この記事は NTTコムウェア Advent Calendar 2024 18日目の記事です。
目次
- はじめに
- RAG精度向上のコンペ参加
- RAG1グランプリ概要
-
RAG精度向上のために用いた技術
- 4.1 GraphRAG
- 4.2 RAG Fusion
- システム全体構成図
- システム1(小説のタイトル検索)の前処理
- システム1(小説のタイトル検索)のRetrieve
- システム2(小説の内容検索)の前処理
- システム2(小説の内容検索)のRetrieve
- システム2(小説の内容検索)のAugment
- システム2(小説の内容検索)のGenerate
- 他のアプローチ
- RAG Fusion
- GraphRAG vs RAG Fusion
- 成績および表彰式
- 難問の解説
- 最後に
1.はじめに
こんにちは。NTTコムウェアの鈴木 崇史と申します。よろしくお願いします。
私は長くNTT PCコミュニケーションズやNTTコミュニケーションズに所属してISPのネットワークエンジニアでしたが、2020年のコロナ禍ぐらいから徐々にトラフィック分析などデータ分析業務が増えてきた流れで社内のスキルアップ支援もあり、リスキリング1しました。結果的にキャリアパスをデータサイエンティストに変更したことで、現在の業務は、NTTコムウェアにて、生成AI・大規模言語モデル(LLM)を活用するためのエンジニアとして、主に、生成AIに関連する技術(RAG精度向上、ハルシネーション抑止手法、マルチAgentフレームワーク開発など)の技術調査、POC検証、案件提案支援などの業務に取り組んでおります。
2.RAG精度向上のコンペ参加
今回は、全くの個人参加(自分の技術力の確認目的)で、2024/09/12~2024/10/10の期間にSIGNATEで開催されたRAG-1グランプリのコンペティションに参加しています。コンペ終了前に、「自身の最上位の成績を選ばない」というミスをしてしまいましたが、それでも9位と、みごと金賞![]() を受賞しました。
を受賞しました。
本コンペの開催主旨である「知見を共有しよう」という主旨に則り、全て詳しくRAGの精度向上の勘所やポイントがわかるように解説してみます。私からの![]() クリスマスプレゼント
クリスマスプレゼント![]() として、どなたかの参考になれば幸いです。
として、どなたかの参考になれば幸いです。
また、全くの個人参加ですので、私物の古いMacbookPro(2020 Intel Corei7)1台だけのローカル開発環境で行っています。
2.1 対象読者
・OpenAI API、RAG、Pythonについての基礎知識があれば尚よいですが、なるべく少しでもRAGに興味がある人にも、なるべく読みやすい工夫をしてみました。
つまり実装のコードはなるべく展開型にして、コードまでは興味ない方は展開しなくても読み進められるようにしています。
3.RAG1グランプリ概要
目的:生成AI、大規模言語モデル(LLM)の課題の1つである「ハルシネーション」抑止の解決策として注目されているRAG技術はビジネス面に於いても注目度が高いですが、黎明期ゆえに、まだ多くの企業がRAG構築・精度向上に苦労している背景があります。本コンペは、RAGシステムを構築し、精度向上を競うことに加え、技術の可能性を探求するとともに、知見を共有する目的で参加を呼び掛けておりました。
課題:
- 著作権が切れた小説データ(7つ)を使用し、RAGシステムの構築を行う。
- 提供された小説データを元に、事務局から提示された質問(全60問)に対する回答を生成し、指定フォーマットで提出
- その回答精度を競う
入賞条件
- 本コンペティションが、RAGの具体的な実装手法に関する知見を得て、共有することを目的として開催しているため、入賞者の上位20名にはRAGの具体的な実装に関するレポートの提出が義務付けされていました。不正対策ですね
今回の課題にフォーカスしたRAGシステムの構築イメージ
-

- 画像出展 : SIGNATE RAG1グランプリ 概要
4.RAG精度向上のために用いた技術
主に私が利用したRAG精度向上技術は以下2つですので、こちらを中心に解説します。
- GraphRAG(KnowledgeGraphを用いたRAG)
- RAG Fusion
そのほかにも、chunking,documentにmetadata付与なども実施していますが、主なものをあげさせて頂きました。RAGの精度向上を体系的に他にどんなものがあるのか知りたいという方は、llamaidex の Andrei氏の A Cheat Sheet and Some Recipes For Building Advanced RAGが役に立ちます。また日本語で解説してくれている株式会社ナレッジセンスの門脇氏によるRAGでの回答精度向上のためのテクニック集(応用編-B)や、RAGとは?回答精度向上のためのテクニック集(基礎編)もとても参考になると思います。
4.1 GraphRAG
4.1.1 VectorDB と GraphDB の違い
RAGを使ってLLMに知識を与えるには、ベクトルデータベース(VectorDB)が一般的です。これは、データの特徴量をベクトルによる数値表現に変換させ、それをベクトル空間という広大なDB空間に放り込むイメージです。類似したデータは、距離的に近い場所に配置されて整理されています。これによって、検索文(クエリベクトル)に類似したドキュメントをすばやく特定できます。
一方、グラフデータベース(GraphDB)は、ベクトルDBとはアプローチが異なり
グラフ構造で、データを整理して格納します。文書内に含まれるエンティティ(例:人、動物、物、場所、出来事など)はグラフ上のノードで表され、関係をエッジと呼ばれる線でつなぎその構造化していきます。ゆえに、人と事象や物事に対する関係性の把握が容易になります。
下図は、それぞれのDBを違いのイメージ化したものです。
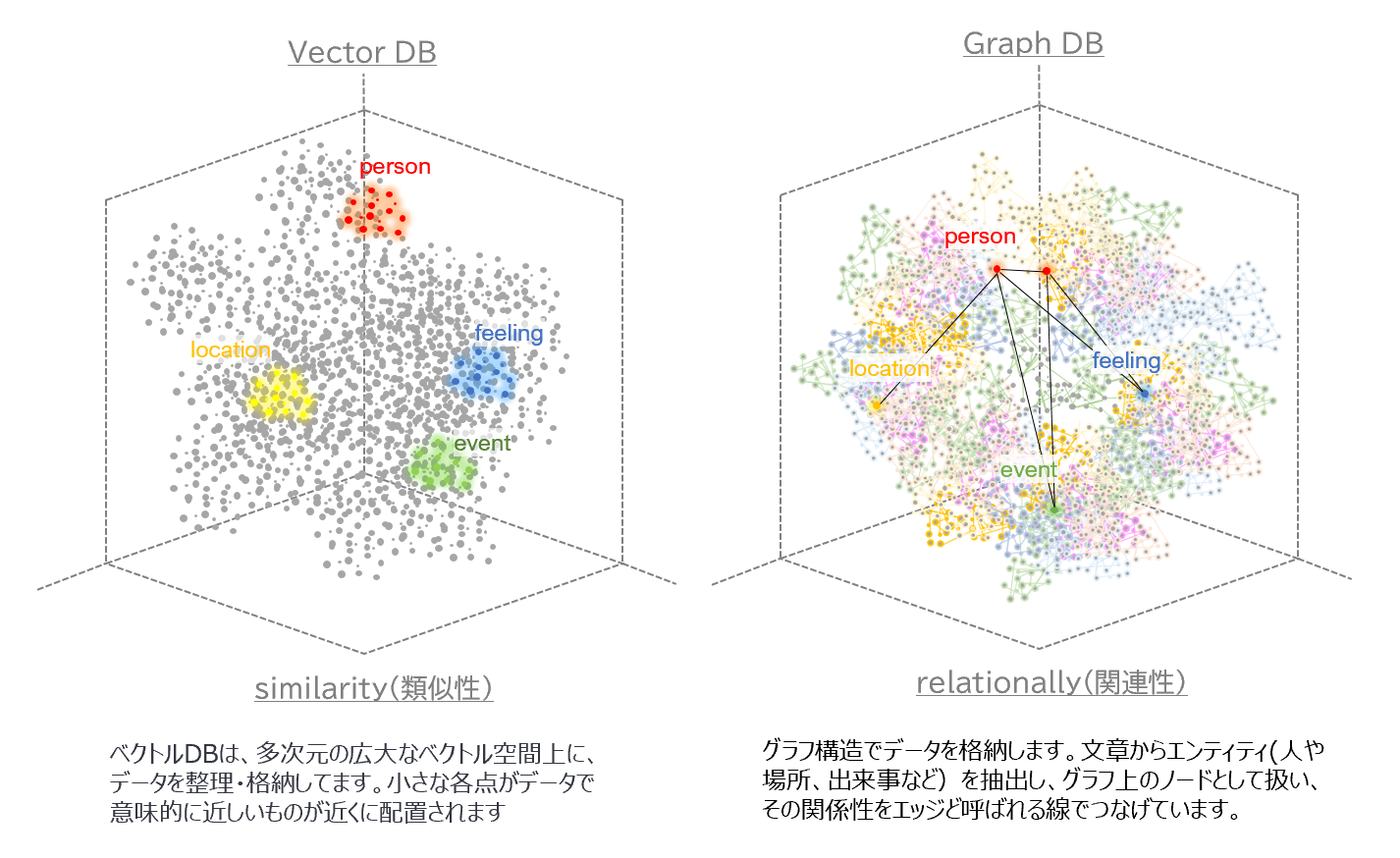
ドキュメント(非構造化データ)からグラフ構造(構造化データ)を抽出するイメージ

4.1.2 前処理の違い
- それぞれのDBに格納する前の前処理も異なります。VectorDBでは、主に文章をチャンク化(分割化)した後に、ベクトル変換して数値化してから格納します。文書単位でベクトル化すれば文書の類似性に基づき場所がきまり、単語単位でベクトル化して格納すれば、その単語の類似性で近しい場所に格納されます。一方、GraphDBでは、文章をチャンク化(分割化)した後に、その文章内にある、エンティティを抽出し、そのエンティティ間の関係性をグラフドキュメント化して、グラフDBに格納します
- 下図は、同じ「AさんとBさんは横浜で結婚式を挙げて幸せだ」という文書に対して、それぞれ前処理を施した後に、DBに格納させる違いをイメージした図です。左側がVectorDB、右側がGraphDBです。GraphDBは、ノードにエンティティだけでなく、ドキュメントそのものや、それからチャンク化(細分化)された文書の断片も1つのノードとして登録することができます。さらにそのチャンクから、文書内に登場する人物や出来事を、関係性で紐づけて登録されます
-

4.1.3 今回採用したグラフDB
GraphDBには、Neo4jやAmazon Nepture, ArangoDBなどがありますが、今回は最もメジャーなオープンソースのグラフデータベースであるNeo4jを利用しています。無料で試す場合は、AuraDBの無料プランもしくは、ローカルPCにDesktop版をインストールしてセットアップが必要になります。今回は後者を選んでいますが、セットアップの詳細は割愛します。また、Neo4jの検索操作は、グラフデータベースため、問合せ言語がSQLではなく、Cypherと言われる独自クエリ言語で操作するのが特徴です。
4.1.4 グラフドキュメント化の手法
- GraphDBを構築する為に、グラフドキュメント化する必要性があるわけですが、手法としては、
- 1.手動でCypherコマンドを用い、CLIで直接DBに入れる方法
CREATE (:Person { name: 'Aさん' })-[:MARRIED { day:'2024-12-18' } ]->(:Person { name : 'Bさん'})
- 2.トリプレットによる抽出
- トリプレットとは、「主語, 述語, 目的語」の組合せで取る形式のこと
- 参考 : LangChain NetworkX によるTriplet抽出
- 3.LangChainを用いたグラフドキュメントの抽出
- 3.1 情報抽出パイプラインを構築して丁寧にドキュメントから抽出する方法
- 3.2 LLMGraphTransformerを使ってドキュメントから抽出する方法
- 4.Microsoft GraphRAGを使う方法
- 1.手動でCypherコマンドを用い、CLIで直接DBに入れる方法
などがあります。
参考 手法1 Cypherコマンド例
CREATE (:Person { name: 'Aさん' })-[:MARRIED { day:'2024-12-18' } ]->(:Person { name : 'Bさん'})
4.1.5 グラフDB(Neo4j)での可視化
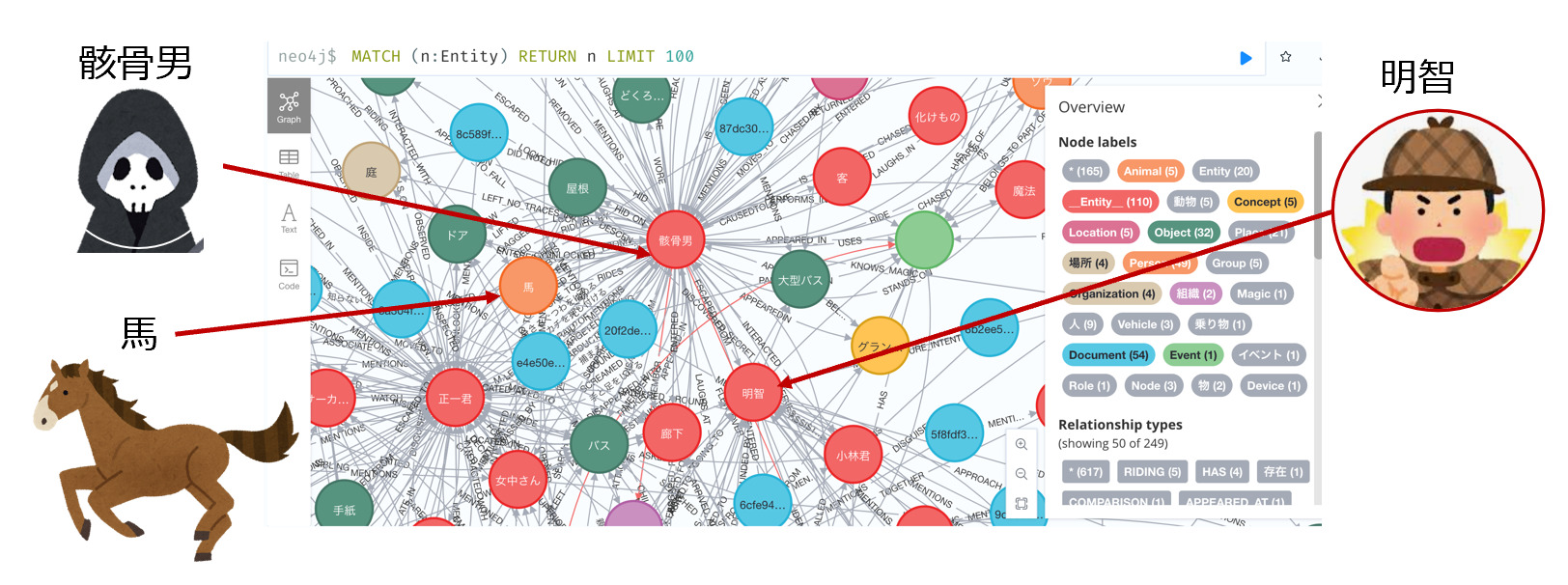
- 下図は、今回の出題対象の小説ではありませんが、私が短編小説をグラフDBで可視化した例です。題材は、ナレッジグラフ推論チャレンジ2の2018年課題であった、シャーロックホームズの短編小説(まだらのひも)を用いました。これをMicrosoftGraphを使うことで、エンティティやノードの関係性、Leidenというクラスタリング手法で抽出することができます。さらに、それをNeo4jというグラフDBに投入して可視化させています
- グラフDB可視化例:シャーロックホームズ短編小説:まだらのひも3

