概要
Ansibleを学習するのにあたっての勉強メモをかねています
書籍「Asinble徹底入門」と実践した中で学んだことを併せて記録します
動作環境は、先日投稿した「Docker内でAnsibleの勉強をしよう」で実施しています
現在は自社Saasで実践的に利用しています。先日Ansibleユーザ会で「自社クラウドサービスをAnsibleで作った話 recap」を公開したので、参考になれば幸いです
Ansibleの特徴
- Python製
- 非エージェント型の構成管理ツール
- プラットフォーム問わずに利用できる(Linux、Windows、Docker、Iaas、ベアメタル、ネットワーク機器、HWベンダーのマネージド機器)
- yml、jsonで構成定義ファイル(Playbook)を書けるため、学習コストが低い
- Red Hat社がメインで開発しているOSS
Red Hatがバックについているので、長期的な開発が見込める
各ベンダーを巻き込んだ取り組みをしていることもあり、対応プラットフォームが多い - NASA、NEC、HP、Juniper、CISCO、EA、CocaColaなど名だたる大企業が使っている
呼び名の整理
- Ansible Core ・・・ Ansibleの本体部分
- Ansible Tower ・・・ Red Hat社が提供するWeb GUIベースのAnsible管理ツール(AWXの特定のバージョンから切り出したバージョン)
- Ansible Engine ・・・ Red Hat社がエンタープライズ向けに有償保証を加えた商品(コアモジュールも保証対象)
- AWX ・・・ Ansible Towerの開発版でApache v2ライセンスで運用されている
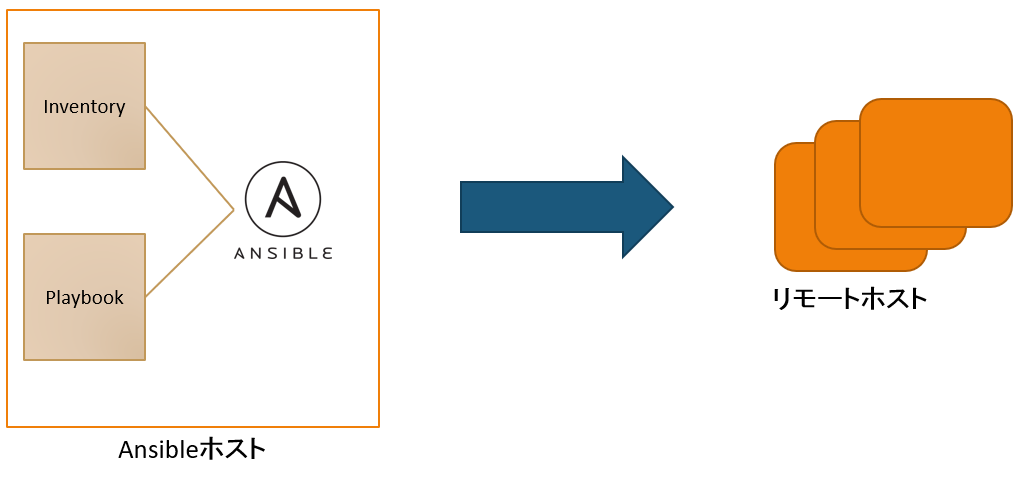
Ansibleの構成要素
- Ansible本体
- Inventory ・・・ 操作対象のマシン(ホスト)の管理ファイル
- Module ・・・ 操作対象のマシンを操作する
- コアモジュールと有志モジュールが多数(13000?)
- 自作モジュールも簡単に作れる
- Playbook ・・・ どのInventoryにどのModuleでどのように操作するかを定義する定義ファイル(手順書)
実行イメージ
YAMLファイル
YAMLファイルの書式
- 先頭行は
---で開始すること(任意) - インデントは半角スペース2つ
- コメントは
#
---
hoge
fuga
わかりやすいスライド
Ansible設定
Ansibleの動作設定を定義するための設定ファイル
優先順位
- ANSIBLE_CONFIG環境変数 (v1.5以前は2番目)
- カレントディレクトリ(Playbook)のansible.cfg (v1.5以前は1番目)
- ~/.ansible.cfg
- /etc/ansible/ansible.cfg
hostチェックをしない
新しいホストに接続する際に、該当のホストを受け入れるかの質問をしないようにする
host_key_checking=False
変数のマージ
同名の変数があった場合は、変数をそのまま上書きするのではなく、
存在しないプロパティ値をマージする
hash_behaviour=merge
リトライファイルの出力をしないようにする
実行時失敗時に生成されるxxxx.retryファイルを生成しないようにする
retry_files_enabled=False
実行ログの出力
コンソールに表示された実行ログをログファイルに出力
log_path=path/to/xxxx.log
実行時デバックモード
タスクの実行エラー時に、デバック画面に移行する
strategy=debug
タスクの実行時間の表示
callback_whitelist=profile_tasks
SSH接続のリトライ
ssh接続試行時間(デフォルトで10s)はtimeout値に依存します
[ssh_connection]
retries=3
Inventory
- Inventory(静的)
- INI形式、YAML形式でホスト情報を記述
- ホストの接続情報があらかじめわかっている
- Dynamic Inventory(動的)
- ホスト情報をjsonに出力するスクリプト
- ansibleコマンド実行時にリアルタイムでスクリプトが実行される
- スクリプト経由で動的にホスト情報を取得できる
Inventoryファイル(静的)
書式(INI形式)
[app]
app1 ansible_host=xxxx.app1.com
app2 ansible_host=xxxx.app2.com
[db]
db1 ansible_host=xxxx.db1.com
db2 ansible_host=xxxx.db2.com
[app:vars]
admin_username=app_user
admin_uid=1001
[db:vars]
admin_username=db_user
admin_uid=1002
[pod1]
app1
db1
[pod2]
app2
db2
- グループごとに
[グループ名]セクションで区切る - グループごとに変数を定義する場合は、
[グループ名:vars]セクションを用いる(外部ファイル化も可能(後述))
グループ変数 < ホスト変数でホスト変数優先、グループ変数が重複した場合は後優先 - 真偽値は**大文字開始(True/False)**であること
小文字の場合は文字列として扱われる - リストや辞書構造は扱えない
- 複数のグループに所属することができる
- ホスト名が同じ場合は、同一ホストとして扱われる
IP範囲指定
172.17.12.0~172.17.12.255まで一括指定
[myhosts]
172.17.12.[0:255]
グループごとにssh鍵やユーザの設定
例)AWS EC2
[aws:vars]
ansible_user=ec2-user
ansible_ssh_private_key_file=~/.ssh/hogehoge.pem
Dynamic Inventory Script(動的)
システム連携で動的に操作対象のホストが変わるようなシーンで使う
scriptによって生成されたinventoryに各種操作を行う
scriptはpython、javascript、php、javaと開発言語問わず、dynamic inventoryとして認識できるjsonを返せばOK
実行方法(例)
inventory.jsのようにプログラム内でinventoryを定義したjsonを返す
サンプルはjsになっていますが、python, php, shellscriptでもOK
