESOLV.CONF )。これは、問い合わせを要求された名前に対して search domain list にあるドメインを追加して (= FQDNにして) 問い合わせるかどうかを決めるために使われています。
- 末尾に dot がある → 厳密な FQDN を与えられたのでそのまま問い合わせる
- 末尾に dot がない & 与えられた名前にある dot の数が ndots 以上→ 与えられた名前を FQDN とみなして問い合わせる
- 末尾に dot がない & 与えられた名前にある dot の数が ndots 未満 → 与えられた名前は FQDN ではないとみなす
- 与えられた名前に search domain を付加して FQDN を作って問い合わせる
- search domain list の全ての domain に対して名前が解決できない場合、与えられた名前を FQDN とみなして問い合わせる
では ndots:5 のときに httpd.dnscheck.svc.cluster.local の問い合わせがどう行われるかを考えてみましょう。
- 末尾に dot がないので厳密な FQDN ではない
- 与えられた名前に含まれる dot の数が 4 (ndots 未満) → 与えられた名前は FQDN ではないので、search domain list にあるドメインを順に追加して問い合わせる
httpd.dnscheck.svc.cluster.local.dnscheck.svc.cluster.local.httpd.dnscheck.svc.cluster.local.svc.cluster.local.httpd.dnscheck.svc.cluster.local.cluster.local.httpd.dnscheck.svc.cluster.local.example.com.
- どれもダメなら与えられた名前を FQDN とみなして問い合わせる
httpd.dnscheck.svc.cluster.local.
Search domain list いずれを追加してもそんなレコードは存在しません。が、これならこれで最後のやつまで引いてくれればよいはずです。ですが、パケットキャプチャしてみると example.com を追加した名前の問い合わせで終わってしまっています。cluster.local は k8s 内部の DNS (CoreDNS) で管理していますが、 example.com はホスト側の search domain に依存するもので、k8s 内部の DNS では管理していません。そのため、k8s 外部の DNS に forward されます。パケットキャプチャを見ると、このときだけ応答が NXDOMAIN ではなく 0/0/0 となっていて他と異なっているのが伺えます。詳細な応答を確認してみます。
NXDOMAIN が返るケース
- k8s 内部のDNSからの応答
user00@ub20:~$ dig @10.0.2.6 httpd.dnscheck.svc.cluster.local.dnscheck.svc.cluster.local. A
; <<>> DiG 9.16.1-Ubuntu <<>> @10.0.2.6 httpd.dnscheck.svc.cluster.local.dnscheck.svc.cluster.local.
; (1 server found)
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 30662
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;httpd.dnscheck.svc.cluster.local.dnscheck.svc.cluster.local. IN A
;; AUTHORITY SECTION:
. 10800 IN SOA a.root-servers.net. nstld.verisign-grs.com. 2020112201 1800 900 604800 86400
;; Query time: 15 msec
;; SERVER: 10.0.2.6#53(10.0.2.6)
;; WHEN: Mon Nov 23 03:31:57 UTC 2020
;; MSG SIZE rcvd: 163
user00@ub20:~$
NOERRROR が返るケース
- k8s 外部に forward されて (外部の dnsmasq から) 返ってきた応答
- このとき NOERROR といいつつ Answer がありません。
user00@ub20:~$ dig @10.0.2.6 httpd.dnscheck.svc.cluster.local.example.com. A
; <<>> DiG 9.16.1-Ubuntu <<>> @10.0.2.6 httpd.dnscheck.svc.cluster.local.example.com. A
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 22407
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;httpd.dnscheck.svc.cluster.local.example.com. IN A
;; Query time: 0 msec
;; SERVER: 10.0.2.6#53(10.0.2.6)
;; WHEN: Mon Nov 23 03:30:04 UTC 2020
;; MSG SIZE rcvd: 73
user00@ub20:~$
これが要約にあげたふたつめ・みつめのポイント : DNSサーバ側の応答とそれに対する musl libc 動作についてです。参照先の資料やリンクは後でまとめてあげますが、それらによると
- DNS は本来、上記の