- わかりやすくするため、私の方で登場人物などを画像に加筆してます
- これを見ると、ドキュメントを1つのノードとして、そこからChunkされたドキュメントのノードが生まれ、さらに各チャンクドキュメントから、エンティティを抽出し、そのエンティティが事件(イベント)と、場所と、密接かつ複雑に絡み合っている様子がうかがえます。またホームズは図の上の方に配置させてみましたが、様々なエンティティにリレーションの足が伸びているのがうかがえます。また、ホームズというノードのプロパティに、descriptionを加え、さらにそのテキストデータをembeddingさせるという、VectorDBとGraphDBを共存させるような手法がとれるとわかります
4.1.5 なぜGraphRAGなのか
- 初手としてよく使う従来のVectorRAG(NaiveRAG)には課題があり、意味的に近いチャンク化されたテキストが検索にヒットし、その付近に知りたい情報が入っていないとダメ。という構造上の課題4があります。一方、GraphDBは、データ関連性による高い検索能力や、グラフ構造に基づく文脈を考慮した回答を実現できるのがポイントです
4.2 RAG Fusion
もう一つのポイントとして紹介したい技術は、RAG Fusion5です。
4.2.1 RAG Fusionとは
RAG-Fusion は、従来の検索と人間が入力するクエリとのギャップを埋めることを目的とした検索手法です。俗っぽく簡単に言えば、「ググる力を、LLMで補ってあげよう」ということです。入力した検索文をベースに複数のクエリをLLMが生成します。さらにそれらを相互スコアで再ランク付けし、ドキュメントとスコアを融合することで、RAG と相互ランク融合 (RRF) を組み合わせて結果を出します。複数のクエリ生成とRRF 相互ランク融合を使用して検索結果を再ランク付けするところが強みです。LangChainを使った実装は注釈を参照してください5
- LangChainのRAG Fusionのプロセス図6に、青文字で加筆したもの

出典:LangChain Query Transformations
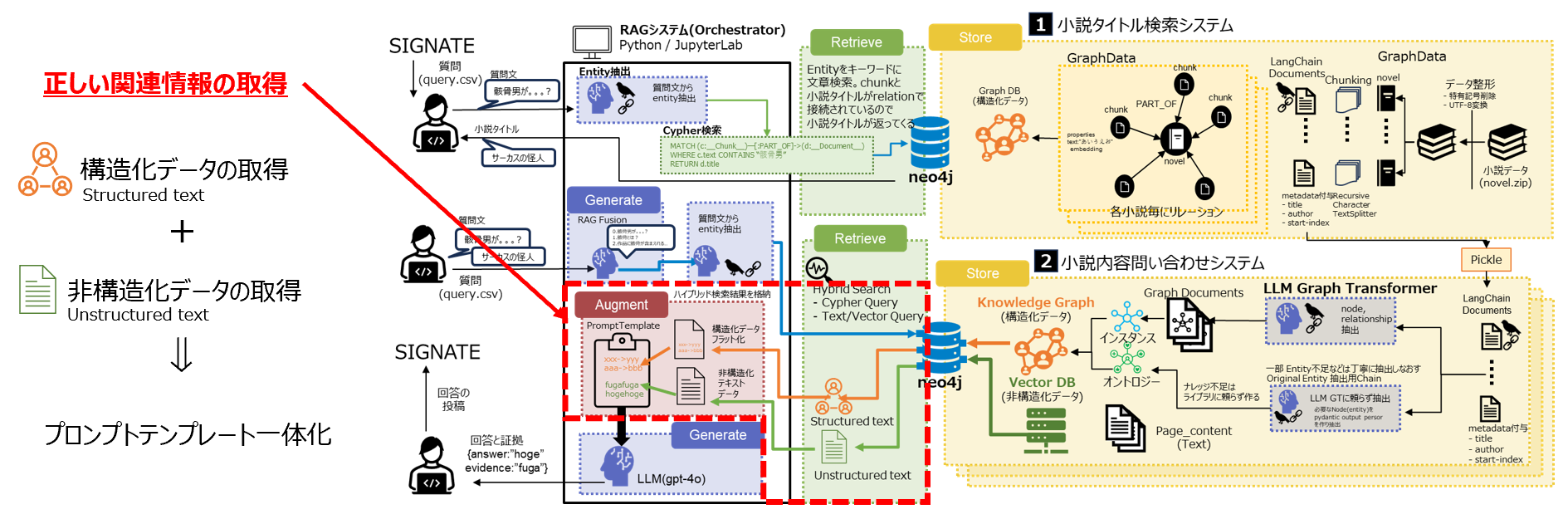
5.システム全体構成図
-
今回私が構築したシステムの全体構成図です

-
大きく2つに分かれています
- 【1】小説タイトル検索システム
- そもそも60問の質問がどの小説に対する質問かを的確に判断させる仕組み。図書館における司書のような役割
- 【2】小説内容問合せシステム
- 【1】のシステムの後続処理として、小説の詳細な中身について答える仕組み
- 【1】小説タイトル検索システム
-
利用したモデル等は以下です
- llm:gpt-4o(OpenAI)
- emedding: text-embedding-ada-002
- vector_db: neo4j desktop for mac(5.23.0)
- plugins:APOC(Compatible vesion:5.20.0)
- plugins:Graph Data Science library(2.9.0)
- Orchestrator: LangChain(0.2.12)
- Macbook Pro (2020 2.3GHz Intel Corei7 memory 16GB) x1
-
事前の環境準備
- openaiのapi key取得
- neo4j desktop for macのインストール、pluginsのインストール
- langchainのインストール
- 上記の環境準備の話は省略します
6.システム1(小説のタイトル検索)の前処理
前処理もシステムが2つあるので、それぞれ分けて説明します。

6.1 システム1の前処理(1) 青空文庫特有の文章を直す
基本的に、ここの前処理は、Qiita Pythonで青空文庫データを自然言語処理向けにさくっと一括テキスト整形+前処理を有難く参照させて頂き、変換関数は、そのままにコードを処理してます。