> ansible-playbook -i inventory.js playbook.yml
# !/usr/bin/node
// ↑はnodejsの実行パスに適宜変更してください
console.log(dynamicHosts());
function dynamicHosts() {
const inventory = {};
const hosts = ['12.345.67.890']; // instance ip
const vars = {
'var1': True,
'ansible_ssh_private_key_file': '/root/.ssh/hogehoge.pem', // ssh鍵の個別指定
'ansible_ssh_user': 'hogehoge-user' // sshユーザの個別指定
};
inventory['groupname'] = {
'hosts': hosts,
'vars': vars
}
return JSON.stringify(inventory);
}
---
- name: Test dynamic inventory
become: true
hosts: "groupname"
tasks:
- name: echo debug
debug: var='test'
参考
-
jsonファイルのフォーマットはこちら参照
フィルター
json_query
数字条件でフィルターリングする際にバッククオートで数字を囲むこと!
https://jmespath.org/specification.html#filter-expressions
一致する文字列(数値)を抽出する
数値が文字列か数値によって、json_queryの記法が変わります。
数値の文字列の場合は、シングルクオーテーションで囲むこと!
クエリ変数に代入必須であること!
- debug:
msg: "{{ my_var | json_query(q_string) }}"
vars:
q_string: "[?hoge=='100']"
my_var:
- hoge: "100"
- hoge: "200"
- hoge: "0"
一致する数値を抽出する
数値の場合は、バッククォートで囲むこと!
また、クエリを変数に代入せずにそのまま指定することも可能
- debug:
msg: "{{ my_var | json_query(q_string) }}"
vars:
q_string: "[?hoge==`100`]"
my_var:
- hoge: 100
- hoge: 200
- hoge: 0
- debug:
msg: "{{ my_var | json_query([?hoge==`100`]) }}"
vars:
my_var:
- hoge: 100
- hoge: 200
- hoge: 0
Playbook
基本構成
---
- name: play book
hosts: all
tasks:
- name: <task name>
<module name>:
<module arg1>: <arg1 value>
<module arg2>: <arg2 value>
実行方法
> ansible-playbook -v path/to/playbook.yml
※ -vで実行内容の表示
タスクの基本構成
~ 中略 ~
tasks:
- name: <task name>
<module name>:
<module arg1>: <arg1 value>
<module arg2>: <arg2 value>
例)
tasks:
- name: install nginx
yum:
name: nginx
state: present
または(簡略化する書式)
tasks:
- name: install nginx
yum: name=nginx state=present
管理しやすいように構成しましょう
- 各タスクに
nameを付与することで実行履歴で追いやすくなります! -
whenやloopなどはタスク内のどこでも定義できる
# サンプルコードでよくある構成
- name: debug code
debug:
msg: "debug"
when: item
loop:
- True
- False
- True
- True
# 管理しやすいように変更してもOK
# 順番は問わず
- name: debug code
when: item
loop:
- True
- False
- True
- True
debug:
msg: "debug"
操作対象のホストから情報収集しない場合
gater_facts: false
管理者権限で実行
become: true
# v1.9未満
sudo: yes
ユーザ指定実行
become_user: xxxxx
# v1.9未満
sudo_user: xxxxx
アトリビュート
リトライ処理(retries)
Webサーバの立ち上げ&死活確認する場合は、retriesを用いる
untilの条件になるまで指定されたretries数を実行する
実行間隔はdelay
- name: wait app is available
uri:
url: "https://qiita.com"
method: "GET"
register: _response_result
until: _response_result.status == 200
retries: 5
delay: 30
出力ログにパスワードを非表示にする(no_log)
> - name: secret task
shell: /usr/bin/do_something --value={{ secret_value }}
no_log: True
他のホストの変数を設定する(delegate_to)
[Ansible] 他のホスト変数を参照、設定する(hostvars、delegate_to/delegate_facts)
モジュール
ビルドインのモジュール一覧はこちらです
同じモジュールを繰り返し利用する際にパラメータを共通化する(module_defaults)
以下の様に予めregionを一か所で指定することで、tasksのec2ではregionの指定を省略することができる
- hosts: localhost
vars:
my_region: us-west-2
module_defaults:
ec2:
region: '{{ my_region }}'
ec2_instance_info:
region: '{{ my_region }}'
ec2_vpc_net_info:
