なんで作ろうと思ったか
昨年に娘が産まれてから、早いもので1年半が経ちました。私のGoogleフォトも嫁のiCloudも娘ちゃんの写真/動画で埋め尽くされ、ローカルに移行してまた埋まっての繰り返しです。
どこかで「子どもが泣いている時に、自分の笑っている動画を見せたら落ち着く」みたいな話を聞きました。
撮りに撮りためた動画ストックから「娘ちゃんの笑顔動画集」を作ろうと思いましたが、動画数が多く断念しました。そこでふと、AWSに「Amazon Rekognition」というサービスがあり、そこに表情の分析機能もあると知ったので、これを活用できないか、と考えたのがキッカケです。
どんなものを作ったか
システム構成図
最終的には、笑顔のシーンの抽出/結合まで自動化させたいなと思ってますが、現時点では笑顔のシーンが含まれる動画の判定までです。
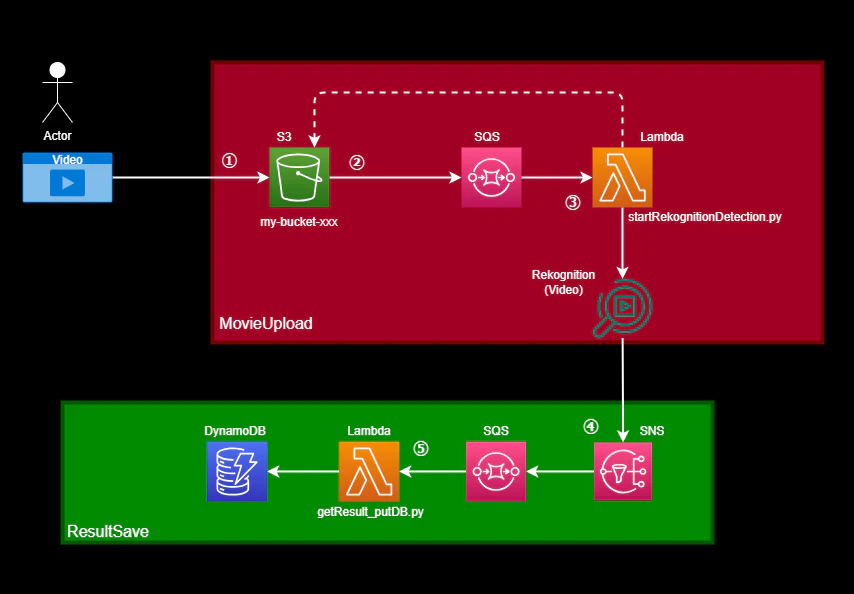
処理の流れ
①:S3バケットに分析対象の動画をアップロードする(ここは手動)
②:S3バケットへのアップロードをトリガーにして、SQSにメッセージが格納される
③:SQSへのメッセージングをトリガーにして、S3バケットに保管された動画の分析処理(StartFaceDetection)が実行される
④:Amazon Rekognitionでの分析が完了すると、SNSトピック(SQS)へ完了通知が飛ぶ
⑤:SQSへのキューイングをトリガーにして、分析結果の取得および結果をDynamoDBへ格納する処理が実行される
AWSリソースの作成にはTerraformを利用しました。①~③を「MovieUpload」、④~⑤を「ResultSave」という処理の単位で分けて、Terraformのコードも分割してみました。
Terraformおよびpythonコード
今回の各種コーディングにあたって、まずはChatGPTで想定している処理概要からTerraformコード/Pythonプログラムの枠組みを作ったあと、求める要件に合わせてコードを修正していく、という流れで進めました。
そのため、一部で設定が不要なパラメータ等が残っているかもしれないですがご了承ください。
MovieUpload
S3関連のリソース
# ユニークなS3バケット名を付与するために、ランダムな文字列を生成
resource "random_id" "suffix" {
byte_length = 8
}
# 動画アップロード用のS3バケット
resource "aws_s3_bucket" "video_put" {
bucket = "my-bucket-${random_id.suffix.hex}"
acl = "private"
}
# S3バケット空にするためのリソース
resource "null_resource" "default" {
triggers = {
bucket = aws_s3_bucket.video_put.bucket
}
depends_on = [
aws_s3_bucket.video_put
]
provisioner "local-exec" {
when = destroy
command = "aws s3 rm s3://${self.triggers.bucket} --recursive"
}
}
# S3からLambda関数を起動するためのリソース
# Terraformから実行する際には必要
# 参考URL:https://symphonict.nesic.co.jp/tech-blog/458/
resource "aws_lambda_permission" "permission" {
statement_id = "AllowExecutionFromS3Bucket"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.rekognition_put_lambda.function_name
principal = "s3.amazonaws.com"
source_arn = "${aws_s3_bucket.video_put.arn}/*"
}
- ここで生成したS3バケットに、分析したい動画をアップロードします。動画の生成されたことをトリガーにして、「MovieUpload」の処理が動き出します。
- S3バケット名は既にあるバケット名と衝突すること避けるため、
random_idリソースを使ってランダムな文字列を含むバケット名になるようにしてみました。random_id.b64_stdやrandom_id.b64_urlだとS3バケット名に使用不可な記号が含まれる可能性があるので、random_id.hexで16進数表記としました。これは重複しない、というバケット名があるならそれをベタ書きにする方が良いかもしれません。 -
aws_lambda_permissionリソースは必要らしいので、追加しました。
SQS関連のリソース
# 「動画アップロード用のS3バケット」のイベント通知に使われるSQS
resource "aws_sqs_queue" "s3_events_queue" {
name = "s3_events_queue"
delay_seconds = 0
max_message_size = 2048
message_retention_seconds = 86400
visibility_timeout_seconds = 60
receive_wait_time_seconds = 10
}
# SQSのポリシー設定
resource "aws_sqs_queue_policy" "sqs_policy_attache" {