青空文庫の前処理コード
# TargetFile
target_file1 = "./dataset/novels/1.txt"
target_file2 = "./dataset/novels/2.txt"
target_file3 = "./dataset/novels/3.txt"
target_file4 = "./dataset/novels/4.txt"
target_file5 = "./dataset/novels/5.txt"
target_file6 = "./dataset/novels/6.txt"
target_file7 = "./dataset/novels/7.txt"
import pandas as pd
#read_csv
df_tmp1 = pd.read_csv(target_file1, encoding='cp932', names=['text'])
df_tmp2 = pd.read_csv(target_file2, encoding='cp932', names=['text'])
df_tmp3 = pd.read_csv(target_file3, encoding='cp932', names=['text'])
df_tmp4 = pd.read_csv(target_file4, encoding='cp932', names=['text'])
df_tmp5 = pd.read_csv(target_file5, encoding='cp932', names=['text'])
df_tmp6 = pd.read_csv(target_file6, encoding='cp932', names=['text'])
df_tmp7 = pd.read_csv(target_file7, encoding='cp932', names=['text'])
#Output
df_tmp1.to_csv("./dataset/novels_utf8/tsv/novel1.tsv", sep='\t', encoding='utf-8', index=None)
df_tmp2.to_csv("./dataset/novels_utf8/tsv/novel2.tsv", sep='\t', encoding='utf-8', index=None)
df_tmp3.to_csv("./dataset/novels_utf8/tsv/novel3.tsv", sep='\t', encoding='utf-8', index=None)
df_tmp4.to_csv("./dataset/novels_utf8/tsv/novel4.tsv", sep='\t', encoding='utf-8', index=None)
df_tmp5.to_csv("./dataset/novels_utf8/tsv/novel5.tsv", sep='\t', encoding='utf-8', index=None)
df_tmp6.to_csv("./dataset/novels_utf8/tsv/novel6.tsv", sep='\t', encoding='utf-8', index=None)
df_tmp7.to_csv("./dataset/novels_utf8/tsv/novel7.tsv", sep='\t', encoding='utf-8', index=None)
#確認(title)
#print(df_tmp1['text'][0])
#print(df_tmp2['text'][0])
#print(df_tmp3['text'][0])
#print(df_tmp4['text'][0])
#print(df_tmp5['text'][0])
#print(df_tmp6['text'][0])
#print(df_tmp7['text'][0])
#整形コード
def text_cleanse_df(df):
# 本文の先頭を探す('---…'区切りの直後から本文が始まる前提)
head_tx = list(df[df['text'].str.contains(
'-------------------------------------------------------')].index)
# 本文の末尾を探す('底本:'の直前に本文が終わる前提)
atx = list(df[df['text'].str.contains('底本:')].index)
if head_tx == []:
# もし'---…'区切りが無い場合は、作家名の直後に本文が始まる前提
head_tx = list(df[df['text'].str.contains(author_name)].index)
head_tx_num = head_tx[0]+1
else:
# 2個目の'---…'区切り直後から本文が始まる
head_tx_num = head_tx[1]+1
df_e = df[head_tx_num:atx[0]]
# 青空文庫の書式削除
df_e = df_e.replace({'text': {'《.*?》': ''}}, regex=True)
df_e = df_e.replace({'text': {'[.*?]': ''}}, regex=True)
df_e = df_e.replace({'text': {'|': ''}}, regex=True)
# 字下げ(行頭の全角スペース)を削除
df_e = df_e.replace({'text': {' ': ''}}, regex=True)
# 節区切りを削除
df_e = df_e.replace({'text': {'^.$': ''}}, regex=True)
df_e = df_e.replace({'text': {'^―――.*$': ''}}, regex=True)
df_e = df_e.replace({'text': {'^***.*$': ''}}, regex=True)
df_e = df_e.replace({'text': {'^×××.*$': ''}}, regex=True)
# 記号、および記号削除によって残ったカッコを削除
df_e = df_e.replace({'text': {'―': ''}}, regex=True)
df_e = df_e.replace({'text': {'…': ''}}, regex=True)
df_e = df_e.replace({'text': {'※': ''}}, regex=True)
df_e = df_e.replace({'text': {'「」': ''}}, regex=True)
# 一文字以下で構成されている行を削除
df_e['length'] = df_e['text'].map(lambda x: len(x))
df_e = df_e[df_e['length'] > 1]
# インデックスがずれるので振りなおす
df_e = df_e.reset_index().drop(['index'], axis=1)
# 空白行を削除する(念のため)
df_e = df_e[~(df_e['text'] == '')]
# インデックスがずれるので振り直し、文字の長さの列を削除する
df_e = df_e.reset_index().drop(['index', 'length'], axis=1)
return df_e
#テキスト整形
df_tmp_e1 = text_cleanse_df(df_tmp1)
df_tmp_e2 = text_cleanse_df(df_tmp2)
df_tmp_e3 = text_cleanse_df(df_tmp3)
df_tmp_e4 = text_cleanse_df(df_tmp4)
df_tmp_e5 = text_cleanse_df(df_tmp5)
df_tmp_e6 = text_cleanse_df(df_tmp6)
df_tmp_e7 = text_cleanse_df(df_tmp7)
#OUTPUT
df_tmp_e1.to_csv("./dataset/novels_utf8/novel1.txt", sep='\t', encoding='utf-8', index=None, header=False)
df_tmp_e2.to_csv("./dataset/novels_utf8/novel2.txt", sep='\t', encoding='utf-8', index=None, header=False)
df_tmp_e3.to_csv("./dataset/novels_utf8/novel3.txt", sep='\t', encoding='utf-8', index=None, header=False)
df_tmp_e4.to_csv("./dataset/novels_utf8/novel4.txt", sep='\t', encoding='utf-8', index=None, header=False)
df_tmp_e5.to_csv("./dataset/novels_utf8/novel5.txt", sep='\t', encoding='utf-8', index=None, header=False)
df_tmp_e6.to_csv("./dataset/novels_utf8/novel6.txt", sep='\t', encoding='utf-8', index=None, header=False)
df_tmp_e7.to_csv("./dataset/novels_utf8/novel7.txt", sep='\t', encoding='utf-8', index=None, header=False)
6.2 システム1の前処理(2)
Loading,Chunkingを実施しています。工夫点は、Recursive Character TextSplitterを使った点と、metadataに色々と情報を付加している点です。またせっかく作ったので、一旦、貯蔵庫に保存(pickle)しています。
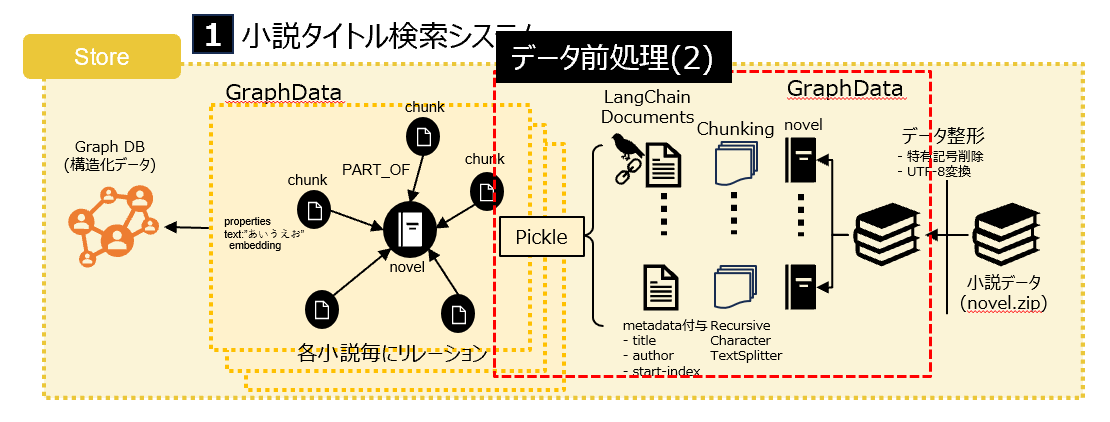
Loading,Chunking,metadata付与してpickleで保存するの前処理のコード
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
import pickle
for i, read_txt in enumerate(source_texts):
textloader_ = TextLoader(read_text)
raw_documents_ = textloader_.load()
# Modify the metadata
for document in raw_documetns_:
document.metadata['title']=title[i]
document.metadata['author']=authors[i]
# metadata.documents 確認
print("----")
print("metadata:", raw_documents_[0].metadata)
print("page_content[:100] :\n",raw_documents_[0].page_content[:100])
# Chunking
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, #チャンクの最大文字数
chunk_overlap = 24, #チャンクの間の重複する文字数
add_start_index=True, # これを入れると何文字目のスタートかがmetadataに入る
separators=["\n\n", "\n", ".", " ",""], #チャンクの区切りテキスト
)
documents_output = text_splitter.split_documents(raw_documents_)
#チャンク分割数確認
print(f"chunking_result::: len(documents_output): {len(documents_output)}")
#保存
output_pkl_name = output_pkl[i]
with open(output_pkl_name, "wb") as f:
pickle.dump(douments_output, f)
print(f"Saved to {output_pkl_name} .")
titles = ["流行暗殺節","不如帰","カインの末裔","競漕","芽生","サーカスの怪人","死生に関するいくつかの断想"]
authers = ["佐々木味津三","徳冨蘆花","有島武郎","久米正雄","島崎藤村","江戸川乱歩","小泉八雲"]
#ファイル名はnovel1.txtだとパット見わからないのでタイトルも付けるように変更してます
source_texts = ["./dataset/novels_fin/novel1_流行暗殺節.txt","./dataset/novels_fin/novel2_不如帰.txt",
"./dataset/novels_fin/novel3_カインの末裔.txt","./dataset/novels_fin/novel4_競漕.txt",
"./dataset/novels_fin/novel5_芽生.txt","./dataset/novels_fin/novel6_サーカスの怪人.txt",
"./dataset/novels_fin/novel7_死生に関するいくつかの断想.txt",]
output_pkl = ["./dataset/docs/documents1.pkl","./dataset/docs/documents2.pkl",
"./dataset/docs/documents3.pkl","./dataset/docs/documents4.pkl","./dataset/docs/documents5.pkl","./dataset/docs/documents6.pkl","./dataset/docs/documents7.pkl"]
#読み出し
ouput_pkl_dict={"流行暗殺節":output_pkl[0]},
"不如帰":output_pkl[1]},
"カインの末裔":output_pkl[2]},
"競漕":output_pkl[3]},
"芽生":output_pkl[4]},
"サーカスの怪人":output_pkl[5]},
"死生に関するいくつかの断想":output_pkl[6]}
}
#どのタイトルを読みだすか番号で指定
#死生に関するいくつかの断想の場合、6を指定
title_name = titles[6]
print(title_name)
output_pkl_path= output_pkl_dict(title_name)
print(output_pkl_path)
with open(output_pkl_path, "rb") as f:
doc = pickle.load(f)
print("read_to:", doc[0])
pickleで保存したものを取り出すコード
#保存してある書庫(pickle)から取り出す処理
#タイトル一覧を表示
print("ドキュメントを選んで下さい")
for i, title in enumerate(titles):
print(f"{i}: {title}")
#input関数でドキュメント番号を指定
document_number = int(input("ドキュメント番号を入力して下さい(0~6):")
#有効な番号か確認
if 0 <= document_number < len(titles):
# ドキュメント名を取得
title_name = titels(document_number)
print("title_name:", title_name)
#読み出し
output_pkl_path = output_pkl_dict(title_name)
print("output_pkl_path:", output_pkl_path)
print("\n\nfile open...")
#指定されたドキュメントを読み込み、保存
with open(output_pkl_path, "rb") as f:
documents = pickle.load(f)
#動的に変数名を作成して保存
locals()[f"documents_{document_number+1}"] = documents
#結果を確認
print(f"documents_{document_number + 1}[0]: \n", locals()[f'documents_{document_number + 1 }'][0])
else:
print("無効なドキュメント番号です。")
ドキュメントを選んでください。
0:流行暗殺節
1:不如帰
2:カインの末裔
3:競漕
4:芽生
5:サーカスの怪人
6:死生に関するいくつかの断想
ドキュメント番号を入力してください(0~6):6
title_name:死生に関するいくつかの断想
output_pkl_path: ./dataset/docs/documents7.pkl
6.3 システム1の前処理(3)
DataFrameに変換してNeo4jにバッチ処理で登録する準備をする
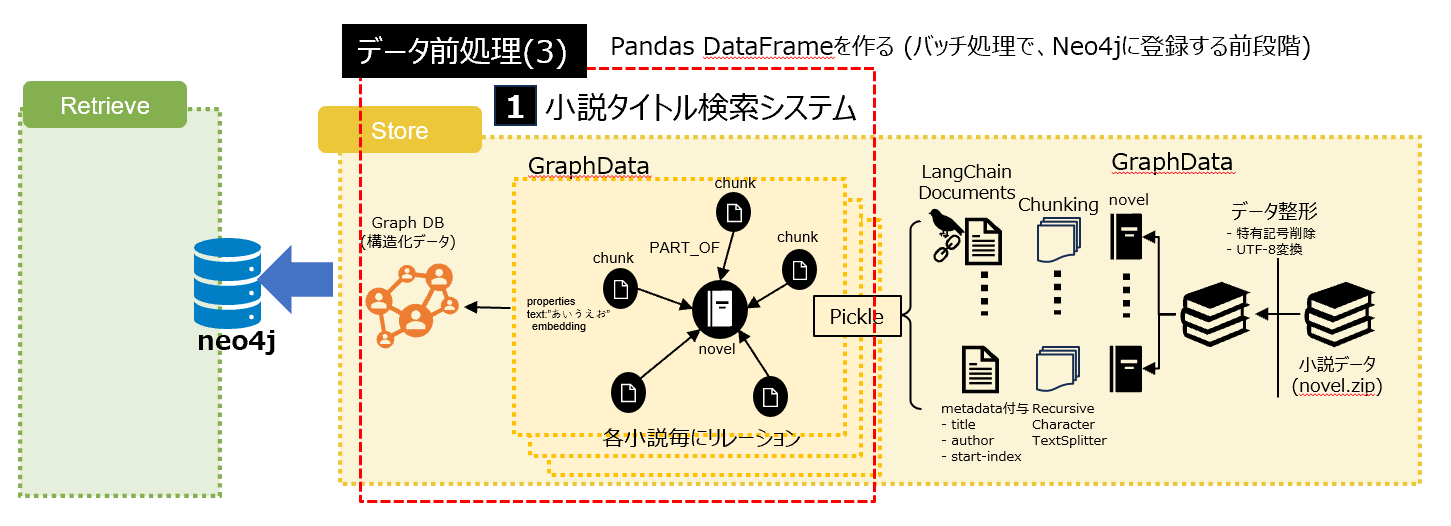
6.3.1 ChunkデータからDataFrameを作る
ChunkドキュメントをDF化するコード
import pandas as pd
df doc2df(documents):
#Documentオブジェクトのリストからデータを取り出してDFに格納
data= {
'text':[], #page_content
'title':[],
'author':[],
'start_index':[],
'source':[]
}
# DataFrameに格納
for doc in documents:
data['text'].append(doc.page_content)
data['title'].append(doc.metadata.get('title'))
data['author'].append(doc.metadata.get('author'))
data['start_index'].append(doc.metadata.)get('start_index'))
data['source'].append(doc.metadata.get('source'))
df = pd.DataFrame(data)
return df
#実行例
df7 = doc2df(documents_7)
df7
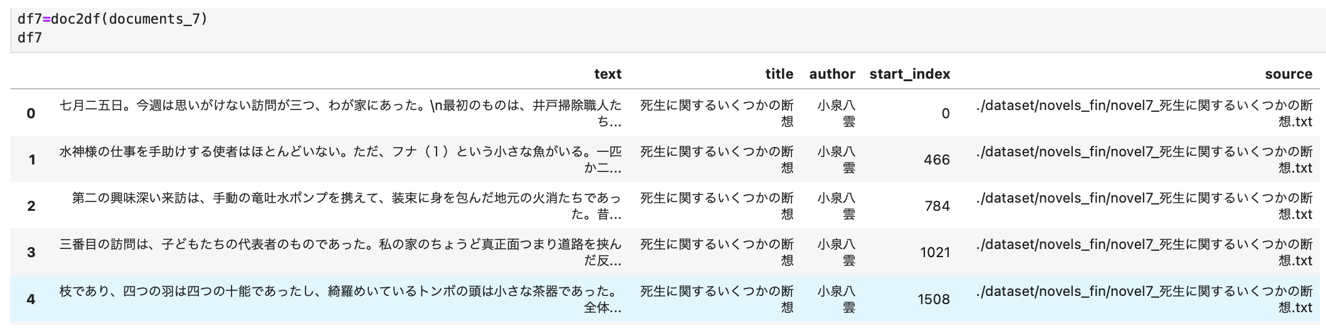
df7['id'] = [str(uuid.uuid4()) for _ in range(len(df7)]
df7

また、ドキュメント自身も1つのノードとして登録するために
ids=[1,2,3,4,5,6,7]
titles = ["流行暗殺節","不如帰","カインの末裔","競漕","芽生","サーカスの怪人","死生に関するいくつかの断想"]
doc_df = pd.DataFrame({"id":ids,"title":titles})

6.4 システム1の前処理(4)
ノードとして登録したいDataFrameが出来たので、これをNeo4jに登録していきます。

Neo4jにバッチ処理で入れるコード
# Neo4jにバッチ処理で登録
import pandas as pd
from neo4j import GraphDatabase
import time
NEO4J_URI="bolt://localhost:7687"
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = "your password" #自分で決めたパスワード
NEO4J_DATABASE = "neo4j" #DBMS Name
driver = GraphDatabase.driver(NEO4J_URI,auth=(NEO4J_USERNAME, NEO4J_PASSWORD))
def batched_import(statement, df, batch_size=1000):
"""
バッチ方式を使用してデータフレームをNeo4jにインポート
パラメータ:statementは実行する Cyperクエリ。dfはインポートするDF。bacth_sizeは各バッチでインポートする行数
"""
total = len(df)
start_s = time.time()
for start in range(0, total, batch_size):
batch = df.iloc(start:min(start+batch_size,total))
result = driver.exeute_query("UNWIND $rows AS value " + statement,
rows=batch.to_dict('records')
database_=NEO4J_DATABASE)
print(result.summary.conters)
print(f'{total} rows in { time.time() - start_s} s.'
return total
#制約の作成、冪等操作
statements = """
create constraint chunk_id if not exists for (c:__Chunk__) require c.id is unique;
create constraint document_id if not exists for (d:__Document__) require d.id is unique;
create constraint entity_id if not exists for (c:__Community__) require c.community is unique;
create constraint entity_id if not exists for (e:__Entity__) require e.id is unique;
create constraint entity_title if not exists for (e:__Entity__) require e.name is unique;
create constraint entity_title if not exists for (e:__Covariate__) require e.title is unique;
create constraint related_id if not exists for ()-[rel:RELATED]->() require rel.id is unique;
""".split(";")
for statement in statements:
if len((statement or "").strip()) > 0:
print(statement)
driver.execute_query(statement)
1.Documentsを7小説分入れる
# Neo4jにドキュメントをインポートさせる
# 1.Documentを入れる
statement = """
MERGE (d:__Document__ {id:value.id})
SET d += value {.title}
"""
#投入
batched_import(statement, doc_df)
{'_contains_updates': True, 'labels_add':7, 'nodes_created':7, 'properties_set':14}
7 rows in 0.4687511920928955 s.
7
2.チャンク分割したデータをNeo4jに入れる
# 2.Chunk分割したデータを入れる
statement = """
MERGE (c:__Chunk__ {id:value.id})
SET c += value {.text, .title, .author, .start_index, .source}
WITH c, value
UNWIND value.document_ids AS document
MATCH (d:__Document__ {id:document})
MERGE (c)-[:PART_OF]->(d)
"""
df3を入れてみる

#投入例
batched_import(statement, df3)
{'_contains_updates':True, 'labels_added':82, 'relationships_created':82, 'nodes_created':82, 'properties_set': 492}
82 rows in 0.19221186637878418 s.
82
6.5 システム1の前処理(5)
無事に登録できたのかNeo4jで確認します。
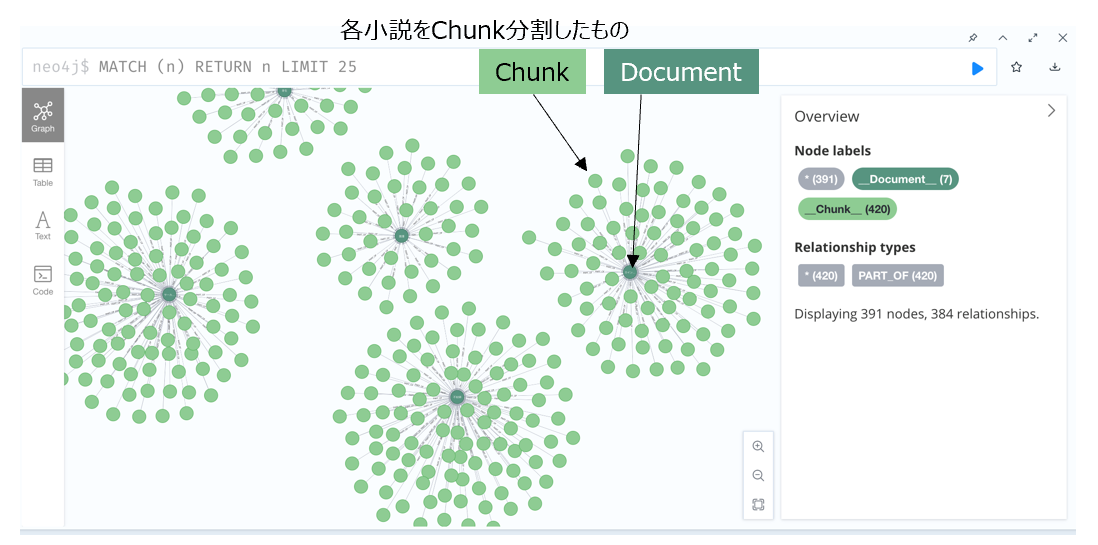
Neo4jに登録できたらチャンクのテキスト(非構造化データ)をembeddingしてベクトル検索できるようにします。
vector_index = Neo4jVector.from_existing_graph(
OpenAIEmbeddings(),
search_type="hybrid",
node_label="__Chunk__",
text_node_property =['text'],
embedding_node_property = "embedding",
url = NEO4J_URI,
username = NEO4J_USERNAME,
password = NEO4J_PASSWORD
)
これでノードラベルが__Chunk__のtextにはベクトル検索ができるようになりました。
軽く動作確認してみましょう。