example.comを付加したようなクエリに対する応答では NXDOMAIN を返さないといけない。 NOERROR なのに Answer がない……問い合わせに対して見つかったと答えているけど答えの中身がない、という状態になってしまっている。これは DNS 実装の問題。1- 今回は DNSサーバとして dnsmasq (のコンテナ) をつかっています。もともとハマった環境は一時的な動作検証用の環境で、変更したり全体の再起動したり、変動の多い環境になっています。
- 今回、この記事のために再現用の環境作ってみたときには、microk8s stop/start (k8s 環境全体の再起動) + dns server の再起動をおこなった際に再現しました。dnsmasq だから常にこの事象が起きるというわけではありませんでした。この辺の dnsmasq の動作はよくわからん……。
- この NOERROR 応答に対して、musl libc は問い合わせを止めてしまうため、名前が引けない (bad address) 状態になってしまう。
- glibc では answer がない場合は次の検索に進む。
- なので、namespace にいるコンテナ (pod) でも、ベースになっているコンテナによって名前が引けるもの・引けないものがいたりする。
結果として、特定の環境・特定のコンテナだけ名前が引けずにエラー、みたいな事象が起きてしまう……。
補足調査
主に "Alpine linux の動作" という観点で話をしてきましたが、musl libc ベースになっているツール全般で可能性のある事象です (alpine が musl libc の busybox を使っている)。ということで、試しに musl libc ベースの busybox コンテナでも試してみたところやっぱり同様の現象がおきます。
/ # hostname
busybox-musl-676459c79f-c8pcv
/ # cat /etc/resolv.conf
search dnscheck.svc.cluster.local svc.cluster.local cluster.local example.com
nameserver 10.152.183.10
options ndots:5
/ # wget httpd.dnscheck.svc.cluster.local
wget: bad address 'httpd.dnscheck.svc.cluster.local'
/ #
そして glibc ベースの busybox コンテナでは問題が起きません……。
/ # hostname
busybox-glibc-856d9d9599-8lmw6
/ # cat /etc/resolv.conf
search dnscheck.svc.cluster.local svc.cluster.local cluster.local example.com
nameserver 10.152.183.10
options ndots:5
/ # wget httpd.dnscheck.svc.cluster.local
Connecting to httpd.dnscheck.svc.cluster.local (10.152.183.68:80)
saving to 'index.html'
index.html 100% |***************************************************************************| 45 0:00:00 ETA
'index.html' saved
/ #
あと、切り分けのために EC2 の上で動かすと問題がおきなかったのはなぜか、という話。EC2 上では ec2.internal がローカルドメインとして付記されているのですが、これを追加した問い合わせに対してちゃんと NXDOMAIN が返ってきていました (なので問題が発覚しなかった)。
実際のあれこれ
- Alpine やその基になっている (musl) buxybox はいろいろなコンテナのベースイメージとして使われています。今回、お仕事中の元事象でも Alpine linux コンテナを直接使っていたわけではなく、それらをベースイメージとして使っている Node.js と TimescaleDB のコンテナでひっかかりました。特に、TimescaleDB それ自身ではなくて、TimescaleDB のコンテナイメージを init container として使っていたところで問題がおきて手間取りました。
- TimescaleDB が起動してから DB につなぐ周辺アプリのコンテナを起動させるために、DB接続するコンテナの pod では TimescaleDB コンテナイメージを使った init container をいれて、DB 接続が確認できることを確認してから本命のコンテナを起動するようにしていました。(こんな感じのやつです → Starting containers in order on Kubernetes with InitContainers | by Xavier Coulon | Medium )
- そのため、kubectl apply した後コンテナ起動させようとするものの init container のなかで名前解決ができず、DB接続するコンテナが全部 init のまま動かなくなっていました。これは表面的な現象だけ見ていると、TimescaleDB それ自身の Pod は起動するのに DB に接続しにいく周辺アプリの pod (python; debian base のコンテナを使っていた) がなぜか init から先に進まない、みたいに見えます。init container とその中身の動きまで把握できないと先に進めません。
- このあたりは GitHub - derailed/k9s がないと動作を追いきれなかったですね。
- 最終的には、DNS Query の動作がおかしいこと、Node.js/TimescaleDB のコンテナイメージを使う Alpine ベースのコンテナでだけ問題が起きること、というのがとっかかりになりました。
- パケットキャプチャなんかも、microk8s だから上に書いたようなとり方ができているので、問題発生も解決も環境依存な要因が大きいです。
Workaround