queue_url = aws_sqs_queue.s3_events_queue.id
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "s3.amazonaws.com"
},
"Action": "sqs:SendMessage",
"Resource": "${aws_sqs_queue.s3_events_queue.arn}"
}
]
}
EOF
}
# 「動画アップロード用のS3バケット」のイベント通知
resource "aws_s3_bucket_notification" "s3_event_notification" {
bucket = aws_s3_bucket.video_put.id
queue {
queue_arn = aws_sqs_queue.s3_events_queue.arn
events = ["s3:ObjectCreated:*"]
}
depends_on = [ aws_lambda_permission.permission ]
}
- S3にファイルが作成されたことをトリガーにSQSへイベント通知させます。S3のイベント通知で直接Lambdaを呼び出すこともできそうですが、一気にアップロードがあった場合などの処理を制御させるため、SQS経由としてみました。
Lambda関数関連のリソース
# 動画分析を実行するためのLambda関数
resource "aws_lambda_function" "rekognition_put_lambda" {
filename = data.archive_file.rekognition_put_lambda_zip.output_path
function_name = "startRekognitionDetection"
role = aws_iam_role.role.arn
handler = "startRekognitionDetection.lambda_handler" # pythonファイル名(拡張子なし).lambda_handlerにする必要がある
timeout = 15
source_code_hash = data.archive_file.rekognition_put_lambda_zip.output_base64sha512
runtime = "python3.8"
environment {
variables = {
SNS_TOPIC_ARN = var.sns_topic_arn
ROLE_ARN = var.role_arn
}
}
}
# pythonプログラムをLambdaにデプロイ
data "archive_file" "rekognition_put_lambda_zip" {
type = "zip"
source_file = "./modules/MovieUpload/src/startRekognitionDetection.py"
output_path = "lambda_startRekognitionDetection_payload.zip"
}
# 動画分析用Lambdaに付与するRole
resource "aws_iam_role" "role" {
name = "lambda_execution_role"
assume_role_policy = jsonencode({
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
})
}
# 動画分析用Lambda用のポリシー
resource "aws_iam_role_policy" "policy" {
name = "lambda_execution_policy"
role = aws_iam_role.role.id
policy = jsonencode({
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"rekognition:*",
"sqs:ReceiveMessage",
"sqs:DeleteMessage",
"sqs:GetQueueAttributes",
"s3:GetObject",
"logs:CreateLogStream",
"logs:PutLogEvents",
"iam:PassRole"
],
"Resource": "*"
}
]
})
}
# SQSと動画分析用lambdaの関連付け
resource "aws_lambda_event_source_mapping" "s3_sqs_lambda_mapping" {
event_source_arn = aws_sqs_queue.s3_events_queue.arn
function_name = aws_lambda_function.rekognition_put_lambda.arn
}
# ログ記録用のCloudWatchのロググループ
resource "aws_cloudwatch_log_group" "example" {
name = "/aws/lambda/${aws_lambda_function.rekognition_put_lambda.function_name}"
retention_in_days = 7
}
- pythonプログラムをLambda関数として登録します。
aws_lambda_functionリソースのenvironmentブロック、プログラムへ渡したい変数を定義しておきます。これにより、pythonプログラム内にSNSトピック名やロールをベタ書きする必要がなくなります。 - ポリシーはsqsなどでは操作するオペレーションを指定して許可していますが、rekognitionがall許可していたり、リソースを特定していなかったりで、改善の余地はありそうだなと思ってます。