LangChainのGraphCypherQAChainを使えば、Cypherコマンドを知らなくてもNeo4jに質問実行ができます。なんて便利なライブラリ。少なくともCypherコマンドに馴染みの無い私には最高です。(下記はchainの名前をcypher_chainと名づけて実行させています)

7.システム1(小説のタイトル検索)のRetrieve
- 話の流れから、システム2の前処理の前に、システム1の続きを先に紹介します
7.1 質問から小説タイトルを導き出す仕組み
まずは質問文からエンティティを抽出して、それをキーに、検索できるようにさせましょう
質問文からEntityを抽出するためのLLM Chainの構築するコード
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import Tuple, List, Optional
# Extract entities from text
class Entities(BaseModel):
"""Identifying information about entities.
エンティティに関する識別情報 """
names: List[str] = Field(
...,
description="All countries, organizations, person, event and locations entities that"
"appear in the text of the novel",
)
prompt = ChatPromptTemplate.from_messages(
[
(
"System",
"""Extract entities from the question: novel's title, things, peaple, organizations, countries, events, and places.
Extract as many other entities ( meaningful words and phrases) from the question as possible.
Other examples include entities such as nouns, verbs that describe specific things or actions.
For example:
1. 'へへ' (笑い)
2. The word 'number of times'
3. Action-related words (such as 'appear')
4. Specific items (things) like 'メガネ'
"""
),
(
"human",
"Use the given format to extract information from the following"
"input:{question}",
),
]
)
# Chainの構築
entity_chain = prompt | llm.with_structured_output(Entities)
実際に問題60問からエンティティを抽出してみるコード
1.問題のCSVをDFにします ```python #問題のCSVをDFに取り込む problem_df = pd.read_csv("./dataset/query.csv") problem_df.head() ```
2.LLMを使って問題文からエンティを抽出を実行させます
#抽出実行
# 抽出後の入れ物(空のリスト)を用意
entity_lst = []
#実行
for index,rows in problem_df.iterrows():
# 質問からentityを抽出
signate_query = rows['problem']
# 次の行でLLMが抽出作業を実行します
entity_from_q = entity_chain.invoke({"question":signate_query}).names
# 取り出したエンティティはリストに追加しておきます。
entity_lst.append(entity_from_q)
#確認
entity_lst
[[ '競漕会','農科','文科','レースコース'],
['骸骨男'],
['骸骨男','バス','足跡']
['兄','殺人罪','裁判']
['小説「芽生」','国名']
['武男','浪子','野外']
['小説「芽生」','主人公','東京','小諸','引越し']
['競漕','文科のボート部'],
以降省略
3.正しく抽出できているようですので、これを問題用のDFに追加しておきましょう
problem_df['entity']= entity_lst
problem_df

7.2 実際に小説タイトルを検索する仕組み
問題文から抽出したキーを基に、Cypherコマンドで取り出す仕組みをつくる。
さきほどは、軽く動作確認のために、CypherQAChainを使いましたが、今度は
シッカリ作ります。
問題文から抽出されたEntityを基に小説タイトルを検索するコード
def get_title(entity_fromq_lst):
"""
entity_list to get title
"""
## Tips1 複数のタイトルが候補になった場合は、ユニークなワードのヒットが多い方が小説の候補 ###
#両方のキーワードが含まれる条件を設定
keyword_conditions = " AND ".join([f'(c.text CONTAINS "{word}" OR c.title CONTAINS "{word}")' for word in entity_from_q_lst])
# OR条件を使って、どちらかのキーワードが含まれる条件を設定
or_conditions = " OR ".join([f'(c.text CONTAINS "{word}" OR c.title CONTAINS "{word}")' for word in entity_fromq_lst])
# Cypherクエリに生成した条件を組み込む
query = f"""
MATCH (c:__Chunk__)-[:PART_OF]->(d:__Document__)
WHERE {or_conditions}
WITH d,
SUM(CASE WHEN {keyword_conditions} THEN 1 ELSE 0 END) AS exact_match_count,
COUNT(*) AS total_match_count
WHERE total_match_count > 0
RETURN d.title, exact_match_count
ORDER BY exact_match_count DESC, total_match_count DESC
LIMIT 1
"""
# クエリの実行
res_test = neo4j_graph.query(query)
print(res_test)
if res_test:
# 結果があれば、最もマッチ数が多いタイトルが返る
title_name = res_test[0].get('d.title', 'Unknown Title')
else:
title_name = 'Unknown Title'
return title_name
実行させます
novel_title = []
for index,rows in problem_df.iterrows():
entity_from_q_lst = rows['entity']
#タイトル取得
res_title=get_title(entity_fromq_lst)
#リストに追加
novel_title.append(res_title)
[{'d.title':'競漕','exact_match_count':1}]
[{'d.title':'サーカスの怪人','exact_match_count':66}]
[{'d.title':'サーカスの怪人','exact_match_count':0}]
[{'d.title':'死生に関するいくつかの断想','exact_match_count':1}]
[{'d.title':'芽生','exact_match_count':61}]
[{'d.title':'不如帰','exact_match_count':0}]
[{'d.title':'芽生','exact_match_count':12}]
以下省略
これで質問と小説タイトルの紐づけが完成しました!
問題文と作品名が一覧化できたので、DFに入れて、CSVで取っておきます。
df_tmp = problem_df.copy()
df_tmp['novel_title']=novel_title
display(df_tmp.head())
df_tmp.to_csv("./novel_title.csv", index=False)

この後はシステム2に移ります。
MacBook1台で行っている関係もあり、全作品を1つのNeo4jのDBに入れるのではなく、作品ごとに小説内の質問対応システムを作りました。
8.システム2(小説の内容検索)の前処理
ここから、システム2の説明に入ります。作品ごとに、質問にRAGを使って答えるシステムです。
8.1 KnowledgeGraphの構築
7作品ありますが1例として、小説「死生に関するいくつかの断想」でご紹介します
システムは、neo4jにグラフデータを入れていくわけですが、最初にドキュメントからエンティティ(人や出来事など)を抽出してから、データ入れていきます。エンティティの抽出イメージを再掲します。
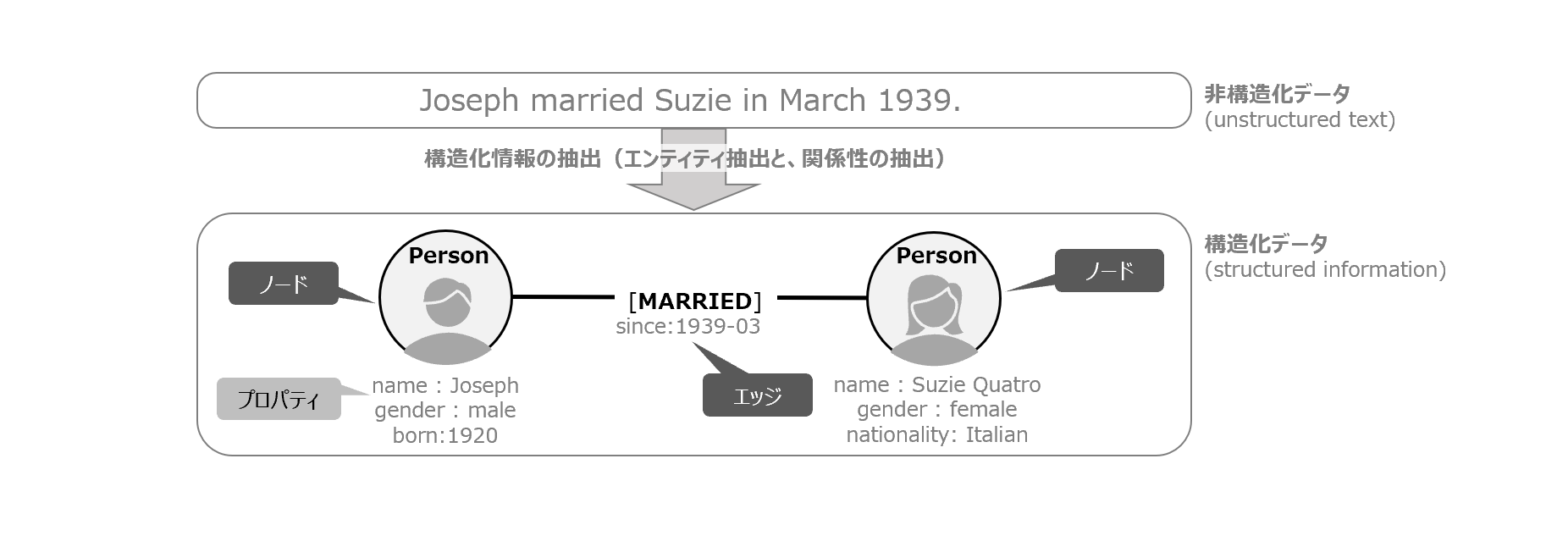
この抽出に、MS GraphRAGなども使っていましたが、基本はLangChainのLLMGraphTransformerという便利なライブラリを利用していますので、そちらで紹介します。
ちなみにエンティティの抽出が不十分なときは、チャンクサイズを小さくするのも1手です。Microsoft GraphRAGの元になった論文 「From Local to Global: A Graph RAG Approach to
Query-Focused Summarization」によれば、チャンクサイズを小さくする方がより多くのentityが抽出できるとあります。一方で、小さくして沢山entityを取得すればよいかと言えば、逆にゴミともいえる不要なノードも増えてしまい、共参照が失われてしまうというトレードオフの関係もあります。
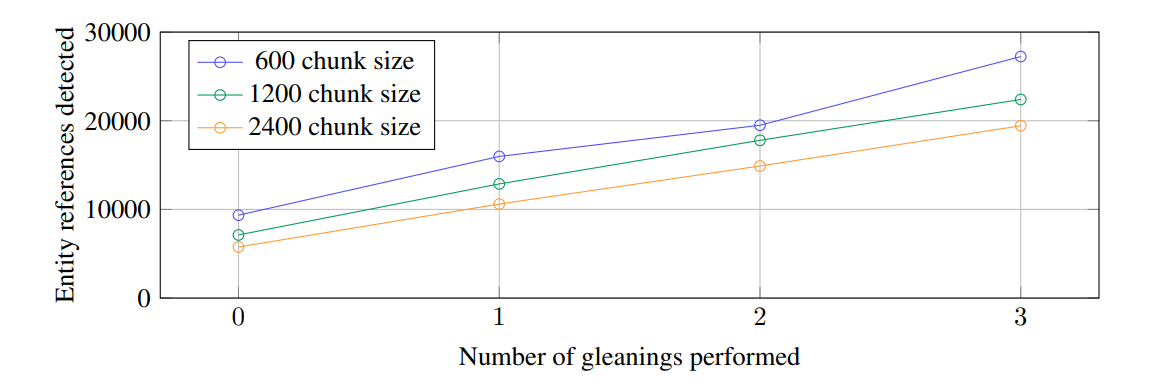
(出典:https://arxiv.org/pdf/2404.16130)
共参照には深くは触れませんが、例えば、推理小説の作品中に、以下の記載がある場合
「見たか、ワトソン!」ホームズが叫ぶ。「見たか?」
私には見えなかった。ホームズがマッチを擦った瞬間に、低く澄んだ口笛は耳にした。だが闇になれた私の目は、突然の光のまぶしさに、
この場合、ワトソンと、私は、同一のエンティティでなければならないのは明白ですが、細かくチャンクしすぎたせいで、「見たか?」の前後で、切れてしまうと、LLMがワトソンと私を同一人物として認識できなくなる可能性が高く、結果的に、同一であるべきエンティティが壊れてしまいます。これを解決する手法もありますが、グラフ理論のディープな世界に入っていくのでここでは割愛します。
8.1.1 Knowledge Graphの構築
Knowledge Graphの構築するコード
1.必要なライブラリのインポート
from langchain_core.runnables import (
RunnableBranch,
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
)
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Feild
from typing import Tuple, List, Optional
from langchain_core.messages import AIMssage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
import os
from langchain_community.graphs import Neo4jGraph
#from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import TokenTextSplitter
from langchain_openai import ChatOpenAI
from langchain_experimental.graph_transformers import LLMGraphTransformer
from neo4j import GraphDatabase
from langchain_communitiy.vectorstores import Neo4jVector
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores.neo4j_vector import remove_lucene_chars
from langchain_core.runnables import ConfigurableField
2.Pickleで固めたドキュメントを引っ張り出す
# 7.死生に関するいくつかの断想
with open(output_pkl_path, "rb") as f:
documents_7 = pickle.load(f)
print("document_7[0]: \n", documents_7[0])
title_name 死生に関するいくつかの断想
output_pkl_path: ./dataset/docs/documents7.pkl
file open...
document_7[0]:
page_content='七月二五日。今週は思いがけない訪問が三つ、我が家にあった。
最初のものは、井戸掃除職人たちだった。毎年すべての (以下省略)'
metadata={'source'}:'./dataset/novels/novel7_死生に関するいくつかの断想.txt','title':'死生に関するいくつかの断想', 'author':'小泉八雲', 'start_index':0}
3.OpenAIの用意
# LLMの定義
llm = ChatOpenAI(temperature=0, model_name="gpt-4o"
4.LangChainによるLLM Graph Transformer
#パラメータを全てデフォルトにする場合は以下
#llm_graph_transformer = LLMGraphTransformer(llm=llm)
#カスタマイズする場合は以下
# 出来不出来によって、他にも色々パメータを試すことも必要.
llm_graph_transformer = LLMGraphTransformer(
llm= llm,
node_properties = ["name","description"] #生成するノードのプロパティに[textとdescription]を設定
relationship_properties = True, # リレーションシップのプロパティ生成はTrue に設定
)
5.パラメータを指定できたら実行(結構時間がかかる)
# 死生に関するいくつかの断想
graph_documents_7 = llm_graph_transformer.convert_to_graph_documents(documents_7)
6.print文や、networkXによる可視化などで適宜確認

7.NetworkXによる可視化
# NetworkXで可視化する関数のコードは省略します。
G7 = create_networkx_graph(graph_documents_7)
visualize_networkx_graph(G7)

