Juliaで機械学習をする場合、Flux.jlが有名かと思います。一方で、最近では、Lux.jlというパッケージもあります。名前もよく似ていますし使い方も似ている気もしますから、この二つは一体何なのだろうか?と思った方もいるかと思います。
この記事では、Flux.jlの違いを見るとともに、Lux.jlによる関数フィッティングをやってみることにします。
まず、Flux.jlで関数フィッティングをした記事は、Juliaで機械学習:Flux.jlで自由自在にオリジナルレイヤーを組んでみよう 2023年版にありますので、Flux.jlに興味がある方はこちらを参考にしてください。
Flux.jlとLux.jlの違い
ざっくりとした違い
この二つの違いを簡単にまとめると、
- Flux.jl:機械学習パッケージ。これ一つで何でもできる。
- Lux.jl:機械学習のモデルに関するパッケージ。他のパッケージと組み合わせて学習を行う。
となります。
コンセプト的な違い
違いをよりコンセプト的に言うと、
- Flux.jl: モデルを作ると、そのモデルには学習可能なパラメータが存在している(ユーザーからパラメータが見えない)。「モデルを更新」して機械学習を行う
- Lux.jl: モデルを作ると、モデルの骨組みだけが作られ、モデルは学習可能なパラメータを持っていない。モデルにパラメータを流し込むことでモデルが値を出力する。「パラメータを更新」して機械学習を行う
という違いがあります。これは、パラメータを明示的に持っているかどうか、という違いがあります。基本的には、Lux.jlのモデルは常に変化せず、引数を変えることでモデルの出力が変わります。内部状態を持たない純粋な関数のようなものです。一方、Flux.jlはモデルに同じ引数を入れても、モデルの内部の訓練パラメータが異なっていれば異なる出力が出ます。
使い方の違い
これらの違いがどう使い方を変えるかと言いますと、
- Flux.jl: Flux.jlのデフォルトに入っている機能であれば簡単に使える。メジャーなものは何でも揃っている。パラメータを取り出して更新することも可能。基本的に何でもできる
- Lux.jl: パラメータを別に扱うことで、更新方法を他のパッケージに丸投げすることができる。例えばNeuralODEであれば、微分方程式を数値的に解くパッケージを途中に入れることでパラメータを更新することができる。他のパッケージと組み合わせやすい形になっている
実用的な違い
どちらを使ってもほとんど変わりません。あえていうならば、Lux.jlは外部に学習可能なパラメータを持つために、そのパラメータを好きな型にすることができることから、GPUと相性がいいです。その結果、CUDAの他に、AMDGPUやAppleのMetalアーキテクチャや、IntelOneAPIにまで対応しています。そして、その対応状況は外部パッケージの対応状況に依存していますから、Lux.jlが煩雑化しないと言う利点があります。
Lux.jlで機械学習をするには
外部パッケージが重要となりまして、
- パラメータ最適化:Optimisers.jlなど
- データローダ:MLUtils.jlなど
- 自動微分:Zygote.jlなど
- 乱数生成:Random.jlなど
を使います。もちろん、それ以外を使うことも可能です。
バージョン
- Julia 1.10.5
- Lux v1.1.0
コード例:関数フィッティング
Juliaで機械学習:Flux.jlで自由自在にオリジナルレイヤーを組んでみよう 2023年版と同じようなことをします。こちらの記事を見てください。
対象とする問題
何か具体的な問題を通じて考えた方がわかりやすいと思いますので、今回もこれまでと同様に関数をフィッティングすることにします。MNISTなどがやりたい場合は適宜インプットとアウトプットを読み替えてください。
考える式は、インプットをx,yとして
f(x,y) = xy + \cos(3x)+xe^{y/5} + \tanh(y) \cos(3y)
とします。2次元平面上での値を出す関数ですね。
これは
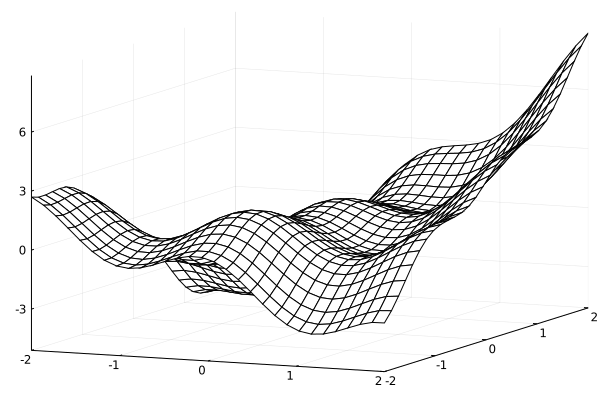
こんな感じになります。
この関数をフィッティングしてみましょう。
コード
using Plots
using MLUtils
using Lux
#using Metal
#using CUDA
using Optimisers
using Random
using Zygote
const loss_function = MSELoss()
const dev_cpu = cpu_device()
const dev_gpu = gpu_device()
function make_data(f, num)
#num = 47
#numt = 19
x = range(-2, 2, length=num)
y = range(-2, 2, length=num)
count = 0
z = Float32[]
for i = 1:num
for j = 1:num
count += 1
push!(z, f(x[i], y[j]))
end
end
return x, y, z
end
function make_inputoutput(x, y, z)
count = 0
numx = length(x)
numy = length(y)
input = zeros(Float64, 2, numx * numy)
output = zeros(Float64, 1, numx * numy)
count = 0
for i = 1:numx
for j = 1:numy
count += 1
input[1, count] = x[i]
input[2, count] = y[j]
output[1, count] = z[count]
end
end
return input, output
end
function training!(tstate, train_loader, test_loader, vjp_rule, epochs)
for epoch in 1:epochs
for (x, y) in train_loader
data = (x, y) |> gpu_device()