Pythonプログラム
import boto3
import time
from decimal import Decimal
import json
import os
def lambda_handler(event, context):
print("START Logic")
# アップロードされた動画の情報を取得
message_body = event['Records'][0]['body']
message_json = json.loads(message_body)
try:
bucket = message_json['Records'][0]['s3']['bucket']['name']
key = message_json['Records'][0]['s3']['object']['key']
print("FILE NAME:"+key)
except KeyError:
if 'TestEvent' in message_json['Event']:
print("This is TestEvent")
return
else:
print(message_json)
# 環境変数からArn情報を取得
sns_arn = os.environ.get("SNS_TOPIC_ARN")
role_arn = os.environ.get("ROLE_ARN")
# Amazon Rekognitionのクライアントを作成
rekognition = boto3.client('rekognition')
# 動画の解析パラメータを設定
parameters = {
'Video': {
'S3Object': {
'Bucket': bucket,
'Name': key
}
},
'Features': ['FACE'],
'FaceAttributes': 'ALL',
'NotificationChannel': {
'SNSTopicArn': sns_arn,
'RoleArn': role_arn
}
}
# 動画の解析を実行
response = rekognition.start_face_detection(
Video=parameters['Video'],
FaceAttributes=parameters['FaceAttributes'],
NotificationChannel=parameters['NotificationChannel']
)
# 解析ジョブのIDを取得
job_id = response['JobId']
print("job id:"+job_id)
# 終了処理
return {
'statusCode': 200,
'body': 'Video analysis started'
}
- メッセージからバケット名とファイル名(key)を取得する処理をtryブロックで囲んであります。これは、自動的に生成されるテストメッセージがエラーになり続けることを防ぐためです。デッドレターキューを用意するなどの方法もあるかと思いますが、今回はテストメッセージの場合にエラー処理するロジックをプログラム内に埋め込みました。
- Rekognitionで動画分析の処理を開始する際、SNSトピックとそのSNSトピックへ書き込む権限を持つRoleを
NotificationChannelパラメータで指定しています。「ResultSave」の処理は、動画分析が完了したメッセージがSNSへ通知されたことをトリガーにして動き出します。
ResultSave
SNS/SQS関連のリソース
# 処理結果の送信先SNSトピックの作成
resource "aws_sns_topic" "example_topic" {
name = "AmazonRekognition-Result-topic"
}
# 処理結果の保存用SQSキューの作成
resource "aws_sqs_queue" "rekognition_result" {
name = "rekognition_result"
delay_seconds = 0
max_message_size = 2048
message_retention_seconds = 86400
visibility_timeout_seconds = 360
receive_wait_time_seconds = 10
}
# SQSキューに対するSNSサブスクリプションの作成
resource "aws_sns_topic_subscription" "example_subscription" {
topic_arn = aws_sns_topic.example_topic.arn
protocol = "sqs"
endpoint = aws_sqs_queue.rekognition_result.arn
}
# ポリシーの設定
resource "aws_sqs_queue_policy" "rekognition_sqs_policy_attache" {
queue_url = aws_sqs_queue.rekognition_result.id
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "sns.amazonaws.com"
},
"Action": "sqs:SendMessage",
"Resource": "${aws_sqs_queue.rekognition_result.arn}"
}
]
}
EOF
}
- Rekognitionの処理結果を受け取るためのSNSおよびSQSの設定です
