やりたいこと
OpenAI の各種 API を使って、音声で家の家電 (SwitchBot 製品) を操作できるようにしたので、その内容を記事にしてみます。
Google Home や Alexa と何か違うのかと言われると、まったく変わりません!笑
今は、チャット形式でテキストのやり取りをすることが多いですが、その先にはこういう音声でのコミュニケーションも待っているんだろうなということでやってみたという内容です。
前提
- 音声の入出力のために、マイクとスピーカーが必要です
- OpenAI の API を利用するので、アカウントとクレジットが必要です
- クレジットについては無料枠が残っていればその範囲内で利用できます
- SwitchBot の API を利用するための
TOKENとAPI_KEYが必要です- Get-started を参考に発行してください
環境
- Windows11 Pro
- WSL (Ubuntu 22.04)
- Python
- 3.10.12
実装
requirements.txt
以下の通り。
annotated-types==0.6.0
anyio==4.1.0
black==23.11.0
certifi==2023.11.17
cffi==1.16.0
charset-normalizer==3.3.2
click==8.1.7
distro==1.8.0
exceptiongroup==1.2.0
h11==0.14.0
httpcore==1.0.2
httpx==0.25.2
idna==3.6
mypy-extensions==1.0.0
numpy==1.26.2
openai==1.3.8
packaging==23.2
pathspec==0.11.2
platformdirs==4.1.0
pycparser==2.21
pydantic==2.5.2
pydantic_core==2.14.5
python-dotenv==1.0.0
requests==2.31.0
sniffio==1.3.0
SoundCard==0.4.2
soundfile==0.12.1
tomli==2.0.1
tqdm==4.66.1
typing_extensions==4.8.0
urllib3==2.1.0
パラメータ設定
Credential 情報を .env としてファイルに書いておく。右辺は自身のものに置き換える。
SWITCHBOT_TOKEN={YOUR_TOKEN)
SWITCHBOT_SECRET_KEY={YOUR_SECRET_KEY}
ORGANIZATION_ID={YOUR_ORGANIZATION_ID}
API_KEY={YOUR_API_KEY}
コード
あまりキレイではないですが、、ご参考まで!
src/main.py
import json
import os
from pathlib import Path
import soundcard
import soundfile
from dotenv import load_dotenv
from openai import OpenAI
from switchbot_client.client import SwitchBotClient
load_dotenv()
SWITCHBOT_TOKEN = os.getenv("SWITCHBOT_TOKEN")
SWITCHBOT_SECRET_KEY = os.getenv("SWITCHBOT_SECRET_KEY")
ORGANIZATION_ID = os.getenv("ORGANIZATION_ID")
API_KEY = os.getenv("API_KEY")
def record_sound(sound_file_path: str):
print("speak your instruction...")
default_mic = soundcard.default_microphone()
sample_rate = 48000
recording_time = 5 # [seconds]
with default_mic.recorder(samplerate=sample_rate) as mic:
data = mic.record(numframes=recording_time * sample_rate)
soundfile.write(sound_file_path, data, sample_rate)
def play_sound(sound_file_path: str):
print("playing the sound file...")
default_speaker = soundcard.default_speaker()
sample_rate = 25000
with default_speaker.player(samplerate=sample_rate) as sp:
data, _ = soundfile.read(sound_file_path)
sp.play(data)
def main():
# SwitchBot settings
sb_client = SwitchBotClient(token=SWITCHBOT_TOKEN, secret_key=SWITCHBOT_SECRET_KEY)
# OpenAI settings
ai_client = OpenAI(organization=ORGANIZATION_ID, api_key=API_KEY)
model = "gpt-3.5-turbo-1106"
available_functions = {
f"{sb_client.control_device_with_name.__name__}": sb_client.control_device_with_name
}
tools = []
with open("func_definitions/control_device_with_name.json", encoding="utf-8") as f:
tools.append(json.load(f))
messages = [
{
"role": "system",
"content": "You are a smart home agent that can control devices in the home. Any device names must be provided in Japanese. When controlling curtains, turnOn means open and turnOff means close.",
},
]
# sound file settings
dir_name = "./soundfile"
if not os.path.exists(dir_name):