region: '{{ my_region }}'
tasks:
ec2:
yumパッケージのインストール(yum)
- name: remove the Apache package
yum:
name: httpd
state: present
stateの状態名が過去分詞になっている
インストール済み状態であることを確認するであって、インストールするではない
すでにインストール済みの場合は実行せずに処理が進む(冪等性)
- present
- latest
- absent
複数のパッケージを同時インストール(カンマ区切り v2.x)
- name: install the Apache, nginx, tomcat package
yum:
name: httpd,nginx,tomcat
state: present
複数のパッケージを同時インストール(with_items)
- name: install the Apache, nginx, tomcat package
yum:
name: "{{ item }}"
state: present
with_items:
- httpd
- nginx
- tomcat
ファイル操作(copy)
- name: deploy web contents
copy:
src: ./www/site-a/index.html
dest: /usr/share/nginx/html/site-a/index.html
※大量ファイルをコピーしたい場合はsynchronizeモジュールを使おう
双方にrsyncがインストールされていることが必要
コピー先のファイルを上書きしないようにする
copy:
force: false
コピー先のファイルを上書きせずに古いファイルをBKする
copy:
backup: true
※etc/xxx.d/のように自動でファイル読み込みする場合は、古いファイルも読み込まれるので要注意
リモート内でのファイル操作(ver2.x)
copy:
remote_src: yes
行単位でのファイル編集(lineinfile)
- name: edit sshd config(deny root user login with password)
lineinfile:
dest: /etc/ssh/sshd_config
regexp: '^PermitRootLogin\s+'
line: PermitRootLogin without-password
validate: ssh -t -f %s
※ %sで一時ファイルに対してバリデーションする
任意コマンドを実行(command)
- name: make ssh key in tmp dir
command: "/usr/bin/ssh-keygen -b 2048 -t rsa -N '' -f /tmp/new-id_rsa"
args:
creates: /tmp/new-id_rsa
- name: echo home env
command: "echo {{ ansible_env.HOME | quote}}"
※ パイプ、リダイレクト(<, >)が使えない(shellモジュールでは使えるが推奨されていない)
※ $記号を使った環境変数を使えない
※ 変数を扱う場合は、quiteフィルターでサニタイズすること
Python未対応の環境でコマンド実行(raw)
- name: yum install python-simplejson in raw env
raw: yum install -y python-simplejson
※pythonを載せられない環境
※2.4~2.6未満のpythonの環境(simplejsonのみをインストール)
処理中に動的にInventoryに新規ホストを追加(add_host)
※add_hostした次のplayから操作が適用される
- name: add new host to Inventory
add_host:
name: created-host
groups: created,app
ansible_host: "{{ created_host_ip }}"
ansible_port: 22
serviceの管理(service)
- name: start nginx service
service:
name: nginx
state: started
enabled: true
動的にホストをグループ分け(group_by)
登録済みホストを新たにグループ分け
※Ansibleではグループ名にスペースを使えないため、-に変換される
- name: group by OS family
group_by:
key: "{{ ansible_os_family }}"
- name: Red Hat play
hosts: Red Hat
- name: Debian play
hosts: Debian
リモート先での実行結果を表示する(debug/register)
registerに一度出力結果を代入して、debugモジュールでregisterの内容を出力
- name: echo remote stdout
command: echo $PATH
register: remote_path
- name: echo remote path
debug: var=remote_path.stdout
ファイルまたはファイルシステムのステータスを取得する(stat)
ファイルの所有権の有無を確認し、権限がない場合は、failモジュールでエラー表示
- name: check foo.conf exist
stat:
path: /etc/foo.conf
register: st
- fail:
msg: "Whoops! file ownership has changed"
when: st.stat.pw_name != 'root'
条件に応じて実行(when)
whenの条件を満たした場合は、タスクを実行する
リスト形式の場合は、AND条件として認識される
MODE == 'product' OR ansible_os_family == 'RedHat' でOR条件になる
vars:
MODE: product
~ 中略 ~
- name: deploy Web contents for product page
copy:
src: ./www/site-a/product.html
dest: /usr/share/nginx/html/site-a/product.html
when:
- MODE == 'product’
- ansible_os_family == 'RedHat'