Rekognition関連のリソース
# SNSへのパブリッシュ権限を付与したRoleの作成(Rekognitionで処理する際に指定する)
resource "aws_iam_role" "rekognition_sns_role" {
name = "rekognition-sns-role"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "rekognition.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
}
resource "aws_iam_role_policy" "rekognition_sns_policy" {
name = "rekognition-sns-policy"
role = aws_iam_role.rekognition_sns_role.id
policy = jsonencode({
"Version" : "2012-10-17",
"Statement" : [
{
"Effect" : "Allow",
"Action" : "sns:Publish",
"Resource" : aws_sns_topic.example_topic.arn
}
]
})
}
- RekognitionはSQSやDynamoDBみたいに個別にリソースを作成する必要はありませんが、今回はRekognitionの処理結果をSNSへ通知させるため、対象SNSへPublic許可を持つRoleを用意しておきます。
Lambda関連のリソース
# 分析結果取得用のLambda関数
resource "aws_lambda_function" "getResult_lambda" {
filename = data.archive_file.getResult_lambda_zip.output_path
function_name = "getResult_putDB"
role = aws_iam_role.role.arn
handler = "getResult_putDB.lambda_handler"
timeout = 300
source_code_hash = data.archive_file.getResult_lambda_zip.output_base64sha512
runtime = "python3.8"
environment {
variables = {
TABLE_NAME = aws_dynamodb_table.table.name
}
}
}
# 分析結果取得用のpythonプログラムをLambdaにデプロイ
data "archive_file" "getResult_lambda_zip" {
type = "zip"
source_file = "./modules/ResultSave/src/getResult_putDB.py"
output_path = "lambda_getResult_payload.zip"
}
# 分析結果取得用Lambdaに付与するRole
resource "aws_iam_role" "role" {
name = "getResult_lambda_execution_role"
assume_role_policy = jsonencode({
"Version" : "2012-10-17",
"Statement" : [
{
"Action" : "sts:AssumeRole",
"Principal" : {
"Service" : "lambda.amazonaws.com"
},
"Effect" : "Allow",
"Sid" : ""
}
]
})
}
# 分析結果取得用Lambda用のポリシー
resource "aws_iam_role_policy" "policy" {
name = "getResult_lambda_execution_policy"
role = aws_iam_role.role.id
policy = jsonencode({
"Version" : "2012-10-17",
"Statement" : [
{
"Effect" : "Allow",
"Action" : [
"rekognition:GetFaceDetection",
"dynamodb:BatchGetItem",
"dynamodb:BatchWriteItem",
"dynamodb:ConditionCheckItem",
"dynamodb:PutItem",
"dynamodb:DescribeTable",
"dynamodb:DeleteItem",
"dynamodb:GetItem",
"dynamodb:Scan",
"dynamodb:Query",
"dynamodb:UpdateItem",
"sqs:ReceiveMessage",
"sqs:DeleteMessage",
"sqs:GetQueueAttributes",
"logs:CreateLogStream",
"logs:PutLogEvents",
"iam:PassRole"
],
"Resource" : "*"
}
]
})
}
# SQSと動画分析用lambdaの関連付け
resource "aws_lambda_event_source_mapping" "s3_sqs_lambda_mapping" {
event_source_arn = aws_sqs_queue.rekognition_result.arn
function_name = aws_lambda_function.getResult_lambda.arn
