やりたいこと
業務で、Azure Cognitive Search での各検索方式を試す機会があったので、その内容を記事にしようと思います。Azure OpenAI Service と組み合わせて RAG (Retrieval Augmented Generation) を行う際の精度にも関わる部分なので、そういった分野に興味のある方の参考になれば幸いです!
Cognitive Search とは
全文検索やベクトル検索を行うことができ、字句解析や AI によるエンリッチメントを行える。単なるキーワード検索だけでなく、セマンティック検索を有効にすることで検索クエリと意味として関連するものを検索することもできる。
こっちの記事にも書いたのでご参考まで。
検索方式
フルテキスト検索
一般的な全文検索。検索クエリに指定されたテキストで検索を行う。BM25 という関連性スコアリングアルゴリズムにより、クエリに指定されたテキストの出現頻度に基づきランク付けされる。
ベクトル検索
検索クエリを数値表現したベクトルで指定する検索方式。HNSW (Hierarchical Navigable Small World) または KNN (k-Nearest Neighbor) というアルゴリズムで関連性が判定される。KNN はメモリや処理時間がかかってしまうが精度は高くなるそう。2023-10-01-Preview REST API で利用できる (23/10/31 時点)。
検索クエリをテキストからベクトル化するには、任意の Embedding (埋め込み) モデルを利用して行う。Azure OpenAI Service だと、text-embedding-ada-002 を利用する。
セマンティック検索
検索クエリと意味として関連するものを検索する方式。最初に BM25 でランク付けを行い、その後セマンティックランク付けを行い最終的なランクが決定される。
ハイブリッド検索
複数の検索方式を組み合わせる方式。
フルテキスト + ベクトル
フルテキスト検索とベクトル検索を組み合わせた検索方式。ハイブリッド検索というと一般的にはこの方式を指す。
検索は、Index 内のテキストフィールドとベクトルフィールドに対して行われ、それぞれの結果を RFF (Reciprocal Rank Fusion) によって最終的なランク付けを行う。
ベクトル + セマンティック
ベクトル検索とセマンティック検索を組み合わせた検索方式。フルテキスト + ベクトルと同様にベクトル検索でのランク付け後にセマンティックランク付けを行い、RFF による最終的なランク付けを行う。
セマンティックハイブリッド検索と呼ばれる。
実装
注意
- セマンティック検索は Basic プラン以上のみで有効化できる
- Basic プラン以上はリソースを作成した時点から課金される (使わない間は削除するなど必要)
リソース作成
事前に作成済みとするので、ここでは説明しない。
必要なリソースは、Cognitive Search (セマンティック検索有効化済) と OpenAI Service (Embedding モデルデプロイ済)。
投入するデータ
コード内で、適当な Web サイトをデータとして Cognitive Search に投入する。
Index 作成
まずは、パラメータを設定する。Azure Portal から各パラメータをコピペする。
OPENAI_API_TYPE=azure
OPENAI_API_BASE=YOUR_API_BASE
OPENAI_API_KEY=YOUR_API_KEY
OPENAI_EMBEDDINGS_DEPLOYMENT_NAME=YOUR_EMBEDDINGS_DEPLOYMENT_NAME
SEARCH_ENDPOINT=YOUR_SEARCH_ENDPOINT
SEARCH_API_KEY_ADMIN=YOUR_SEARCH_API_KEY
Index 作成は Python で行う。使用するライブラリは以下。バージョンは参考まで。
python-dotenv==1.0.0
langchain==0.0.268
openai==0.27.8
tiktoken==0.4.0
azure-search-documents==11.4.0b6
azure-identity==1.13.0b4
bs4==0.0.1
Index 作成を行うコード。投入するデータを変更する場合は、WebBaseLoader で指定している URL を変更する。
import os
from azure.core.credentials import AzureKeyCredential
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents.indexes.models import (