8.確認できたらNeo4jに登録します
# Store to Neo4j
neo4j_graph.add_graph_documents(
graph_documents_7,
baseEntityLabel=True,
include_source=True
)
9.テキスト部分もVectorDBとして検索できるようにしておきます
vector_index = Neo4jVector.from_existing_graph(
OpenAIEmbeddings(),
search_type="hybrid",
node_label = "Document",
text_node_properties = ["text"],
embedding_node_property = "embedding",
url = NEO4J_URI,
username = NEO4J_USERNAME,
password = NEO4J_PASSWORD
)

8.1.2 構築したKnowledge Graphの確認
8.1.1で、構造化データと非構造化データが登録されてハイブリッドに検索できる土壌ができました。
下図は、それをNeo4jで登録状況を確認しているところです。
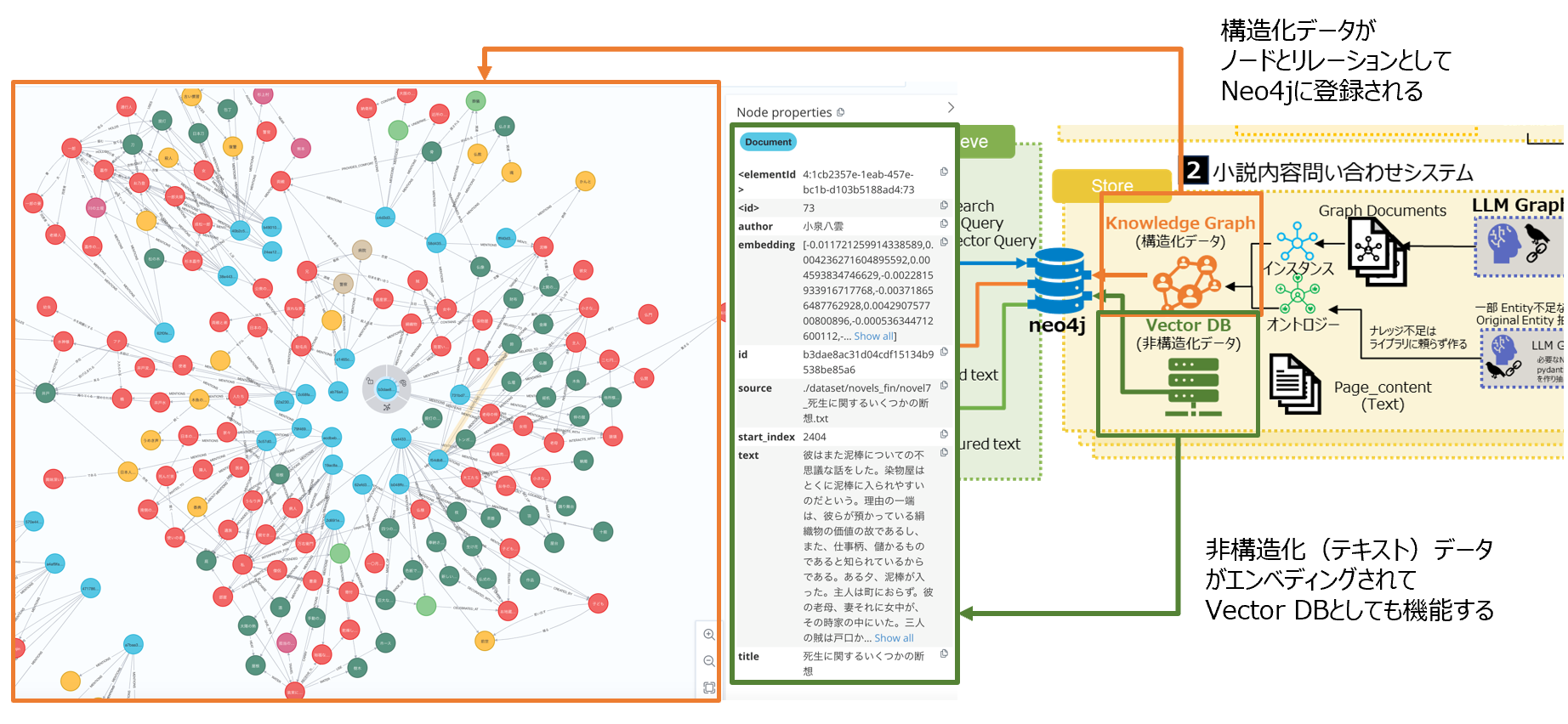
9.システム2(小説の内容検索)のRetrieve
ここからRAGを使って、関連ドキュメントを抜き出し、LLMへのテンプレートに埋め込む作業となります。GraphRAGでは、通常のテキスト(非構造化データ)だけではく、ノード間のリレーションで構築された構造化データも両方をプロンプトに入れてあげる必要があります。このことで、通常のVectorDBだけでは難しかった、文脈を理解するなどを補うことができるのです。
この部分を作りこんでいきます。
9.1 構造化データの取得
構造化データを取ってきた後に、どのように処理するかがポイントです。
よくあるのが構造化データをテキストにフラット化させるものです。これを便宜上、通常版と呼びます。また、その方法だけでは対応が難しい質問に対しては、それなりにHackを入れてあげる必要があります。この辺が難しいところだと思いますが、今回は特別に1例もお見せします。
1.構造化データの取得コード【通常版】
1.全文検索クエリを作成します。ここは共通です。
# cf.Enhancing the Accuracy of RAG Applications With Knowledge Graphs
# https://medium.com/neo4j/enhancing-the-accuracy-of-rag-applications-with-knowledge-graphs-ad5e2ffab663
def generate_full_text_query(input:str) -> str:
"""
Generate a full-text search query for a given input string.
This funcition construts a query string stuitable for a full-text search.
It processes the input string by splitting it into words and appending a
similarity threshhold (~2 changed characters) to each word, then combines
them using the AND operator. Useful for mapping entities from user questions
to database values, and allows for some missplings.
--- japanese ---
指定された入力文字列の全文検索クエリを生成します。
この関数は、全文検索に適したクエリ文字列を構築します。
入力文字列を単語に分割し、各単語に類似性閾値(変更された文字が約2文字)を追加して処理し、
AND 演算子を使用して結合します。
ユーザの質問からデータベース値にエンティティをマッピングするのに役立ち、
多少のスペルミスも許容します。
"""
full_text_query = ""
words = [el for el in remove_lucene_chars(input).split() if el]
for word in words[:-1]:
full_text_query += f" {word}~2 AND"
full_text_qury += f" {words[-1]}~2"
return full_text_query.strip()
2.質問で言及されたエンティティの近隣を取得します【通常版】
Neo4jに、Cypherコマンドで検索し、結果の取得をフラット化させて、返り値とする。関係性が逆方向も返す。
# Fulltext index query
def structured_retriever(question: str) -> str:
"""
Collects the neighborhood of entities mentioned in the question
質問で言及されたエンティティの近隣を収集します
"""
#回答を格納する箱
result = ""
#通常のエンティティ抽出処理
entities = entity_chain.invoke({"question": question})
print(f"Entities extracted: {entities.names}") #エンティティ抽出後の出力
# クエリ処理
for entity in entities.names:
# 各エンティティに対するクエリの開始
response = graph.query(
"""CALL db.index.fulltext.queryNodes('entity', $query, {limit:2})
YIELD node,score
CALL {
MATCH (node)-[r:!MENTIONS]->(neighbor)
RETURN node.id + ' - ' + type(r) + ' -> ' + neighbor.id AS output
UNION
MATCH (node)<-[r:!MENTIONS]-(neighbor)
RETURN neighbor.id + ' - ' + type(r) + ' -> ' + node.id AS output
}
RETURN output LIMIT 50
""",
{"query": generate_full_text_query(entity)},
)
# NodeTypeを除外してresultに追加
result += "\n".join([el['output'] for el in response])
return result
-
(node)-[r:!MENTIONS]->(neighbor)と、逆方法の(node)<-[r:MENTIONS]-(neighbor)で両方向の検索をしています。
2.構造化データの取得コード【Hack版】
if 文を使い、何回という言葉が登場したら、名前をカウントするようなHuckを入れています。
# huck版
# Fulltext index query
def structured_retriever_with_namecount(question: str) -> str:
"""
Collects the neighborhood of entities mentioned in the question and handles cases where a count is requested.
質問で言及されたエンティティの近隣を収集し、出現回数が求められている場合に対応します。
"""
#回答を格納する箱
result = ""
#通常のエンティティ抽出処理
entities = entity_chain.invoke({"question": question})
print(f"Entities extracted: {entities.names}") #エンティティ抽出後の出力
#「何回」というキーワードが質問に含まれているか確認してカウントさせる部分を追加(Hack部分)
if "何回" in question:
for entity in entities.names:
# 該当するエンティティの出現回数をCypherクエリで検索します
cypher_response = neo4j_graph.query(
"""
MATCH (d:Document)-[:MENTIONS]->(p:Person{name: $entity_name})
RETURN count(d) AS occurrences
""",
{'entity_name': entity}
)
occurrences = cypher_response[0]['occurrences']
result += f"「{entity}」という名前は{occurrences}回登場します。\n"
else:
# クエリ処理(通常の部分)
for entity in entities.names:
response = graph.query(
"""CALL db.index.fulltext.queryNodes('entity', $query, {limit:2})
YIELD node,score
CALL {
MATCH (node)-[r:!MENTIONS]->(neighbor)
RETURN node.id + ' - ' + type(r) + ' -> ' + neighbor.id AS output
UNION
MATCH (node)<-[r:!MENTIONS]-(neighbor)
RETURN neighbor.id + ' - ' + type(r) + ' -> ' + node.id AS output
}
RETURN output LIMIT 50
""",
{"query": generate_full_text_query(entity)},
)
# NodeTypeを除外してresultに追加
result += "\n".join([el['output'] for el in response])
return result
通常版(structured_retriever)を利用した場合
q20="染物屋の家族が、泥棒から身を守ることができた理由は何ですか?"
print(f"問題20: {q20}")
print(entity_chain.invoke({"question":q20}}.names)
print(structured_retriever(q20))
構造化データがテキストとしてフラット化されて返ってきてます
問題20: 染物屋の家族が、泥棒から身を守ることができた理由は何ですか?
['染物屋','家族','泥棒','身を守る','理由']
Entities extracted:['染物屋','家族','泥棒','身を守る','理由']
屋敷の持ち主 - FOLLOW_RULES -> 水神様
装束に身を包んだ地元の火消したち - WATER -> 屋ね
太陽の熱 - HEAT -> 屋根屋敷の持ち主 - FOLLOW_RULES -> 水神様
井戸掃除職人たち -CLEAN -> 井戸屋敷の持ち主 - FOLLOW_RULES -> 水神様
井戸掃除職人たち -CLEAN -> 井戸屋敷の持ち主 - FOLLOW_RULES -> 水神様
井戸掃除職人たち -CLEAN -> 井戸
Hack版(structured_retriever_with_namecount)を利用の場合
q19="「万右衛門」という名前は何回登場しますか?"
print(f"問題19: {q19}")
print(entity_chain.invoke({"question":q19}}.names)
print(structured_retriever_with_namecount(q19))
エンティティをキーにして、Cypherコマンドで登場回数をカウントしてそれを
f文字列に埋め込んで返してくれています。
問題19: 「万右衛門」という名前は何回登場しますか?
['万右衛門','名前','何回','登場']
Entities extracted:['万右衛門','名前','何回','登場']
「万右衛門」という名前は7回登場します。
「名前」という名前は0回登場します。
「何回」という名前は0回登場します。
「登場」という名前は0回登場します。
9.2 非構造化データの取得
構造化データがうまく取得できたので、今度はいつものRAGのやり方で関連するドキュメントも取得できるようにしましょう。
retrieverの構築
# 関連ドキュメントのメタデータの中に類似スコアも埋め込んで取得できるよう改良します。
# これは後で何かスコアが役立つかと思って入れたものです。スコア値はなくてもGraphRAGには問題ないです。
from typing import List
from langchain_core.documents import Document
from langchain_core.runnables import chain
@chain
def retriever_with_score(query:str) -> List[Document]:
docs,scores = zip(*vector_index.similarity_search_with_score(query,
k=4,
))
for doc, score in zip(docs, scores):
doc.metadata["similarity_score"] = score
return docs
#ちなみにこんな感じに@chainというデコレーターで固めてあげると、RannableLambdaに変えることができます。そうなると直接invokeが使えて使い勝手がよくなるので便利です。
print(type(retriver_with_score))
# langchain_core.runnables.base.RunnableLambda
retriever_with_score.invoke("質問文をここに入れる") #<=こんな感じで使えます
retrieverの構築が完了したら確認してみましょう。今度はわざわざentity抽出を挟む必要はないのでそのまま質問をretriverに入れてあげます。
print(f"問題19: {q19}")
print(retriever_with_score.invoke(q19))
問題19: 「万右衛門」という名前は何回登場しますか?
(Document(metadata={'auther':'小泉八雲','title':'死生に関するいくつかの断想','start_index':'11100','source':'./dataset/novels/novel7_死生に関するいくつかの断想.txt','similarity_score':'1.0'},page_content='\ntext:けれども、万右衛門の古くさい身振りにもかかわらず、その忍耐強い精神も、この昔に煩わせられるように(--中略--)文句を繰り返した。'),
Document(metadata={'auther':'小泉八雲','title':'死生に関するいくつかの断想','start_index':'11524','source':'./dataset/novels/novel7_死生に関するいくつかの断想.txt','similarity_score':'1.0'},page_content='\ntext:木魚の音や読経は数時間続いた。(--中略--)と万右衛門が言った。\n私たちは相談した。万右衛門は(--中略--)興味深いものである。'),
Document(metadata={'auther':'小泉八雲','title':'死生に関するいくつかの断想','start_index':'10617','source':'./dataset/novels/novel7_死生に関するいくつかの断想.txt','similarity_score':'0.9907980986169178'},page_content='\ntext:十二月二十八日。庭の周囲の高い(--中略--)私の古い通訳者の万右衛門が(--中略--)ということだった。'),
Document(metadata={'auther':'小泉八雲','title':'死生に関するいくつかの断想','start_index':'0','source':'./dataset/novels/novel7_死生に関するいくつかの断想.txt','similarity_score':'0.9868569842277384'},page_content='\ntext:七月二五日。今週は思いがけない訪問が三つ(--中略--)その井戸はそれ以後ずっと濁ったままであるからだという。'),
関連性の高いものから4つ関連ドキュメントが取得できています。また、確かにpage_contentの中には"万右衛門"の文字が登場しています。
ただ、勘の良い方ならわかりますが、小説の作品全体を通して、万右衛門が何回登場するのかという質問に対して、小説作品の文章全体ではなく、抽出した4つのチャンクで判断してしまえば、数え漏れがありますよね。この辺が類似度による検索に頼るRAGの限界かと思います。
9.3 2つの情報を結合する
構造化データおよび非構造化データが取得できたら、これを結合させたドキュメントを関連ドキュメントとして、LLMに渡してあげる必要があります。ので、結合させます。と言っても、pythonなので取得したテキストデータをf文字列でつなぐだけです。