batch_size = 1
}
# ログ記録用のCloudWatchのロググループ
resource "aws_cloudwatch_log_group" "default" {
name = "/aws/lambda/${aws_lambda_function.getResult_lambda.function_name}"
retention_in_days = 7
}
- 用意するリソースはだいたい「MovieUpload」と同じです
- 結構ハマったのが、
aws_lambda_functionリソースのtimeoutパラメータは、aws_sqs_queueリソースのvisibility_timeout_secondsパラメータで指定した値よりも短い必要があるということです。Lambda側のタイムアウトを変更した際に、SQS側のパラメータ(可視性タイムアウト、というそうです)よりも長い時間になっていて、TerraformでApplyする際にエラーということが何度かありました。
DynamoDB関連のリソース
# Amazon Rekognitionで分析した動画情報の格納DB
resource "aws_dynamodb_table" "table" {
name = "VideoDetectionResults"
hash_key = "FileName"
range_key = "StartFrame"
read_capacity = 5
write_capacity = 5
attribute {
name = "FileName"
type = "S"
}
attribute {
name = "StartFrame"
type = "N"
}
}
- Rekognitionで分析した結果を格納するために、DynamoDBを利用します
- パーティションキーはファイル名(FileName)、ソートキーには開始フレームとしています。Rekognitionでの分析結果は、だいたい1~2秒ごとのシーンごとにまとめられているので、そのシーンごとにデータを格納するにしました
- 読み込みキャパシティおよび書き込みキャパシティは適当です
Pythonプログラム
import boto3
import json
import os
from decimal import Decimal
def lambda_handler(event, context):
rekognition_client = boto3.client('rekognition')
sqs_client = boto3.client('sqs')
# SQSからメッセージを受信
for record in event['Records']:
message_json = json.loads(record['body'])
print("MESSAGE:"+message_json['Message'])
job_data = json.loads(message_json['Message'])
print("JOB_ID:"+job_data['JobId'])
key=job_data['Video']['S3ObjectName']
# 動画解析結果を取得
result = rekognition_client.get_face_detection(JobId=job_data['JobId'])
# DynamoDBのテーブル名を環境変数から取得
table_name = os.environ.get("TABLE_NAME")
# 検出結果をDynamoDBに保存
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(table_name)
# 検出された笑顔のシーンと度合いを抽出
StartFrame = 0
for face in result['Faces']:
smile = {
'FileName' : key,
'StartFrame': StartFrame,
# 分析した全データの保存はコメントアウト
# 'FaceData': json.dumps(face['Face']),
'EndFrame': face['Timestamp'],
'SmileOrNot': face['Face']['Smile']['Value'],
'SmileConfidence': Decimal(face['Face']['Smile']['Confidence']),
'MaxAgeRange': face['Face']['AgeRange']['High'],
'MinAgeRange': face['Face']['AgeRange']['Low']
}
table.put_item(Item=smile)
StartFrame = face['Timestamp']
print("END Logic")
return {
'statusCode': 200,
'body': 'Video analysis completed'
}
- SNSへ通知されたRekognitionの分析完了メッセージから、まずは対象のジョブIDを取得します。
- ジョブIDを引数に指定して、
rekognition_client.get_face_detection関数で詳細な結果をresultへ格納します -
resultの各要素の値をDynamoDBへ格納していきます。以下に記載されているように、、Timestampには"ビデオで顔が検出された時間"となっています。今回は処理では、前の配列要素のTimestampを開始フレーム(StartFrame)、検出された顔でのTimestampを終了フレーム(EndFrame)として、そのフレーム間の動画をシーンとして記録します。