HnswParameters, PrioritizedFields, SearchableField, SearchField,
SearchFieldDataType, SemanticConfiguration, SemanticField,
SemanticSettings, SimpleField, VectorSearch,
VectorSearchAlgorithmConfiguration)
from dotenv import load_dotenv
from langchain.document_loaders import WebBaseLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores.azuresearch import AzureSearch
load_dotenv()
OPENAI_API_TYPE = os.getenv('OPENAI_API_TYPE')
OPENAI_API_BASE = os.getenv('OPENAI_API_BASE')
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
OPENAI_EMBEDDINGS_DEPLOYMENT_NAME = os.getenv(
'OPENAI_EMBEDDINGS_DEPLOYMENT_NAME')
SEARCH_ENDPOINT = os.getenv('SEARCH_ENDPOINT')
SEARCH_API_KEY_ADMIN = os.getenv('SEARCH_API_KEY_ADMIN')
index_name = 'sample-index'
# Cognitive Search client
index_client = SearchIndexClient(
endpoint=SEARCH_ENDPOINT,
credential=AzureKeyCredential(SEARCH_API_KEY_ADMIN))
# create embeddings
embeddings = OpenAIEmbeddings(openai_api_type=OPENAI_API_TYPE,
model=OPENAI_EMBEDDINGS_DEPLOYMENT_NAME,
openai_api_base=OPENAI_API_BASE,
openai_api_key=OPENAI_API_KEY,
deployment=OPENAI_EMBEDDINGS_DEPLOYMENT_NAME)
# create vector config
vector_config_name = 'my-vector-config'
vector_config = VectorSearch(algorithm_configurations=[
VectorSearchAlgorithmConfiguration(
name=vector_config_name,
kind='hnsw',
hnsw_parameters=HnswParameters(
m=4, ef_construction=400, ef_search=500, metric='cosine'))
])
# create semantic settings
semantic_config_name = 'my-semantic-config'
semantic_config = SemanticConfiguration(
name=semantic_config_name,
prioritized_fields=PrioritizedFields(
prioritized_content_fields=[SemanticField(field_name='content')]))
semantic_settings = SemanticSettings(configurations=[semantic_config])
# create field definition
fields = [
SimpleField(
name='id',
type=SearchFieldDataType.String,
key=True,
filterable=True,
),
SearchableField(
name='content',
type=SearchFieldDataType.String,
searchable=True,
analyzer_name='ja.lucene',
),
SearchField(name='content_vector',
type=SearchFieldDataType.Collection(
SearchFieldDataType.Single),