2つの情報を結合して検索する関数を定義するコード
def retriver_with_namecount(question: str):
print(f"Search query: {question}")
# 1.構造化データ
#グラフDB検索(質問からエンティティを抽出し、グラフDBで検索。結果の関連情報をテキスト化して返す)
# 2種類作ったのでどちらか好きな方を選択(下記はHuck版を選択した場合)
# structured_data = structured_retriever(question) #通常版
structured_data = structured_retriever_with_namecount(question) #Huck版
# 2.非構造化データ
# 通常のVectorDB検索でのテキストドキュメント結果を返すもの
# 2種類あるので、すきな方を選択。(下記は類似度スコア付きを選んだ場合)
# unstructured_data = [el.page_content for el in vector_index.similarity_search(question)] #スコア無しのRAG検索
unstructured_data = [el.page_content for el in retriever_with_score.invoke(question)] #スコアを追加したもの
# 取得したデータを結合(1+2)
final_data = f"""
Structured data:{structued_data}
Unstructured data: {"#Document". join(unstructured_data)}
"""
return final_data
10.システム2(小説の内容検索)のAugment
プロンプト部分には、上記まで苦労して作ったRAGの情報を与えてあげます。
10.1 プロンプトとLLM Chainの構築
プロンプトにはRAG情報だけでなく、今回のコンペでの制限事項などを記載します。また、出力として、回答と根拠の両方をしっかりとした出力形式で取得したいので、JsonOutputParserを用いて作りこみます。
プロンプトおよびRAGを使った LLM Chain構築
1.出力形式の定義from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel,Field
# 1.出力形式の定義
class Answerformat(BaseModel):
answer: str = Field(description="Please answer the questions concisely."
evidence: str = Field(description="Provide evidence that supports your answer by extracting it from the referenced documents. Do not edit the evidence.")
# Set up a parser
parser = JsonOutputParser(pydantic_object=Answerformat)
2.テンプレートの定義
# 2. テンプレートの定義
from langchain_core.messages import SystemMessage
from langchain_core.prompts import HumanMessagePromptTemplate
message_template = """
提供された小説(コンテキスト)のみを使用して、このquestionのanswerを簡潔に答えてください。
また、answerのevidenceとなるcontext部分を抜粋して示してください。
# 注意事項
1.数量で答える問題の回答には単位をつけること
2.複数列挙する答えは、読点とすること。カンマ区切りはつかわないこと
question:{question}
context:{context}
answer and evidence:{format_instructions}
"""
prompt = ChatPromptTemplate(
messages=[
SystemMessage(
content=(
"""
あなたは、ユーザに対して、小説に対する質問に的確に答えることができるアシスタントです。
提供された小説(コンテキスト)のみを使用して、質問に簡潔に答えることができます。
なお、質問には、answerのevidenceとなるcontextの部分を抜粋して示します。
回答には以下の注意事項を厳守してください。
#注意事項
1.数量で答える問題の回答には単位をつけること
2.複数列挙する答えは、読点とすること。カンマ区切りは使わないこと
3.参照元に答えの手がかりが見つからないと判断される場合はその旨を「分かりません」と答えること。
"""
)
),
HumanMessagePromptTemplate.from_template(
message_template
),,
],
input_variables = ["question","context"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
3.LLM Chain (Agent)の構築
# 3. LLM Chain (Agent)の構築
from langchain_core.runnables import RunnablePrallel
def format_docs(docs):
return "\n\n".join(docs)
# 3.1 RAG Chainの後に続く部分
rag_chain_from_docs = (
# 参照するドキュメントを追加
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| prompt
| llm
| parser
)
# 3.2 RAG構築したら 3.1で作成したものをアサインさせる
rag_chain_with_source_doc_namecount = RunnableParallel(
{
"content": retriever_with_namecount,
"question": RunnablePassthrough()
}
).assign(answer=rag_chain_from_docs) # 3.1でつくった部分
11.システム2(小説の内容検索)のGenerate
# 死生に関するいくつかの断想に関する質問
print("query_test":q20)
answer_test = rag_chain_with_source_doc_namecount.invoke(q20)
print(answer_test)
少し文字が小さいですが、構造化データと非構造化データが取得され、それをもとに回答を完結にまたエビデンスも辞書形式で返してくれています。

このようにDict形式で返ってくるとDataFrameに変形しやすく、CSV出力も容易になるために私はDataFrame化して確認していました。こんな感じです。

12.他のアプローチ
1.RAG Fusion
KnowledgeGraphや、RAGのコサイン類似度だけではどうにもならない問題も多く、途中で質問文の聞き方が悪いことに気づき、RAG Fusionと呼ばれるQueryを多様化させて、リランキングさせる方法を試しました。結果かなり精度が上がったので、これを次に記載します
2.Microsoft GraphRAG
今回GraphRAG(ナレッジグラフ)のアプローチは、基本は、LangChainを用いたアプローチで対応してますが、Microsoft GraphRAGの精度も高いと思っていたので、デフォルトのまま試しています。しかしながら、かなりカスタマイズしないと有効性が得られないと感じました。特に、ドキュメント全体にわたる質問に対して、回答が得られるグローバルサーチというメソッドをすごく期待したのですが、結果は「わかりません」が多かったです。
13.RAG Fusion
13.1 RAG Fusionの概要
以下のステップでQueryを複数生成したあと、もっともよい関連ドキュメントから最終回答を得ます。
- Query Generator
質問(query)に対して、類似する複数のクエリをLLMに生成させる - Search Query
それぞれベクトル検索してチャンクを取得 - Reciprocal Rank Fusion
取得したチャンクをリランキングしてスコアが上位をコンテキスト情報にする - Generative Output
最終的な回答を生成

出典: Langchain Query Transformations
- 詳細は、こちら以下を参照してください
- LangChain: Query Transformations
- Blog Post: Forget RAG, the Future is RAG-Fusion
- LangChain Implementation: Github RAG Fusion
13.2 構築のコード
1. Query生成のコード
def query_generatior(original_query:dict)->list[str]:
"""
Generate queries from original query
Args:
query(dict):original query
Returns:
list[str]: list of generated queries
"""
#original query
query = original_query.get("qurey")
#Prompt for query generator
prompt = ChatPromptTemplate.from_messages([
(
"System","あなたは、単一の入力クエリに基づいて複数の検索クエリを生成する優秀なアシスタントです。"
),
(
"user","""{original_query}に関連する複数の検索クエリを生成します。
クエリを生成するときは、様々な聞き方で答えに届く可能性がある検索文を生成してください。
なお生成する検索クエリの1つは、短く直接的なものを1つは含めてください。"""),
(
"user","OUTPUT (3 queries):")
})
query_generator_chain = (
prompt | llm | StrOutputParser() | (lambda x: x.split("\n"))
# 0番目にオリジナル質問を入れる
queries.insert(0, "0. " + query)
print('Generated queries:\n', '\n'.join(queries))
return queries
実行例
q10="兄が情死を試みた時点から、実際に死亡するまでおよそ何年経過したと考えられますか?"
query_generator({"query":q10})
Generated queries:
0.兄が情死を試みた時点から、実際に死亡するまでおよそ何年経過したと考えられますか?
1.兄が情死を試みた後、実際に死亡するまでの平均的な期間はどれぐらいですか?
2.情死未遂から死亡までの時間経過に関する統計データはありますか?
3.兄の情死未遂から志望までの年数は?
2.RRF(Reciprocal Rank Fusion)の関数定義
取得したチャンクをリランキングしてスコアが上位をコンテキスト情報にする
def reciprocal_rank_fusion(results: list[list], k=60):
"""Rerank docs (Reciprocal Rank Fusion)
Args:
results (list[list]): retrieved documents
k ( int, optional): parameter k for RRF, Dedaults to 60
Returns:
ranked_results : list of documents reranked by RRF
"""
fused_scores = {}
for docs in results:
for rank,doc in enumerate(docs):
doc_str = dumps(doc)
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
fused_scores[doc_str] += 1 / (rank + k)
reranked_results = [
( loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
print("Reranked Documents:", len(reranked_results))
for doc in relanked_results:
print("--- ---")
print('Docs: ', ' '.join(doc[0].page_content[:100].split()))
print('RRF score: ', doc[1])
print("--- ---")
return [x[0] for x in reranked_results[:MAX_DOCS_FOR_CONTENT]]
3.Search Query
from typing import List
from langchain_core.documents import Document
from langchain_core.runnables import chain
@chain
def retriever2_with_score(query:str)->List[Document]:
docs, scores = zip(*vector_index.similarity_search_with_score(query,
k=TOP_K,))
for doc, score in zip(docs,scores):
doc.metadata("similarity_score") = score
return docs
# Retriever Options
TOP_K = 2
MAX_DOCS_FOR_CONTENT = 8
import typing
from operator import itemgetter
from langchain.load import dumps, loads
def rrf_retriever(query: str)-> typing.List[Document]:
""" RRF retriever
Args:
query(str): Query string
Returns:
list[Document]: retrieved documents
"""
retriever = retriever2_with_score
chain = (
{"query": itemgetter("query")}
| RunnableLambda(query_generator) # query_generatorを使って質問を増やす
| retriever.map() #疑似クエリ3つを含む4つをベクトル検索 K=2の数だけチャンク取得
| reciproal_rank_fusion # RRF
)
# invoke
result = chain.invoke({"query":query})
return result
4.最終的な回答を生成
# Generate Output
message = """
提供されたコンテキストのみを使用して、この質問に端的に答えてください。またevidenceとなる部分も提示して下さい。
以下のフォーマットで回答してください。
answer: [ここに回答]
evidence: [ここにエビデンス]
質問:{question}
Context: {context}
"""
prompt_rrf = ChatPromptTemplate.from_messages(("human",message))
from langchain_core.output_parsers import BaseOutputParser
#カスタムのアウトプットパーサーを使用
class DictOuputParser(BaseOutputParser):
def parse(self, text: str) -> list:
# テキストフォーマットが"answer"と"evidence"に分かれていると仮定
try:
answer, evidence = text.split("evidence:")
answer = answer.replace("answer:","").strip()
evidence = evidence.strip()
except ValueError:
return [{"answer":"", "evidence":""}]
return [{"answer":answer, "evidence": evidence}]
# RAG準備
from langchain_core.output_parsers import StrOutputParser
rff_rag_chain = (
{"context": rrf_retriever, "question":RunnablePassthrough()}
| prompt_rrf
| llm
| DictOutputParser() #カスタムパーサー使用
)
13.3 確認
コードの構築が終わったら、試験的に1問確認してみましょう。
# 試験的に1問実行する
rrf_rag_reseponse = rrf_rag_chain.invoke(q10)
print("------実行終了-------")
print("回答結果: ")
print(rrf_rag_reseponse)
Generated queries:
0.兄が情死を試みた時点から、実際に死亡するまでおよそ何年経過したと考えられますか?
1.兄が情死を試みた後、実際に死亡するまでの平均的な期間はどれぐらいですか?
2.情死未遂から死亡までの時間経過に関する統計データはありますか?
3.兄の情死未遂から志望までの年数は?
Reranked documetns: 3
--- ---
Docs: text: 一二月二九日。予想したように、死んだ男の話はなかなか聴きでがあった。この家族は四人である父と母は高齢で弱っているが、それに二人の息子がいる。死んだのは三四歳の長男で、七年も患っていた。歳
RRF score: 0.06557377049180328
--- ---
--- ---
Docs: text: どんな刑が言い渡されたのか、詳細は知らない。当時日本の裁判官は、人情がらみの犯罪を裁く場合、かなりの個人的裁量を有していた。刑法典は西洋のをモデルに作られたものであったが、情状酌量の余地
RRF score: 0.03333333333333333
--- ---
--- ---
Docs: text: つぎは兄の話である。兄は二〇歳の頃、魚の行商をしていたが、ある旅館の綺麗な女中を好きになった。娘も彼の愛情に答えた。二人はお互いに将来を誓い合った。しかし、結婚するにはいくつかの障害があ
RRF score: 0.03333333333333333
--- ---
------実行終了-------
回答結果:
[{'answer': '約14年',
'evidence': '兄が情死を試みたのは20歳の頃であり、死亡したのは34歳の時であるため、約14年が経過していると考えられます。'}]
複数質問を生成し、それぞれで関係性の高いドキュメントを得て、リランキング後に
得たドキュメントを用いて、正解である14年という回答を導き出せています。
このように素晴らしい回答が返ってくるのがわかったので、これを対象小説全部に対して、for文で実行させます。得た回答は、answerとevidenceの辞書型が格納されたリストで返ってくるので、これをさらにデータフレームに格納すると見やすくなります。

14.GraphRAG vs RAG Fusion
「結局どっちがいいの?」と、思われると推察されるので比較してます
14.1 GraphRAGとRAG Fusionの結果比較
サンプルとして4問、「GraphRAGのみの実行結果」と「RAG Fusionのみの実行結果」を比べます
GraphRAG(knowledge)のみの場合

問題19の「「万右衛門」という名前は何回登場しますか?」という文章全体にわたる問題に対して、全て漏れなくカウントして、正しく答えているのがわかります。他の設問には間違えていました。
RAG Fusionのみの場合