特定の文字が含まれている場合に実行(match)
url変数に「http://example.com/users/.*/resources/.*」が含まれている場合に実行
- debug:
msg: "matched pattern 1"
when: url is match("http://example.com/users/.*/resources/.*")
対話形式の自動入力
同一の質問が複数あった場合の書き方
長時間の処理に対応する
asyncとpollディレクティブを使用する
- name: 最大45秒の処理を5秒ずつポーリングする
command: /bin/sleep 15
async: 45
poll: 5
特定のホストが接続できるまで待機するwait_for
例えばEC2を生成後にそのインスタンスに対して初期設定などをしたい時に、接続可能になるまで待機する時に用います
- name: create new EC2 instance
hosts: local
gather_facts: False
tasks:
- name: create new instance
ec2:
~中略~
register: _instance_result
# 新しいインスタンスを後続の処理で対象ホストとして設定する
- name: set new host
add_host:
name: "{{ item.public_ip }}"
group: new_host
with_items: "{{ _instance_result.instances }}"
# 22ポートが接続可能になるまで待機(最大待ち時間はtimeout)
- name: wait new instance is available
wait_for:
timeout: 600
host: "{{ item.public_ip }}"
port: 22
state: present
with_items: "{{ _instance_result.instances }}"
# 新しいホストでの処理
- name: setup os in new instance
hosts: new_host
# 接続ユーザと鍵を変える場合
vars:
ansible_user: "ec2-user"
ansible_ssh_private_key_file: "/root/.ssh/hogehoge.pem"
tasks:
- name: update to latest packages
yum:
name: "*"
state: latest
become: True
OS再起動
OSを再起動する際に、処理が終了しないようにする
sleep、async:1、poll:0、local_actionでwait_forがポイント!
sleepがないと即座にシャットダウンプロセスに入るため、接続断と見なされてしまう
async1、poll:0で非同期処理としてこのshellモジュールの結果を待たずに次の処理に進みます
リモートが再起動処理中のため、実行元をローカル(local_action)に移し、22ポートが返ってくるまで待つ
- name: Reboot OS
shell: "sleep 2 && reboot"
args:
executable: /bin/bash
async: 1
poll: 0
become: yes
- name: Wait for rebooted
local_action:
module: wait_for
host: "{{ inventory_hostname }}"
port: 22
delay: 30
※上記よりもrebootモジュールが安定していますので、そちらをご利用ください、ただし、Ansibleのバージョンに注意!
アーカイブarchive
指定したディレクトリをアーカイブしてくれます。
ただし、ディレクトリの除外設定(exclude_path)で以下のような罠があるので要注意です!
例えば以下のようなディレクトリがあります。
roles/gcpをアーカイブの除外対象にします。
roles
|-- aws
| |-- tasks
| | `-- main.yml
| `-- templates
| `-- hoge.j2.yml
|-- gcp
| |-- tasks
| | `-- main.yml
| `-- templates
| `-- hoge.j2.yml
`-- common
|-- tasks
| `-- main.yml
`-- templates
`-- hoge.j2.yml
pathで除外したいディレクトリの親ディレクトリに「*」を追加すること
※ファイルの場合はこのような設定は不要
- name: Archive exclude gcp role
archive:
path:
- roles/*
exclude_path:
- roles/gcp
以下のようにネストしたディレクトリは除外できないようです
# NGその1
- name: Archive exclude aws templates
archive:
path:
- roles/*
exclude_path:
- roles/aws/templates
# NGその2
- name: Archive exclude aws templates
archive:
path:
- roles/*
- roles/aws/*
exclude_path:
- roles/aws/templates
変数
Jinja2というPythonのテンプレートエンジンを用いて変数展開している
- 通常変数・・・人が決める変数
-
Facts・・・ホストの状態に応じて自動的に値が決まる変数
- モジュールが自動取得するもの
playbook内で使用するための変数はいくつかの手段で定義することができる
定義方法によって適用の優先順位がある
優先順位をうまく活用することで、より柔軟な運用を実現することができる
※参考・・・これだけ覚えとけばもう怖くないAnsibleの(動的)変数
Facts変数
定義済みのansible変数
例)
- ansible_os_family : OSのファミリー情報(CentOS、RedHat)
- ansible_distribution_major_version : OSのメジャーバージョン情報
- ansible_ssh_user : ssh接続ユーザ
- ansible_ssh_host : sshホスト
OSのパッケージマネージャー
ansible_pkg_mgr ・・・ 複数のパッケージマネージャーが共存する環境で明示的に特定のパッケージマネージャーを指定したい時にこの変数を上書きする