GetFaceDetection は、ビデオ内で検出された顔に関する情報が含まれた配列 (Faces) を返します。配列要素 (FaceDetection) は、ビデオで顔が検出されるたびに生成されます。配列要素は、ビデオの開始時点からの経過時間 (ミリ秒単位) で並べ替えられて返されます。
- 検出された顔について、笑っているかどうかの判定とその信頼度が含まれています。
SmileOrNotには笑顔かどうかのbool値を、SmileConfidenceにはその信頼値(0~100)を格納します。json形式ではFloat型になっているので、SmileConfidenceを格納する際には明示的にDecimal型へ型変換させています。今回、笑顔のシーンを抽出するといったケースでは、「SmileOrNotがtrueかつ、SmileConfidenceの値がより高い」レコード(シーン)を検出する必要があります。 -
MaxAgeRangeおよびMinAgeRangeには、検出された顔の予想年齢(0以上の整数)が格納されます。今回は子どもの笑顔のシーンを抽出するので、「MaxAgeRangeが一定数以下」のレコード(シーン)を検出するための判定に利用します。
FaceDetectionに含まれる要素の説明はこちら
https://docs.aws.amazon.com/rekognition/latest/APIReference/API_FaceDetail.html
GetFaceDetectionについてのドキュメントはこちら
https://docs.aws.amazon.com/ja_jp/rekognition/latest/dg/faces-sqs-video.html
検出結果を出力するpythonプログラム
今回、Terraformで生成されるリソースはアップロードした動画から、笑顔のシーンを検出してDynamoDBへ格納するまでとなります。DynamoDBから結果を取得するためには、以下のプログラムを実行します。
このプログラムでは以下を出力するものとなります。
- 分析結果から、ファイル毎に最大の笑顔のシーン(レコード)を取得 ※"最大の笑顔"というのは、
SmileOrNotがtrueかつ、SmileConfidenceの値が最大ということ - さらに、その最大の笑顔を含むファイル名を、
SmileConfidenceの値が高いものから順に5つ表示する
import boto3
# DynamoDBクライアントの初期化
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('VideoDetectionResults')
# ファイル名の一覧を取得
bucket_name = 'your-bucket-name' # ここにバケット名を指定
def list_all_files(bucket_name):
s3 = boto3.client('s3')
paginator = s3.get_paginator('list_objects_v2')
file_list = []
# ページネーションを使ってバケット内のすべてのオブジェクトを取得
for page in paginator.paginate(Bucket=bucket_name):
for obj in page.get('Contents', []):
file_list.append(obj['Key'])
return file_list
def get_record_with_max_smile_confidence(file_name):
response = table.query(
KeyConditionExpression='FileName = :fn',
ExpressionAttributeValues={
':fn': file_name,
':smileValue': True,
':maxAge': 5
},
ProjectionExpression="FileName, SmileConfidence, StartFrame, EndFrame",
FilterExpression='SmileOrNot = :smileValue AND MaxAgeRange <= :maxAge'
)
# SmileConfidenceが最大のレコードを取得
max_confidence_record = max(response['Items'], key=lambda x: x['SmileConfidence'], default=None)
return max_confidence_record
if __name__ == '__main__':
all_file_names = list_all_files(bucket_name)
max_records = []
for name in all_file_names:
record = get_record_with_max_smile_confidence(name)
if record:
print(f"FileName: {record['FileName']}, SmileConfidence: {record['SmileConfidence']}, StartFrame: {record['StartFrame']}, EndFrame: {record['EndFrame']}")
max_records.append(record)
top_5_records = sorted(max_records, key=lambda x: x['SmileConfidence'], reverse=True)[:5]