一方、RAG Fusionのみを利用した場合、逆にGraphRAGで正解であった問題19は間違えていますが、聞き方を工夫して情報を集めてくれた結果、問題10、問題47にも正しく答えてくれています。
14.2 比較の結論
RAG Fusionはチャンク分割された中で、関連性の高いドキュメントをStoreから正しく引っ張り出すには、素晴らしい成果を上げる。一方で、ドキュメント全体にわたる問題に対しては弱く、そういう問題はGraphRAG(KnowlegeGraph)の方に軍配が上がる。ということになります。
(補足:もちろんこの2つを組み合わせてコーディングすることもできますし、GraphRAGの裏側にあるナレッジグラフを作りこんで、GraphRAGだけで、問題10や47に回答させることもできると思います。)
15.成績および表彰式
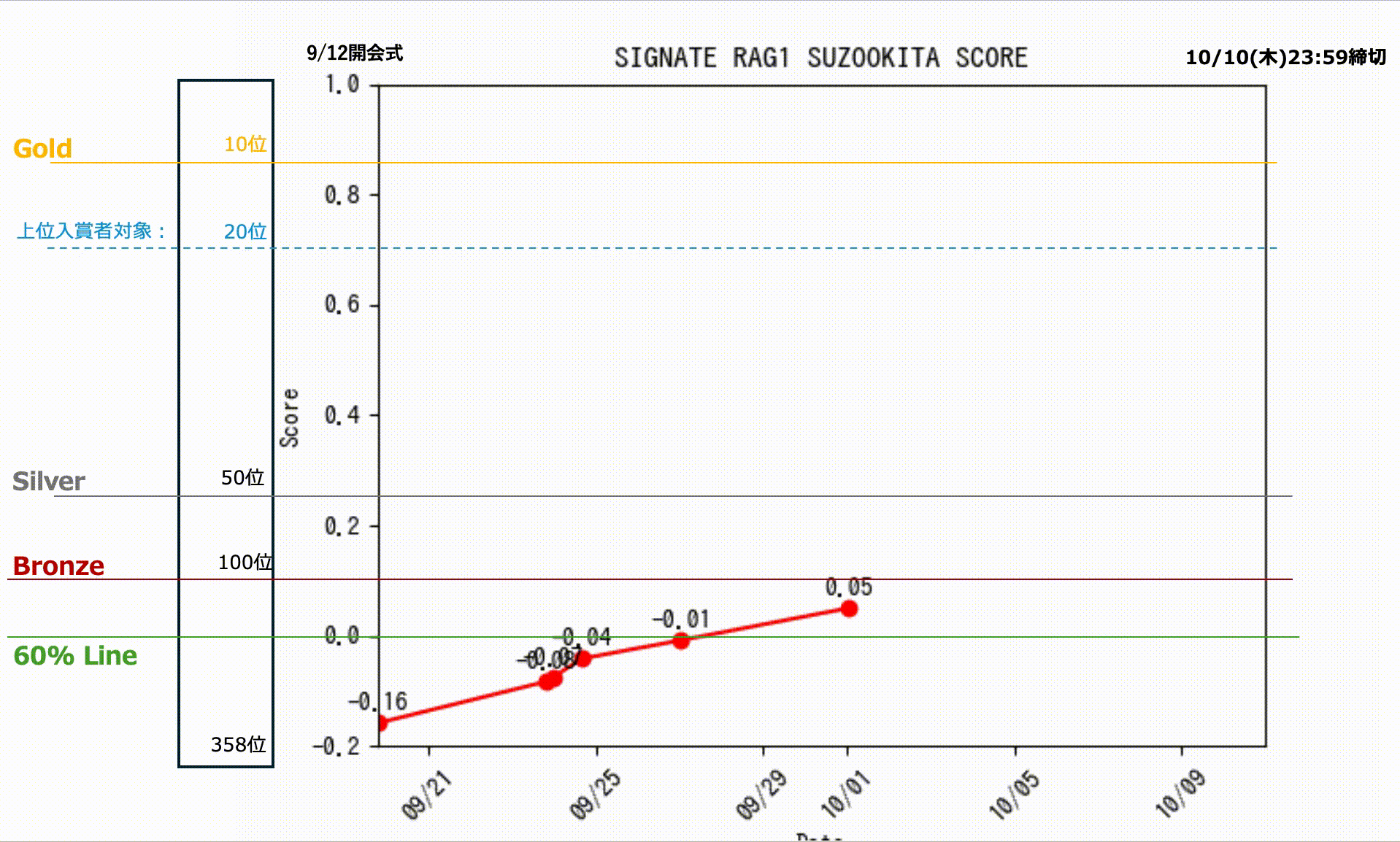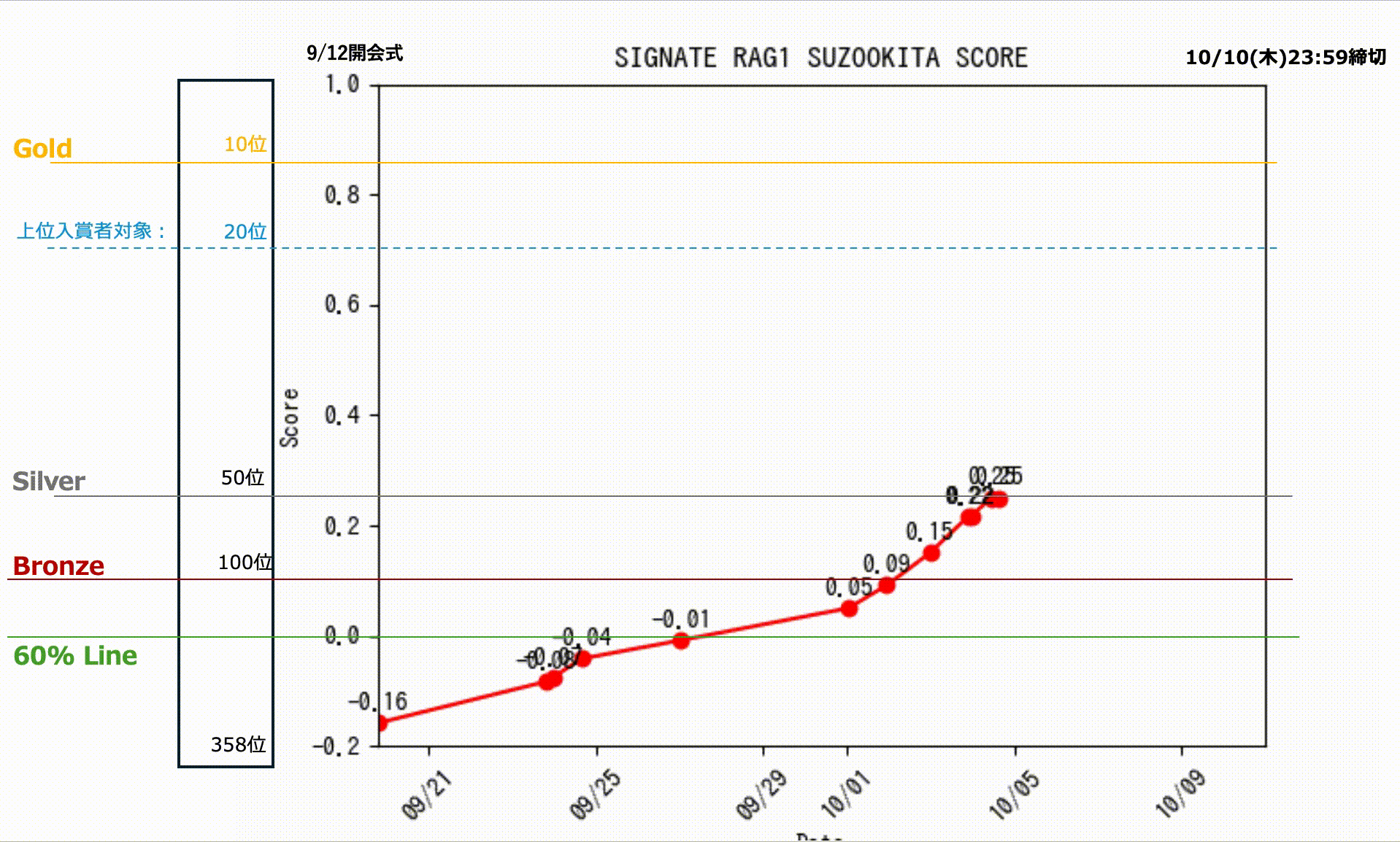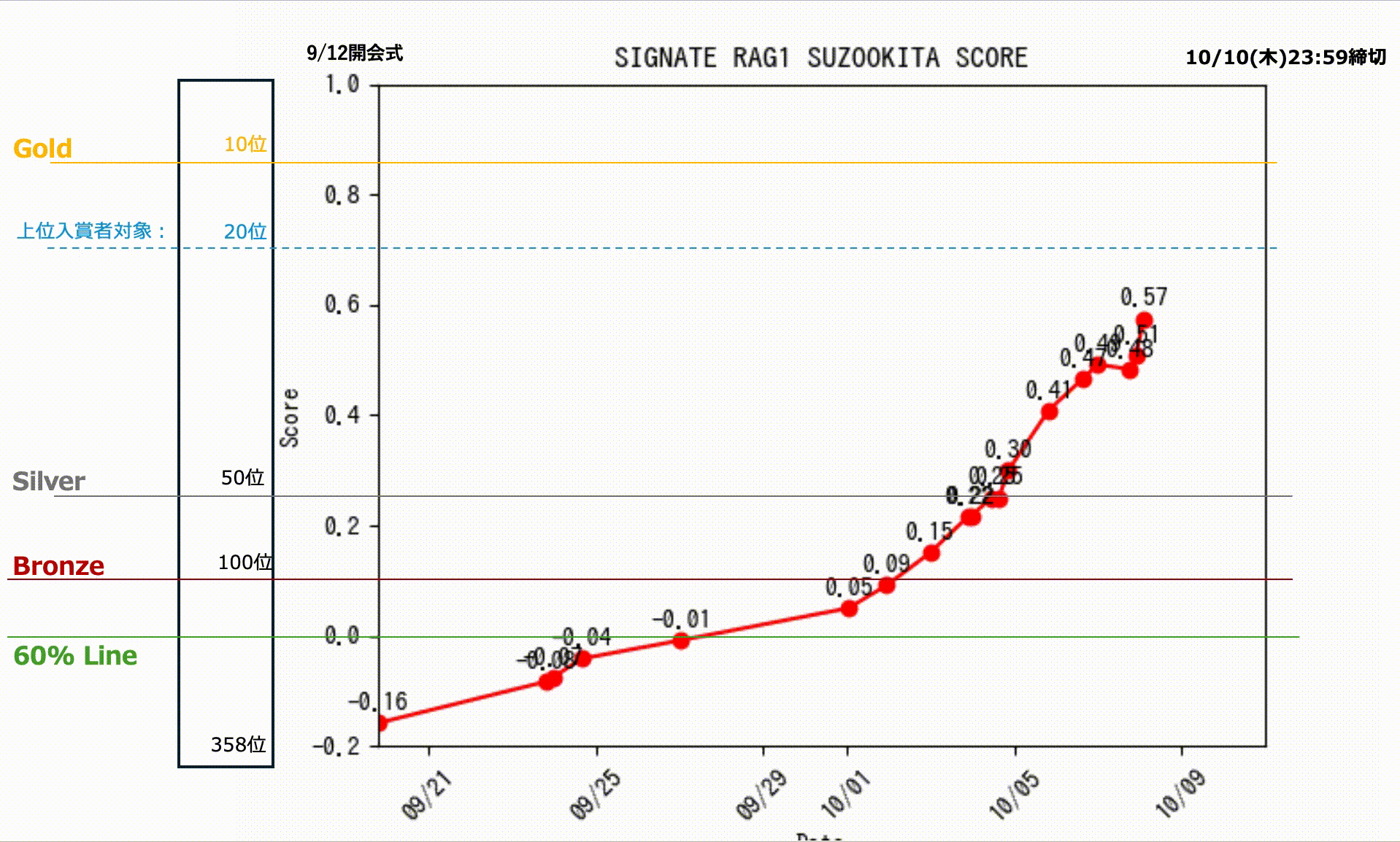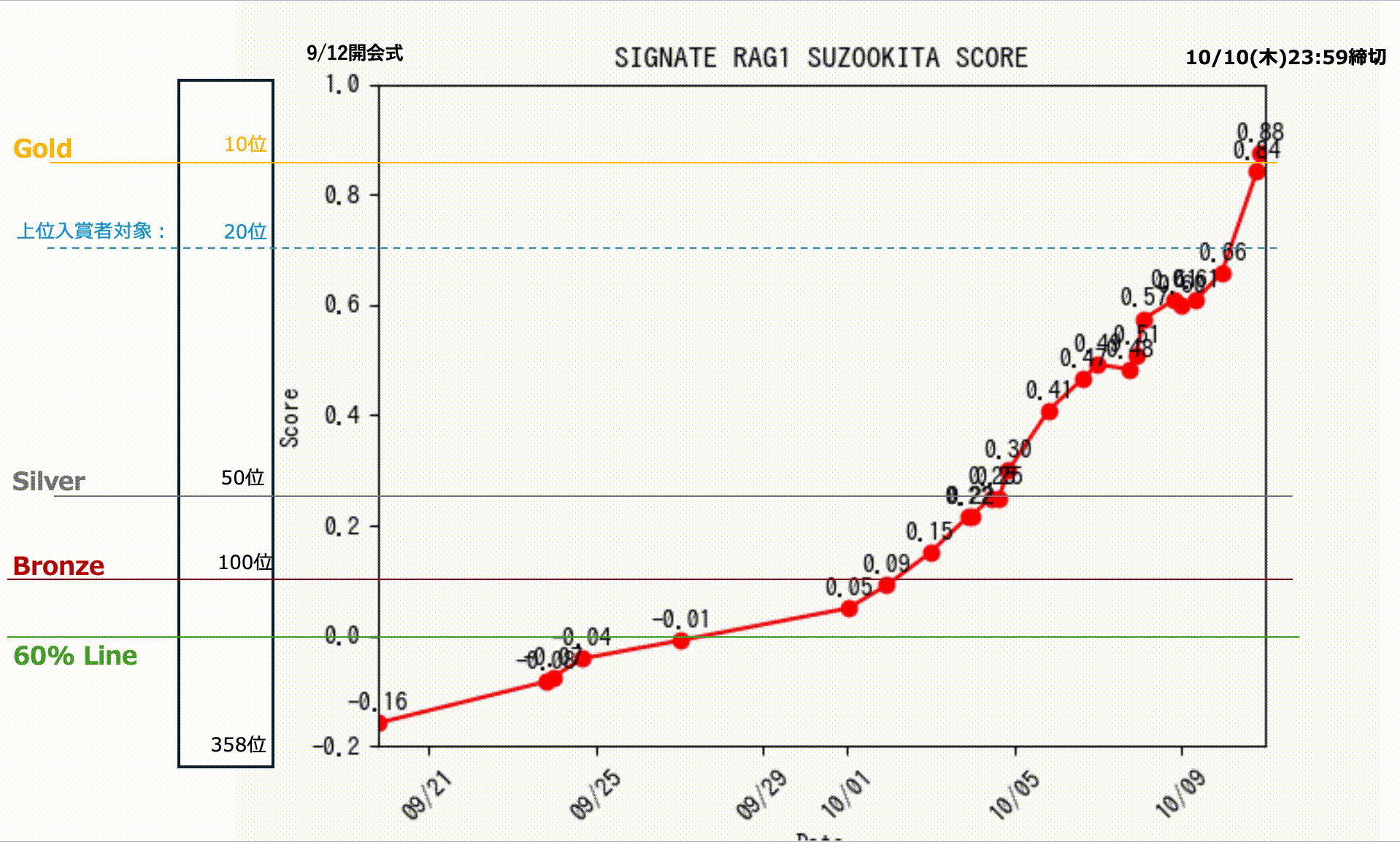
15.1 私の成績
私のスコアの推移です。終了直前まで8位でしたが、欲張って締切終了間際ギリギリに投稿したものが1問間違えを多く含んでしまい。そのままタイムアップ。一番よい成績を選択できなかったというミスを犯して9位で終わりましたが、なんとか入賞できました。
15.2 表彰式兼、知的共有会
参加者のだけの特権なので知的共有会の内容を全てを言うことはできませんが、事務局側から知的共有会開催前に連絡があり、私はパネリストとして参加しています。その場で難問に対する解法を共有させて頂きました。この部分は私の知見ですので、それをここで共有したいと思います。
16.難問の解説
- 今回の問題は、60問あり、小説がテーマではありましたが、ビジネスケースを意識して質問の種類がカテゴリ分けされていました
- 特に難しい問題のうちの1つが、今回解説するカテゴリーの問題で、上位20名の平均成績でも、若干見劣りする感じで苦戦している様子がうかがえましたしたが、私は0.94と高得点でした
16.1 具体例の解説
- 対象小説:江戸川乱歩 小説「サーカスの怪人」
- 難問:質問15「馬に乗った骸骨男を見つけてから、明智が投げ縄をするまでに縮めた差は何メートルだと考えられますか?」
どうやって解けばよいでしょうか?
-
Step1.まずは正解を知るために、時間のある方は、小説の最終章が対象なのでそこだけでも以下の青空文庫のリンク先から読んでみてください
- 青空文庫 サーカスの怪人
- 一番最後の章二十面相の最後だけでよいです。そこに答えがあります
- 生成AIと違い、人間だと読解力で割と簡単に正解がわかります
-
Step2 RAGシステムを導入し、LLM(生成AI)に答えさせます
- RAGを導入したLLM(生成AI)に対し、質問文そのままに聞いても、答えは「30メートルです」とか「40メートルです。」と答えます。おそらく以下あたりを読んで答えています
骸骨男とのあいだが、だんだん、ちぢまっていきました。四十メートル、三十メートル、二十メートル、ああ、もう十メートルほどになりました。手に汗にぎる競馬です。うしろのウマが、ぐんぐん、前のウマにせまっているのです。
-
Step3 課題を理解して解決する
- これはなぜこの様なことがおこるのでしょうか?
問題文をよく読むと、「馬に乗った骸骨男を見つけてから、」の部分の主語が抜けています。日本語特有の問題です。この主語は何でしょうか?もう少し小説を遡ると、こう記述があります。
骸骨男のウマは、それよりもっと先を走っているらしいのですが、夜のことですから、はっきり見えません。
警察自動車には、小型のサーチライトがつみこんでありました。ひとりの警官が、それをとり出して、自動車を走らせたまま、屋根の前にとりつけたスイッチをおしますと、パアッと光の棒がのびて、百メートルも先を白く照らしだしました。- つまり、主語は、パトカーに乗っていた人(中村警部ら)が発見した時が、「馬に乗った骸骨男を見つけてから」の主語になります。通常のRAGだけでは、LLM(生成AI)が、主語、述語、目的語を正しく理解したり、文章全体から文脈を正しく把握する。というが弱点であるところが透けてみえませんか?チャンク分割された一部で回答すると、こういう間違いが起きます
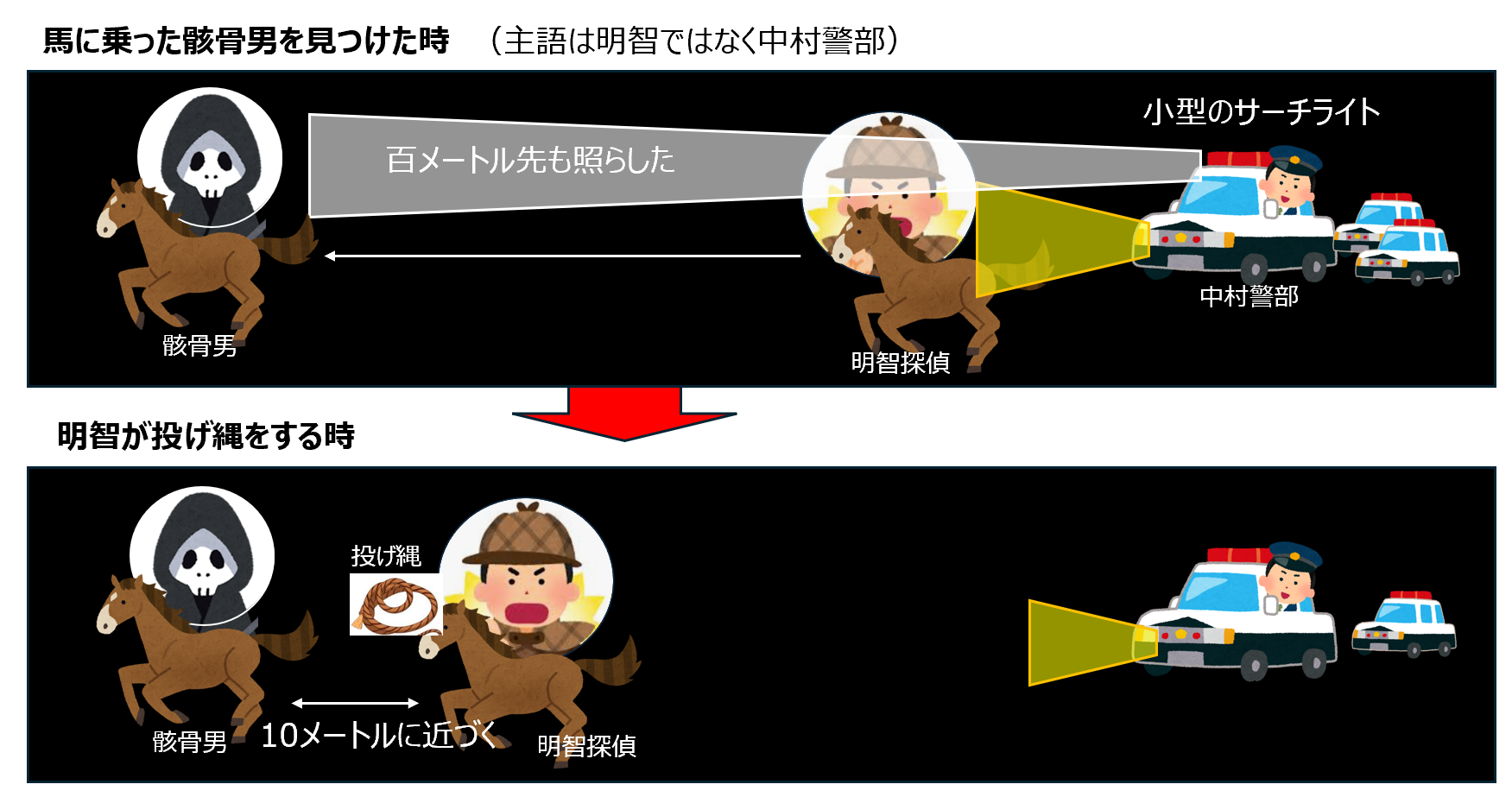
- これはなぜこの様なことがおこるのでしょうか?
-
step4 課題がわかったところで対応策を考える
-
課題1:
- まず日本語特有の主語を抜かした質問の聞き方が悪いですよね。例えば「警察自動車に乗った中村警部が骸骨男を見つけてから...」という質問の仕方だったらどうだったでしょうか?
- 質問の仕方を変えてみたくなりませんか。=>Queryを変更させる技術 Query Transformationsを使おう。という発想に繋がります
-
課題2:
- 関係性を正しく把握してないのではないか。関係性を正しく把握したり、リレーションをつなぎ、文脈を正しく把握する技術は何か。KnowldegeGraphを活用したGraphRAGも通常のRAGに加えてハイブリッドにして使おう。という発想になります
-
課題1:
16.2 実際にやってみます
-
- RAG FusionでオリジナルQueryをLLM自身に聞き方を変えさせて、色々な角度から質問させます。今回はオリジナル以外に2つ考えさせます
original_query="馬に乗った骸骨男を見つけてから、明智が投げ縄をするまでに縮めた差は何メートルだと考えられますか?"
query_lst =query_generator(original_query)
display(query_lst)
['0.馬に乗った骸骨男を見つけてから、明智が投げ縄をするまでに縮めた差は何メートルだと考えられますか?',
'1. 「馬に乗った骸骨男と明智の距離は、どれくらい縮まったのか?」',
'2. 「明智が投げ縄をするまでに馬に乗った骸骨男との距離を縮めた差は何メートルですか?」']
オリジナルの聞き方以外にも2つ聞き方を考えてくれました。
- 2.それぞれの質問の聞き方を、グラフDBに問い合わせてみます。実行すると、Cyperコマンドを生成して、関係性から情報を取得できます。うまく情報が取れたら、それを生成AIに関連ドキュメントとして与えればよいわけです。今回は、その様子がわかるように、簡易的に GraphCypherQAChainを使い、LLMが、Cypherコマンドを生成して、実行している様子を見てみましょう
cypher_response_lst=[]
for query in query_lst:
print(f"query:{query}")