ファイル名規則と定義方法
Inventory用の変数をyamlファイルに切り出せる
- ホスト変数定義ファイル(host_vars/<host名>.yml)
- グループ変数定義ファイル
- group_vars/<group名>.yml
- group_vars/<group名>/hogehoge.yml(ファイル名の昇順で上書きされる)
- InventoryファイルまたはPlaybookファイルと同じ場所に配置(ファイル名規則に依存しない)
- playbook実行時のコマンドで変数ファイルの読み込みを行う(ファイル名規則に依存しない)
- inventory内で変数を直接定義(ファイル名規則に依存しない)
- playbook内で変数を直接定義(ファイル名規則に依存しない)
- playbookからの変数ファイルの読み込み(ファイル名規則に依存しない)
inventoryフォルダ/playbookフォルダ
|
|-----hosts/playbook
|
|------group_vars
| |----all.yml(全体に適用できる)
| |----グループ名(グループごとに変数ファイルを分割できる)
| |---0_first.yml
| |---1_second.yml
| |----app.yml
| |----db.yml
|
|------host_vars
|----app1.yml
|----db1.yml
|----app2.yml
|----db2.yml
変数として展開してほしくない時
以下の様にdocker inspectのフィルタ文字列を変数として使ってほしくない時は{%raw%}{%endraw%}で囲む
https://docs.ansible.com/ansible/latest/user_guide/playbooks_advanced_syntax.html
# .LogPathは変数として扱われるのでエラーになる
- command: docker inspect --format='{{.LogPath}}' $INSTANCE_ID
# .LogPathは変数として扱われない
- command: docker inspect --format='{%raw%}{{.LogPath}}{%endraw%}' $INSTANCE_ID
Ansible実行時に定義
値はすべて文字列として扱われるため、真偽値、数値には注意
> ansible-playbook -e 'key1=value key2=value' xxx.yml
値を適切な型として扱えるようにするために、json形式で定義
> ansible-playbook -e '{"key1": True, "key2": 100}' xxx.yml
外部ファイル(YAMLファイル)から読み込み
> ansible-playbook -e '@var-file.yml' xxx.yml
Playbook内で定義
PlayとTask内で直接変数を指定する
PlayまたはTask内のみで有効
---
- name: set vars
hosts: all
vars:
key1: value
key2: value
外部ファイルから読み込み
Play内のみ利用可能
---
- name: set vars
hosts: all
vars_files:
- xxx_vars1.yml
- xxx_vars2.yml
List変数のマージ
二つのlist型変数をマージする
- set_fact:
list1: [ "a", "b", "c" ]
list2: [ "e", "f", "g" ]
- set_fact:
list_all: "{{ list1 }} + {{ list2 }}"
変数をList変数に追加
- set_fact:
var1: "a"
list2: [ "e", "f", "g" ]
- set_fact:
list_all: "[ '{{ var1 }}' ] + {{ list2 }}"
List変数にdict変数を追加
ポイントは_listを配列定義後にもう一度同じ_list変数を定義&dict値の追加を行う
- set_fact:
_data:
- "1"
- "2"
- "3"
- set_fact:
_list: []
- set_fact:
_list: "{{ _list + [{ 'att1': item, 'attr2': 2 }] }}"
with_items: "{{ _data }}"
--------- result ---------
{
"attr1": "1",
"attr2": 2
},{
"attr1": "2",
"attr2": 2
},{
"attr1": "3",
"attr2": 2
}
dictから値を抽出したlistを作る
.values()でdictの値をlistで抽出することができる
- set_fact:
_data:
a: 1
b: 2
c: 3
- set_fact:
_list: "{{ _data.values() }}"
- debug: msg=_list
--------- result ---------
"msg": [
"1",
"2",
"3"
]
List in ListのLoop(json_query)
List内にあるListの値をループしながら取得したい時にjson_queryフィルターを用いると便利
それ以外で変数からデータを抽出したい時にもかなり便利
# サンプル変数
- set_fact:
test:
results:
- stdout_lines:
- "val1"
- "val2"
p: yes
- stdout_lines:
- "val3"
- "val4"
p: no
# results配列内のstdout_lines配列の値を順に取得する
- debug:
msg: "{{ item }}"
with_items: "{{ test.results | json_query('[*].stdout_lines') }}"
ok: [app1] => (item=None) => {
"msg": "val1"
}
ok: [app1] => (item=None) => {
"msg": "val2"
}
ok: [app1] => (item=None) => {
"msg": "val3"
}
ok: [app1] => (item=None) => {
"msg": "val4"
}
Listから特定の文字列を抽出
特定の値を抽出して、新たな配列を作成
match対象の文字列に変数は使えないのか?