os.makedirs(dir_name)
sound_file_name = "/sound.mp3"
sound_file_path = Path(dir_name + sound_file_name)
# Main loop
while True:
key = input("Enter to start recording for 5 seconds, q to exit: ")
if key == "q":
break
elif key == "":
record_sound(sound_file_path)
with open(sound_file_path, "rb") as f:
response = ai_client.audio.transcriptions.create(
model="whisper-1", file=f
)
else:
print("Invalid key input")
continue
prompt = response.text
messages.append({"role": "user", "content": prompt})
print("Q:", prompt)
response = ai_client.chat.completions.create(
model=model,
messages=messages,
max_tokens=1000,
tools=tools,
tool_choice="auto",
)
choice = response.choices[0]
finish_reason = choice.finish_reason
if finish_reason == "stop":
answer = choice.message.content
messages.append({"role": "assistant", "content": answer})
elif finish_reason == "tool_calls":
message = choice.message
messages.append(message)
for tool_call in message.tool_calls:
function_name = tool_call.function.name
if not function_name in available_functions:
print(function_name, "is not available")
continue
function_to_call = available_functions[function_name]
function_args = json.loads(tool_call.function.arguments)
values = list(function_args.values())
function_output = function_to_call(*values)
print(function_name, function_args, "function_output:", function_output)
content = function_args
content["function_output"] = function_output
message = {
"tool_call_id": tool_call.id,
"role": "tool",
"name": function_name,
"content": str(content),
}
messages.append(message)
response = ai_client.chat.completions.create(
model=model,
messages=messages,
max_tokens=1000,
tools=tools,
tool_choice="auto",
)
answer = response.choices[0].message.content
messages.append({"role": "assistant", "content": answer})
response = ai_client.audio.speech.create(
model="tts-1", voice="alloy", input=answer
)
response.stream_to_file(sound_file_path)
print("A:", answer)
play_sound(sound_file_path)
print("----- Chat history -----")
for msg in messages:
msg_dict = dict(msg)
if msg_dict["content"] is None:
continue
if msg["role"] == "system":
continue
if msg_dict["role"] == "assistant":
indent = "\t>>"
else:
indent = "\t\t>>"
print(msg_dict["role"], indent, msg_dict["content"])
if __name__ == "__main__":
main()
switchbot_client/client.py
"""
SwitchBot Client Class
"""
import base64
import hashlib
import hmac
import time
import uuid
from enum import Enum
import requests
class SwitchBotClient:
def __init__(self, token, secret_key):
self.__host = "https://api.switch-bot.com"
self.__token = token
self.__secret_key = secret_key
self.__last_request_time = None
self.__all_devices = self.__get_all_devices()
self.__all_name_based_devices = self.__get_all_name_based_devices()
def __get_signature(self) -> dict:
current_time = int(round(time.time() * 1000))
request_id = uuid.uuid4
string_to_sign = bytes(f"{self.__token}{current_time}{request_id}", "utf-8")
secret = bytes(self.__secret_key, "utf-8")