cypher_res = cypher_chain.invoke(query)
cypher_response_lst.append(cypher_res)
print(cypher_response_lst)
query:0. 馬に乗った骸骨男を見つけてから、明智が投げ縄をするまでに縮めた差は何メートルだと考えられますか?
> Entering new GraphCypherQAChain chain...
Generate Cypher:
Full Context:
[]
> Finished_chain.
query:1. 「馬に乗った骸骨男と明智の距離は、どれくらい縮まったのか?」
> Entering new GraphCypherQAChain chain...
Generated Cypher:
cypher
MATCH (skeleton:Entity {name:"骸骨男"})-[:RIDING]->(Animal{name:"馬"}),(akechi:Person {name:"明智"}), (skelton)<-[r:SAW]-(akechi)
RETURN r.distance
Full Context:
[{'r.distance':'90メートル'},{'r.distance':'90メートル'},{'r.distance':None},{'r.distance':None},{'r.distance':None},{'r.distance':None},{'r.distance':None}]
> Finished chain.
query:2. 「明智が投げ縄をするまでに馬に乗った骸骨男との距離を縮めた差は何メートルですか?」
> Entering new GraphCypherQAChain chain...
Generated Cypher:
cypher
MATCH (a:Person {name:"明智"})-[:APPROACHED {description:"投げ縄をするまでに"}]->(b:Entity {name:'骸骨男'})-[:RIDING]-> (:Animal{name:'馬'})
RETURN b.distance AS distance
Full Context:
[]
> Finished chain.
結果.3つのうち1つだけでしたが、情報が取れたのが確認できました。2つ目の聞き方で、的確なCypherコマンドが生成され、それに対してグラフDB内部に関係性が出来ていたので、正しい答えである90メートルが導けました。次が最終的に、LLMがこの情報を使った答えです。
[
{'query':'0. 馬に乗った骸骨男を見つけてから、明智が投げ縄をするまでに縮めた差は何メートルだと考えられますか?','result':"I don't know the answer."}
{'query':'1.「馬に乗った骸骨男と明智の距離は、どれぐらい縮まったのか?」','result':'馬に乗った骸骨男と明智との距離は、90メートル縮まりました。'},
{'query':'2.「明智が投げ縄をするまでに馬に乗った骸骨男との距離を縮めた差は何メートルですか?」','result':"I don't know the answer."}
]
3行横長になって見えてませんが、右にスライドして頂ければ、2回目の聞き方が正しく90メートルと回答してくれたことがわかります。
今回、理解しやすいように便宜上、CypherQAChainで取得しましたが、逆に言えば、これでシッカリとNeo4jに、この問題に関するノード間の関係性が格納されていることがわかります。あとは、この情報をRAGのソースとしてしっかり埋め込む部分を構築すればよいわけです。
17.最後に
難問の解説でお伝えした考え方のステップは、ビジネスでも共通する部分があると思います
- 難問解決のステップは以下でした
- Step1.まずは正解を知る
- Step2.LLMを活用してみる
- Step3.課題を理解する
- Step4.解決の対応策を考える
- ビジネスに置き換えると以下になります
- Step1.の正解を知る。というのは、初手としてRAGシステムにドキュメントを組込むのではなく、まずはそのドキュメントの中身や業務を深く知るということかと思います。自社案件であれば、そのドキュメントを利用する部署がどういう目的で使うのかを正しく知る必要がありますし、お客様相手の案件であれば、その顧客先から提示いただいたドキュメントはどんな目的で利用し、何が書かれているドキュメントなのかを正しく把握するということです
- Step2.の「LLMによるRAGシステムを導入する」だけで終わらずに、
- Step3.の課題がどこにあり、
- Step4.で解決し、生成AIがビジネスの有効活用につながっていく世界
「生成AIを活用したRAGシステムを導入」がスタートではなく、「まずは業務理解や課題がどこにあるのかというアプローチからスタートする」という、この辺の考え方は、データ分析のプロセスを形式化した CRISP-DM(CRoss-Industry Standard Process for Data Mining)や、データ活用業務全般に通じるところかと思います
長くなりましたが、読了頂きありがとうございました。
また、SIGNATEの関係者の方、新しい試みで運営大変だったと思いますが、大変楽しく参加できました。ありがとうございました。
※記載されている会社名、製品名、サービス名は、各社の商標または登録商標です。
参考文献
この記事は以下の情報を参考にして執筆しました。
- 参考文献1: Medium Enhancing the Accuracy of RAG Applications With Knowledge Graphs
- 参考文献2: zenn.dev RAG Fusionを試してみる
-
リスキリングとは:経済産業省:デジタル時代の人材政策に関する検討会 第2回 開催資料2-2 石原委員プレゼンテーション資料 リスキリングとは(PDF) ↩
-
人工知能学会・セマンティックウェブとオントロジー研究会・企画委員による ナレッジグラフ推論チャレンジ (https://challenge.knowledge-graph.jp/2024/) ↩
-
アーサー・コナン・ドイル著 シャーロックホームズ まだらのひも 青空文庫 まだらのひも ↩
-
この辺は、株式会社アルファシステムズ様のBlog:話題のGraphRAGとは - 内部構造の解析と実用性の考察がとても参考になると思いますので、詳細はそちらをご覧ください。 ↩
-
RAG-Fusion: a New Take on Retrieval-Augmented Generation arXiv:2402.03367v2 [cs.IR] 21 Feb 2024 ↩ ↩2