- set_fact:
list:
- "val1"
- "val2"
- "val3"
- "val4"
- debug:
msg: "{{ list | select('match', 'val1') | list }}"
# 取得結果をlistに代入している
ok: [localhost] => {
"msg": [
"val1"
]
}
重複値があるListから一意値のListを抽出
uniqueフィルタを使用することでListから一意の値のみのListを抽出
- set_fact:
_list: ['1', '2', '2', '3']
- debug:
msg: "{{ _list | unique }}"
TASK [debug] *********************************
ok: [localhost] => {
"msg": [
"1",
"2",
"3"
]
}
文字列の任意のインデックスから文字を切り出す
# 先頭から1文字を取得
- debug:
msg: "{{ 'hello qiita'[0] }}"
ok: [localhost] => {
"msg": "h"
}
# 末尾から1文字を取得
- debug:
msg: "{{ 'hello qiita'[-1] }}"
ok: [localhost] => {
"msg": "a"
}
配列ではなく、要素数でループする(with_sequence)
配列でループするのではなく、要素数でループするときはwith_sequenceを用いる
- debug:
msg: "{{ item }}"
with_sequence: start=0 end=4
#####################################
ok: [localhost] => (item=0) => {
"msg": "0"
}
ok: [localhost] => (item=1) => {
"msg": "1"
}
ok: [localhost] => (item=2) => {
"msg": "2"
}
ok: [localhost] => (item=3) => {
"msg": "3"
}
ok: [localhost] => (item=4) => {
"msg": "4"
}
パスワード変数(Vault)
パスワードを生の状態で保管したくないので、暗号化して読み込む時に複合する
https://qiita.com/takuya599/items/2420fb286318c4279a02
変数ファイルの暗号化
鍵ファイルを用いた暗号化
> ansible-vault --vault-password-file=path/to/key encrypt path/to/var.yml
変数ファイルの復号化
> ansible-vault --vault-password-file=path/to/key decrypt path/to/var.yml
時刻関連
現在時刻の取得
- debug: msg="{{ lookup('pipe', 'date +%Y-%m-%dT%H:%M:%S') }}"
時刻の加減算
時間の加減算をする
https://dateparser.readthedocs.io/en/latest/
# 9時間を足す(9 hour)
- debug: msg="{{ lookup('pipe', 'date -d \"9 hour \" +%Y-%m-%dT%H:%M:%S') }}"
# 9時間を引く(9 hour ago)
- debug: msg="{{ lookup('pipe', 'date -d \"9 hour ago\" +%Y-%m-%dT%H:%M:%S') }}"
jinjaテンプレート内で変数値の生成
複雑な条件分岐で変数を生成したい時に、jinjaテンプレートで変数の値を生成することができます
ポイントは**{%-と-%}**です
-がないと変数ではなく、文字列として出力されますので、ご注意!
テンプレートで値の代入をする際は、必ずset 変数名が必要になります
そのため、下記のように例えば既存の変数を更新するような場合は、dummyのようにsetして値を更新します
- set_fact:
test: >-
{%- set qiita = {"test": "qiita"} -%}
{%- set dummy = qiita.update({"test": "qiita.com"}) -%}
{{ qiita }}
- name: test debug
debug: msg="{{ test }}"
ok: [localhost] => {
"msg": {
"test": "qiita.com"
}
}
jinjaテンプレート内で変数で無駄な空白や改行文字を防ぐ
jinjaテンプレート内で条件分岐などして変数を抽出する際に、
値に無駄な空白や改行文字が含まれるのを防ぐために**{%- hogehoge -%}**で囲むことで解決されます
今までif文を一行にまとめて書いていたが、これを活用することで複数行で書けるようになり、可読性も高くなる
# Bad!!
- set_fact:
_test: >-
{% if true %}
Stop
{% endif %}
- debug:
msg: "{{ _test}}"
ok: [localhost] => {
"msg": " Stop\n"
}
# Good!!
- set_fact:
_test: >-
{%- if true -%}
Stop
{%- endif -%}
- debug:
msg: "{{ _test}}"
ok: [localhost] => {
"msg": "Stop"
}
ホスト関連の変数
特定のホスト名やインベントリ名に応じて処理の可否を制御する時に役に立ちます
- インベントリで指定したホスト名を取得する・・・
inventory_hostname - 処理中のホスト名を取得する・・・
ansible_hostname - 処理中のホストIPを取得する・・・
ansible_host - 処理中のホストグループ名を取得する・・・処理中のホストグループ名を取得できないが、処理中のすべてのホストグループは
group_names
優先順位(公式)
- コマンド実行時に
-eパラメーター - set_fact、registerの値
- include_vars
- include paramsの変数
- Roleとinclude_roleのパラメータ
- Task内の変数
- Block内の変数
- Roleのvars内変数定義ファイル/inclue_varsモジュールで読み込んだ変数定義ファイル
- Play内のvars_filesで読み込んだ変数
- Play内のvars_promptで入力した変数
- Playのvarsの変数
- HostのFact情報
- Playbookディレクトリ内のhost_varsのホスト変数
- Inventoryディレクトリ内のhost_varsのホスト変数
- Inventoryファイル内のホスト変数
- Playbookディレクトリ内のgroup_varsのグループ変数
- Inventoryディレクトリ内のgroup_varsのグループ変数
- Playbookディレクトリ内のall変数
- Inventoryディレクトリ内のall変数
- Inventoryファイル内のグループ変数
- Roleのdefaults内のデフォルト変数定義ファイル
おすすめ優先順位
初めは優先順位の低い形式で定義し、運用を重ねた上で上位の優先順位を適用することでメンテコストを軽減することができる
変数の使い方
{{ key_name }} + **"(ダブルクオート)**で囲む必要がある
---
- name: set vars
hosts: all
vars:
key1: value1
tasks:
- name: set vars
debug:
msg: "vars is {{ key1 }} "
階層構造になっている場合は、ドット繋ぎまたは['キー名']
Key:
subkey1: value
subkey2: value
tasks:
- name: set vars
debug:
msg: "vars is {{ Key.subkey1 }} "
または
debug:
msg: "vars is {{ Key['subkey1'] }} "
階層構造が同じ変数があった場合は、優先順位で上書きされるが、
ansible.cfgでhash_behaviour = mergeと設定することで、値が自動的にマージされる
http://docs.ansible.com/ansible/latest/intro_configuration.html#hash-behaviour
分岐条件(if)
{% endif %}で終了すること
ダブルクオートを忘れずに!