print(f"---Top 5 Maximum SmileConfidence:---")
for record in top_5_records:
print(f"FileName: {record['FileName']}, SmileConfidence: {record['SmileConfidence']}, StartFrame: {record['StartFrame']}, EndFrame: {record['EndFrame']}")
- まず、
list_all_files関数でS3バケットに含まれるファイル名一覧を取得します。これは後ほど、DynamoDBでqueryアクセスする際に必要になります。 - 'your-bucket-name'となっている箇所には、Terraform実行により生成されたS3バケットの名称に修正します。
- 取得したファイル名毎に、
get_record_with_max_smile_confidence関数を実行します。まずは、SmileOrNotがTrueかつ、MaxAgeRangeが5以下の要素をresponseに保存します。responseの各要素のうち、SmileConfidenceが最大のものをこの関数の戻り値とします。 -
get_record_with_max_smile_confidence関数の戻り値をmax_recordsに追加していき、sorted関数でSmileConfidenceが高いもの順で最初の5要素をtop_5_recordsに保存します。 - 最後に、
top_5_recordsの各要素のファイル名、SmileConfidenceの値、シーンの開始および終了フレーム(StartFrame/EndFrame)の情報を出力します。
個人的な開発で感じたこと
今回、コードを書き始めたのが7月に入ってからで、この記事を書くまでがちょうど3ヵ月でした。(対価を得ているわけではないので個人開発というのか微妙ですが、)業務とは異なる個人での開発をやってみて、感じたことを書いてみたいと思います。
GitHub
-
GitHubは業務でも触ったことがなかったのだが、今回はGitHubとTerraform Cloudを接続した自動デプロイをするためにコミットやプルリクなどの機能を使ってみた。コミットメッセージも書いたことがないので、とりあえずなんか書いとけ状態になってしまった。見直すと"repair(修正したよ)"だけというメッセージが多い(そりゃ修正しているからコミットしているわけですが。。。)。
-
今回、Issuesも使うように心がけてみた。何かエラーがあったときに、どのようなエラーがあってどう解決したのか、ということをまとめておいて、こうやって記事を書くときにハマった点などをまとめる際に活用できればと思っていた。今見返してみると、書き方にルールが無いので非常に見づらいし後から追いにくい。。。
-
Issuesに関してはTODOリストになってしまっているのも反省点かも。ただ、別でファイルやサービスを持つよりも、GitHubで完結できたという点ではTODOをIssuesに書いておくのは悪くなかったかも(あくまで、自分だけが見るという前提においては)。
-
ブランチも使ったが、「ローカルで修正したものをdevelopブランチとしてコミット」→「GitHub上でプルリクを起票してmasterへマージ(TerraformのApplyが動く)」のほぼ一直線となってしまった。機能ごとにブランチを作って修正が済んだらmasterへマージ、みたいな開発ができればよかった(してみたかった。。。)
開発環境(VScodeなど)
- 今更だけど、Terraformの文法チェックの拡張機能などを導入しておけばよかったかも
- Draw.ioの拡張機能は良かった。システム構成図などを絵で描いておかないと、時間が経ってから見返しても忘れている時もあるので。こちらの記事が参考になりました→https://qiita.com/riku-shiru/items/5ab7c5aecdfea323ec4e
- "README.md"を自分用メモに書いておいたのは良かったと思う。Markdownの練習にもなったし、上記のDraw.ioの図も含めることができた。
ChatGPT
- 今回の開発においては大変助かりました。おそらくChatGPTが無ければここまでたどり着けなかったと思います。個人的MVPです。
- どのようなリソースを作りたいのか、使ってほしいサービスなどを箇条書きにまとめて、それらを生成するTerraformのコードを作成を指示することで、とりあえずは大まかなリソースを作ることはできました。
- あとは詳細な要件やChatGPTに上手く伝えられなかった部分を、手修正していくことにより、ゼロから生成するよりも効率よく進めることができたと思います。
- ちなみに会社がChatGPT Plusの費用を補助してくれたのもありがたかったです。
↓こんな感じで、Terraformのコードを生成してくれました
今後はどうしていきたいか
- 当初の目的であった、「笑顔動画集」の生成までを自動化したい
- どうもiPhoneで撮影した動画だと、「サポートされていない動画コーデック」ということでエラーになってしまうこと事象を解決したい(自分はAndroidだけど、家族はiPhoneユーザーが多いので)
- 今回、作成したコードを一般公開して、同様のニーズを持った方が使えるようにしたい(現状のコードは少しまとめなおしたうえで、GitHubなどで公開できればと思っています)
- できれば、エンジニアでない方も使えるようにサービス化(Webサイトから動画をアップロード、笑顔動画集が作成できたらダウンロードリンクをメールに送る、みたいな)