ndots: 1 に設定します 2。これは、指定したホスト名にひとつでも dot が含まれていれば FQDN とみなしてそのまま問い合わせる、という設定です。(内部ドメインの検索は dot の含まれていない short name に対してだけ実施する。)
Pod の DNS の設定は以下のように dnsConfig で指定します。(ref: ServiceとPodに対するDNS | Kubernetes )
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: alpine
namespace: dnscheck
spec:
replicas: 1
selector:
matchLabels:
app: alpine
template:
metadata:
labels:
app: alpine
spec:
containers:
- image: alpine:3.12.1
name: alpine
tty: true
dnsConfig:
options:
- name: ndots
value: "1"
こうなります。
/ # hostname
alpine-65c89894f7-ffrh2
/ # cat /etc/resolv.conf
search dnscheck.svc.cluster.local svc.cluster.local cluster.local example.com
nameserver 10.152.183.10
options ndots:1
/ #
まとめ
こうした動作は環境が変わったタイミングで発覚します。今回は EKS 上 → ローカル環境 (オンプレ/microk8s) へ変えた際に発覚しましたが、たとえば CI/CD をするときに、普段動かしているところとは別なプラットフォームでコンテナデプロイをしたらその中でだけ動かない、みたいなことが予想されます。環境を変えたら特定のモノが動かなくなった…みたいなケースは厄介で、システムがある程度動いていると、ベースイメージが何かなんてほぼ気にしていないし、init container なんかも最初だけなのであまり動作を把握できていなかったりするんですよね。普段意識してないところで引っかかるので対処しにくい……。
余談ですが、今回取り上げた事例の他にも、k8s 使っていて DNS 周りのトラブルがいくつかありました。DNSの鬼門感すごいですね! (他の構成要素と連携する際の起点に全部 DNS がはいってくるからってだけなんだけど。) そのあたりは気が向いたら別途書くかもしれません。
参考
-
UnknownHostException caused by DNS Resolution issue with Alpine Images – CloudBees Support
- 本記事と同等の内容…というかここの内容を見て上のような調査をしていました。
-
musl libc - Functional differences from glibc
- glibc / musl libc の違いをまとめてある記事。
-
Karan Sharma | DNS Lookups in Kubernetes
- 同様の事象についての解説
-
Kubernetes pods /etc/resolv.conf ndots:5 option and why it may negatively affect your application performances
- DNSクエリの動作と k8s 上で ndots 設定を変更することのパフォーマンス影響についての解説
-
Kube-dns add-on should accept option ndots for SkyDNS or document ConfigMap alternative subPath · Issue #33554 · kubernetes/kubernetes
- k8s ではなぜ
ndots: 5がデフォルトなのか
- k8s ではなぜ
-
ndots breaks DNS resolving · Issue #64924 · kubernetes/kubernetes
- musl dns client stop further search domain when one search domain return something unexpected. (#9017) · Issues · alpine / aports · GitLab
- musl - Re: [PATCH] resolver: only exit the search path loop there are a positive number of results given
- alpine, musl libc でこのあたりの問題の報告はされているようですが、結局 DNS サーバ側の動作がおかしいわけで、それに合わせてライブラリ側の動作を修正してもほかのトラブルをひきおこす恐れがある、ってなってる気配です (ちゃんと読んでない)
-
Amazon EKS での DNS 障害のトラブルシューティング, "検索と ndots の組み合わせ" のところ参照。"注: NXDOMAIN はドメインレコードが見つからなかったことを意味し、NOERROR はドメインレコードが見つかったことを意味します。" ↩
-
今回ターゲットにしているシステムが単一の namespace 内の構成要素で動作が完結する作りなのと、(広義の/末尾 dot のない) FQDN でサービス名を指定するルールになっていたのでこれでよいかなというところです。複数の namespace をまたぐような問い合わせ (cross-namespace) が必要なシステムでは、ndots は 2 (以上) とするほうが良いかもしれません。ref: Kube-dns add-on should accept option ndots for SkyDNS or document ConfigMap alternative subPath · Issue #33554 · kubernetes/kubernetes ↩