vars:
os: "{% if ansible_os_family == 'RedHat' %}"redhat"{% elif ansible_os_family == 'Debian' %}"debian"{% else %}"other"{% endif %}"
タスクの実行結果に応じて変数値を更新する場合(set_fact)
- name: set var
set_fact:
is_exist: False
- name: check file exist
stat:
path: /var/lib/pgsql92/data/PG_VERSION
register: pg_stat
- name: update exist flag
set_fact:
is_exist: True
when: pg_stat.stat.exists
項目の無視(omit)
パラメータが未定義の時にモジュールの項目を無視する
- name: touch files with an optional mode
file:
dest: {{item.path}}
state: touch
mode: {{ item.mode | default(omit) }}
パスワードファイル(変数)の暗号化
Role
Playを機能単位に分割し、再利用しやすくするための仕組み
Roleの生成
以下のコマンドnginx roleが生成される
※コマンドによる生成でなく、手動で作成しても問題ない
> ansible-galaxy init --init-path="roles" nginx
このようなディレクトリとファイルが生成される
playbook
|
|----xxxx.yml
|----roles
|----nginx
|----defaults(Role内で使う変数のデフォルト値定義)
|----files(対象ホストにコピーするファイル配置用)
|----handlers(ハンドラーとして使用するタスクの定義)
|----meta(Roleの依存関係の定義)
|----tasks(Roleで実行するタスク)
| |----main.yml(メインのtaskファイル)
|----templates(対象ホストに展開するJinja2テンプレート)
|----tests(Roleをテストするための定義)
| |----xxx.yml(テスト用のplaybook)
| |----inventory(テスト用のinventory)
|----vars(Role内で使う変数)
roleをグローバルに使いたい場合は
- /etc/ansible/rolesに配置する
- 設定ファイルの[defaults]ブロックにroles_pathで指定
- 環境変数ANSIBLE_ROLES_PATHで指定
※Role間での変数の共有は変数の優先順位
playbookをroleに分割するイメージ
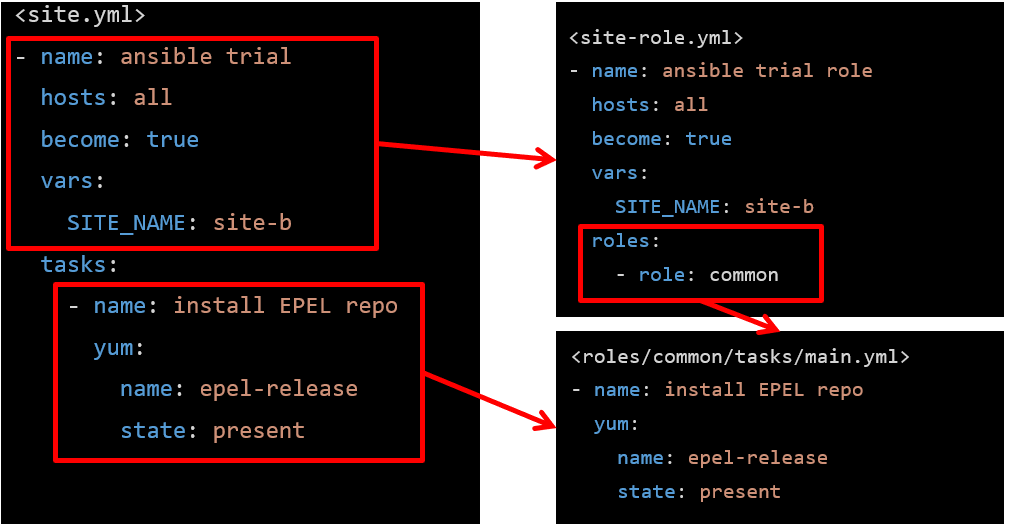
ロール内のtasksの分割
roles/hogehoge/tasks/main.ymlにすべてのタスクを詰め込めずに再利用性と可読性を高めるためにimport_tasks or include_tasksを用いて分割することができる(importは静的、includeは動的)
---
- import_tasks: install.yml
- import_tasks: after_install.yml
---
- yum: name=vi state=present
---
- debug: var=after
※Role内のinclude_tasks先でfilesやtemplatesからファイル展開しても問題なく相対パスを参照してくれる!