sign = base64.b64encode(
hmac.new(secret, msg=string_to_sign, digestmod=hashlib.sha256).digest()
)
return {
"Authorization": self.__token,
"sign": sign,
"t": str(current_time),
"nonce": str(request_id),
}
def __get_all_devices(self) -> dict:
path = "/v1.1/devices"
headers = self.__get_signature()
# self.__sleep_api_call(datetime.datetime.now())
res = requests.get(url=self.__host + path, headers=headers, timeout=10.0)
if res.status_code != 200:
print("Status Code: ", res.status_code)
print("cannot get all devices")
return []
return res.json()["body"]
def __send_command(self, device_id: str, command: str) -> dict:
path = f"/v1.1/devices/{device_id}/commands"
headers = self.__get_signature()
payload = {
"command": command,
}
# self.__sleep_api_call(datetime.datetime.now())
response = requests.post(
self.__host + path, headers=headers, json=payload, timeout=10.0
)
if response.status_code != 200:
return "Something went wrong"
return response.json()
def get_device_id_with_name(self, device_name: str) -> str:
return self.__all_name_based_devices[device_name]["deviceId"]
def control_device_with_name(self, device_name: str, command: str) -> dict:
device_id = self.get_device_id_with_name(device_name)
return self.__send_command(device_id, command)
func_definitions/control_device_with_name.json
{
"type": "function",
"function": {
"name": "control_device_with_name",
"description": "Control a device given its name and command.",
"parameters": {
"type": "object",
"properties": {
"device_name": {
"type": "string",
"description": "The name of the device to control. e.g. 'リビングのライト', 'サーキュレーターのプラグ', '寝室のライト', 'リビングのカーテン', 'フロアライト'"
},
"command": {
"type": "string",
"description": "The command to send to the device. e.g. 'turnOn', 'turnOff'"
}
},
"required": [
"device_name",
"command"
]
}
}
}
実行してみる
仮想環境の起動
venv で仮想環境を構築してアクティベートする。
python -m venv .venv
source .venv/bin/activate
仮想環境を終了するときは、deactivate コマンド。
実行結果
実行すると、Enter to start recording for 5 seconds, q to exit: と表示されるので、何も入力せずエンターを押すと、5秒間の録音が始まる。その間に、操作したいデバイス名とアクションを口頭で指示する。
実際に操作した際の動作が以下。A: の部分は音声でも回答してくれている。
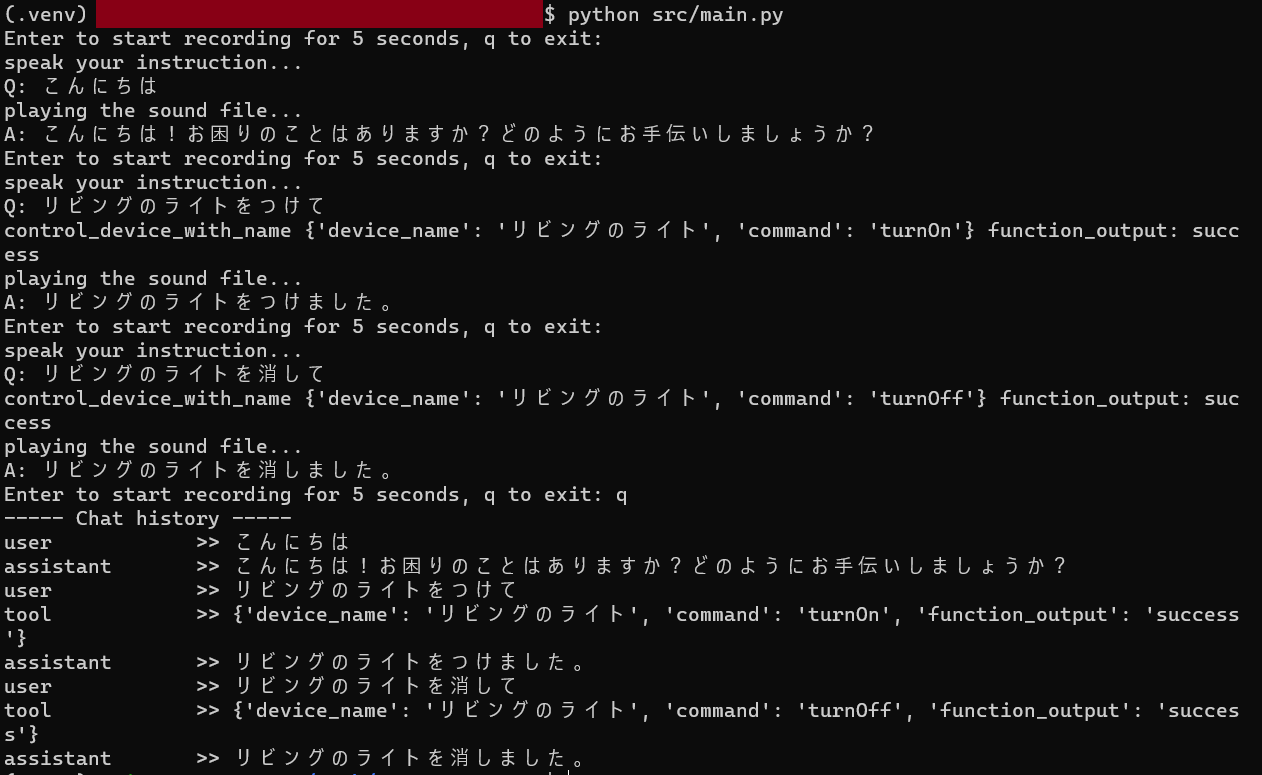
上記のログには表示していないが、FunctionCalling によって ChatGPT 側で使うべき関数を判断してくれるので、コード内でその関数に対して指定された引数を与えて、その戻り値を再度 Chat のメッセージに追加してリクエストしている。
実際に行った処理内容が、control_device_with_name の部分。{} 内が実際の引数で、function_output が戻り値。この結果を Chat のメッセージに追加している。
デバイス名については、実際に登録してある名前にしないとデバイスが見つからず操作できないこともある。例えば、◯リビングのライト -> ✕リビングの電気 など (うまく電気をライトとして指定してくれることもある)。
このあたりは、システムプロンプトで事前に登録しておくなどすればある程度は対応できるかもしれない。
アクションについてはSwitchBot API では基本的に turnOn と turnOff なのでひとまずそれのみが実行できる。カーテンについては、「開けて」「閉めて」が「Open」「Close」と指示されてしまうので、システムプロンプトで変換するように指示している。
ということで
OpenAI の API を使って、SwitchBot 製品を操作するエージェントを作ってみました。
機能的には、Alexa や Google Home などと何ら変わらないですが簡単にここまで実装することができました。また、Function Calling の使い方次第で他にも様々な機能を利用できるので、いろんな用途で使うことができると思いますし、Alexa などの機能拡張といったこともできると思います。
今後は、チャット形式よりもこういった音声ベースでのコミュニケーションが主流になるのではと個人的には思います。そのためのスマートデバイス (スマートウォッチやスマートグラス、VR グラスなど?) もどんどん進化するのではないでしょうか。
以上です。