_, loss, _, tstate = Training.single_train_step!(vjp_rule, loss_function, data, tstate)
end
if epoch % 50 == 1 || epoch == epochs
loss = 0.0
for (x, y) in test_loader
y = y |> dev_gpu
x = x |> dev_gpu
y_pred = Lux.apply(tstate.model, x, tstate.parameters, tstate.states)[1]
loss += loss_function(y_pred, y)
end
loss = loss / length(test_loader)
println("Epoch: $epoch \t Loss: $loss")
end
end
end
function main()
num = 30
x = range(-2, 2, length=num)
y = range(-2, 2, length=num)
f(x, y) = x * y + cos(3 * x) + exp(y / 5) * x + tanh(y) * cos(3 * y)
z = [f(i, j) for i in x, j in y]'
p = plot(x, y, z, st=:wireframe, zlims=(-2, 8))
savefig("original.png")
xdata, ydata, zdata = make_data(f, num)
input_data, output_data = make_inputoutput(xdata, ydata, zdata)
numtrain = 47
xtrain, ytrain, ztrain = make_data(f, numtrain)
numtest = 19
xtest, ytest, ztest = make_data(f, numtest)
input_train, output_train = make_inputoutput(xtrain, ytrain, ztrain)
#display(output_train)
input_test, output_test = make_inputoutput(xtest, ytest, ztest)
batchsize = 128
train_loader = DataLoader((input_train, output_train), batchsize=batchsize, shuffle=true) #MLUtils
test_loader = DataLoader((input_test, output_test), batchsize=1, shuffle=false) #MLUtils
for (x, y) in train_loader
#display(x)
#display(y)
end
model = Chain(Dense(2, 10, relu), Dense(10, 10, relu), Dense(10, 10, relu), Dense(10, 1))
display(model)
opt = Adam() #Optimisers.jl
display(opt)
rng = MersenneTwister() #Random
Random.seed!(rng, 12345)
ps, st = Lux.setup(rng, model) |> dev_gpu
#display(ps)
#display(st)
tstate = Training.TrainState(model, ps, st, opt)
display(tstate)
loss = 0.0
for (x, y) in test_loader
y = y |> dev_gpu
x = x |> dev_gpu
y_pred = Lux.apply(tstate.model, x, tstate.parameters, tstate.states)[1]
#display(y)
#display(y_pred)
loss += loss_function(y_pred, y)
end
println(length(test_loader))
println("initial loss $(loss/length(test_loader))")
vjp_rule = AutoZygote()
epochs = 1000
@time training!(tstate, train_loader, test_loader, vjp_rule, epochs)
output_pred = dev_cpu(Lux.apply(tstate.model, dev_gpu(input_data), tstate.parameters, tstate.states)[1])
z_pred = reshape(output_pred, num, num)
#display(y_pred)
p = plot(x, y, z_pred, st=:wireframe, zlims=(-2, 8))
savefig("dense.png")
end
main()
コードのポイント
DataLoaderはMLUtilsのもの、AdamはOptimisersのもの、乱数rng = MersenneTwister() はRandomのもの、vjp_rule = AutoZygote()はZygoteのもの、をそれぞれ使っています。
学習中には、
- model
- parameters
- state
が重要です。
訓練パラメータは
ps, st = Lux.setup(rng, model) |> dev_gpu
で定義していまして、
model = Chain(Dense(2, 10, relu), Dense(10, 10, relu), Dense(10, 10, relu), Dense(10, 1))
のモデルの定義の部分では行なっていません。これを見ればわかりますように、パラメータpsとstatestがGPUに転送されています(実際に実行するとGPUに対応していなければCPUを使いますが)。
インプットとパラメータと状態をGPUに転送すれば、アウトプットはGPU上で出力されることになります。
もう少し複雑なモデルの作り方については、今後もう少しよく分かったら別の記事にまとめることにします。