tasksとrolesの実行順序
playbook内でtasksとrolesが混在している場合は、基本的にrolesの後にtasksが実行される
事前に実行したい場合は、 pre_tasksを用いること
tasks内で include_role を用いることで、taskの途中から他のroleを実行できる(Ansible v2.4~)
条件に応じてroleを実行
---
- hosts: all
roles:
- { role: some_role, when: "ansible_os_family == 'RedHat'" }
or
- hosts: all
tasks:
- include_role:
name: some_role
when: "ansible_os_family == 'RedHat'"
Moduleの自作
libraryフォルダをplaybookと同じディレクティブに配置する
- http://docs.ansible.com/ansible/latest/dev_guide/developing_modules.html
- http://blog.toast38coza.me/custom-ansible-module-hello-world/
ゼロから始める自作モジュールが丁寧に解説されています(クラスメソッド社ブログ)
簡単にAWS向け自作モジュールを作る
フィルタ、Jinja2
list-dictから新たなdictを作成する
以下のsubnet_result変数のitem.nameをキーにしたdictを作成する
# 元データ(subnet_result)
subnet_result =
{
"results": [
{
"item": {
"name": "xxx-subnet1"
"cidr": "10.0.0.0/21"
},
"subnet": {
"id": "subnet-000001"
}
},{
"item": {
"name": "xxx-subnet2"
"cidr": "10.0.8.0/21"
},
"subnet": {
"id": "subnet-000002"
}
},{
"item": {
"name": "xxx-subnet3"
"cidr": "10.0.16.0/21"
},
"subnet": {
"id": "subnet-000003"
}
}
]
}
- set_fact:
subnet_name_id: "{{ subnet_name_id | default({}) | combine( {item.item.name: item.subnet.id} ) }}"
with_items: "{{ subnet_result.results }}"
- debug: msg=subnet_name_id
# 結果*********************
"msg": {
"xxx-subnet1": "subnet-000001",
"xxx-subnet2": "subnet-000002",
"xxx-subnet3": "subnet-000003"
}
参照リンク集
AWX
構築手順
参考:Ansible AWX(Docker版)の構築と使い方
便利なツール
- awx-manage・・・AWX(Ansible Tower)内の機能実行、設定情報の取得などができる
ハマりポイント
AWX 6.1.0 と AWX 7.x以降で動作が異なる
完全私の環境の例になります。
AWXプロジェクトのSCMタイプを手動でplaybooksディレクトリはplaybooksを指定していました。
6.1.0までは以下のようにprojectsの直下にplaybooksやrolesを配置していました。
そして、ジョブの実行パスは/var/lib/awx/projects/playbooks/hoge.ymlで実行していたので、問題なく実行できました。
/var/lib/awx/projects/
│
├── playbooks
│ ├── hoge.yml
│ └── fuga.yml
|
├── roles
│ ├── hoge.yml
│ └── fuga.yml
7.x以降は/tmp/xxxxにプロジェクトファイルをコピーし実行されるため、上記のような設定ではplaybooksディレクトリのみがコピーされ、他のrolesやvarsなどはコピーされなくなります。つまり、それらを参照してる処理はエラーになります。
/tmp/xxxxx/projects/plabooks
├── hoge.yml
└── fuga.yml
なので、projectsの直下に配置せずに新たにプロジェクトのフォルダを設け、AWXのプロジェクトのplaybooksディレクトリではmy-projectを指定し、テンプレートのPlaybookはplaybooks/hoge.ymlと指定します。
/var/lib/awx/projects/my-project
│
├── playbooks
│ ├── hoge.yml
│ └── fuga.yml
|
├── roles
│ ├── hoge.yml
│ └── fuga.yml
# 実行時に以下のようにプロジェクト全体をコピーしてくれます。
/tmp/xxxxx/projects/my-project
│
├── playbooks
│ ├── hoge.yml
│ └── fuga.yml
|
├── roles
│ ├── hoge.yml
│ └── fuga.yml
ansible.cfgの場所
ansible.cfgには適用の優先順位があります。
ansible.cfg (in the current directory)で配置している場合は、current directoryはAWXのプロジェクト設定のplaybookディレクトリ項目で指定したディレクトリになります。
前述の例を引用するとmy-project/ansible.cfgに配置しなければならない。
Ansible Container
Dockerとのすみわけ
- Ansibleは周辺環境の構成管理が可能?
環境作成
windows10
> pip install ansible-container[docker,k8s,pypiwin32]
AWS関連
Route53 ホストゾーンID
各種リソースの連携(Route53とELB連携)で連携先のRoute53のホストゾーンIDを設定しなければならない時に役に立つのRoute53のホストゾーンIDの一覧になります(リージョンごとに固定値)
S3のELBアカウントID一覧
ELBのログ出力する際にポリシーに含める必要があるELBアカウントIDの一覧(リージョンごとに固定値)
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/classic/enable-access-logs.html