searchable=True,
vector_search_dimensions=len(embeddings.embed_query('Text')),
vector_search_configuration=vector_config_name),
SearchableField(
name='metadata',
type=SearchFieldDataType.String,
searchable=False,
),
]
# create vector store
vector_store = AzureSearch(azure_search_endpoint=SEARCH_ENDPOINT,
azure_search_key=SEARCH_API_KEY_ADMIN,
index_name=index_name,
vector_search=vector_config,
semantic_settings=semantic_settings,
embedding_function=embeddings.embed_query,
fields=fields)
# load documents to vector store
web_loader = WebBaseLoader('https://ja.wikipedia.org/wiki/ロジャー・フェデラー')
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=200)
docs = text_splitter.split_documents(web_loader.load())
vector_store.add_documents(documents=docs)
検索してみる
Azure Portal 上から行う。
検索する内容は、ウィンブルドンの優勝回数は? というもの。実際には、通算8回優勝している。
フルテキスト検索
キーワードでの検索になるので、以下のような検索内容。+ は AND 条件。
{
"queryType": "simple",
"search": "ウィンブルドン+優勝+回数",
"select": "id,content,metadata",
"count": true
}
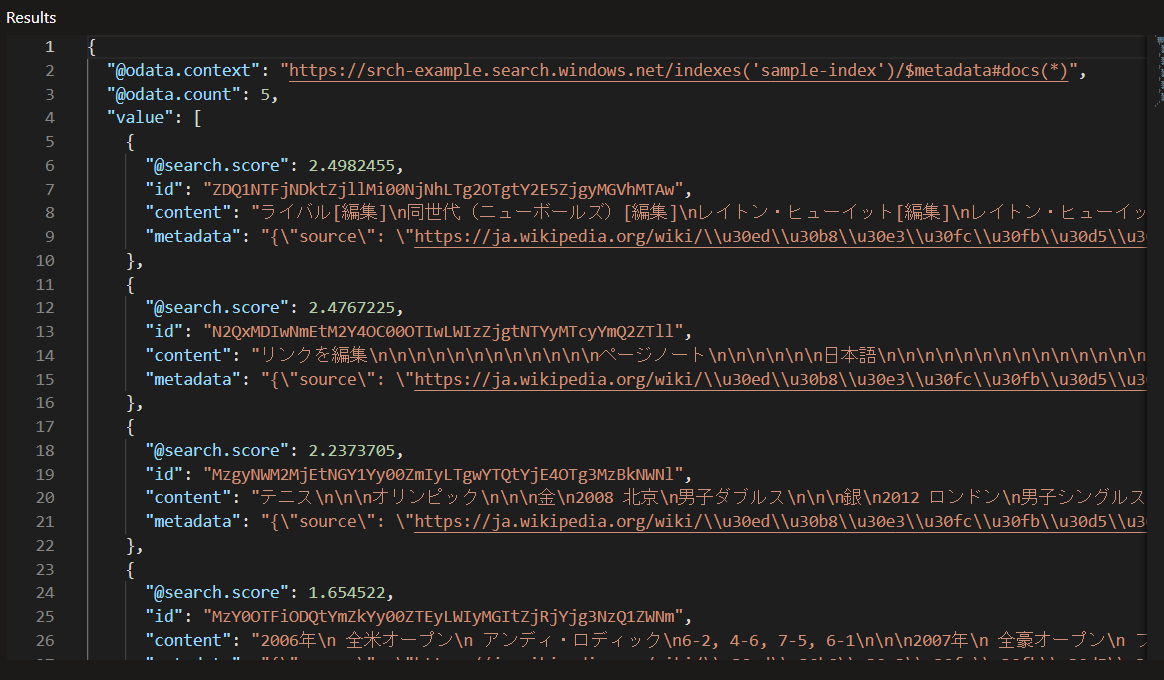
結果 (テキストが長いので画像で)
2番目の内容に優勝した年が書かれているが、ストレートに分かる内容ではないかも。
実際の WEB ページだと表形式で書かれている箇所。
ベクトル検索
value に、ウィンブルドンの優勝回数は? をベクトル化した値を指定する。
{
"vectors": [
{
"value": [
-0.0012641462,
-0.016507657,
-0.003483692,
... (省略)
],
"fields": "content_vector",
"k": 5
}
],
"select": "id,content,metadata",
"count": true
}
結果 (テキストが長いので画像で)
イマイチ。ウィンブルドン という言葉に引っ張られていそう?

ハイブリッド検索
フルテキスト検索とベクトル検索のパラメータどちらも設定する。
{
"vectors": [
{
"value": [
-0.0012641462,
-0.016507657,
-0.003483692,
... (省略)
],
"fields": "content_vector",
"k": 5
}
],
"search": "ウィンブルドン+優勝+回数",
"select": "id,content,metadata",
"count": true
}
結果 (テキストが長いので画像で)
フルテキスト検索とベクトル検索の結果が組み合わさり、フルテキスト検索時の2番目の結果も現れるようになった。

セマンティック検索
以下の設定で行う。
{
"queryType": "semantic",
"queryLanguage": "en-us",
"search": "ウィンブルドンの優勝回数は?",
"semanticConfiguration": "my-semantic-config",
"searchFields": "",
"speller": "lexicon",
"answers": "extractive|count-3",
"captions": "extractive|highlight-true",
"highlightPreTag": "<strong>",
"highlightPostTag": "</strong>",
"select": "id,content,metadata",
"filter": "",
"count": true
}
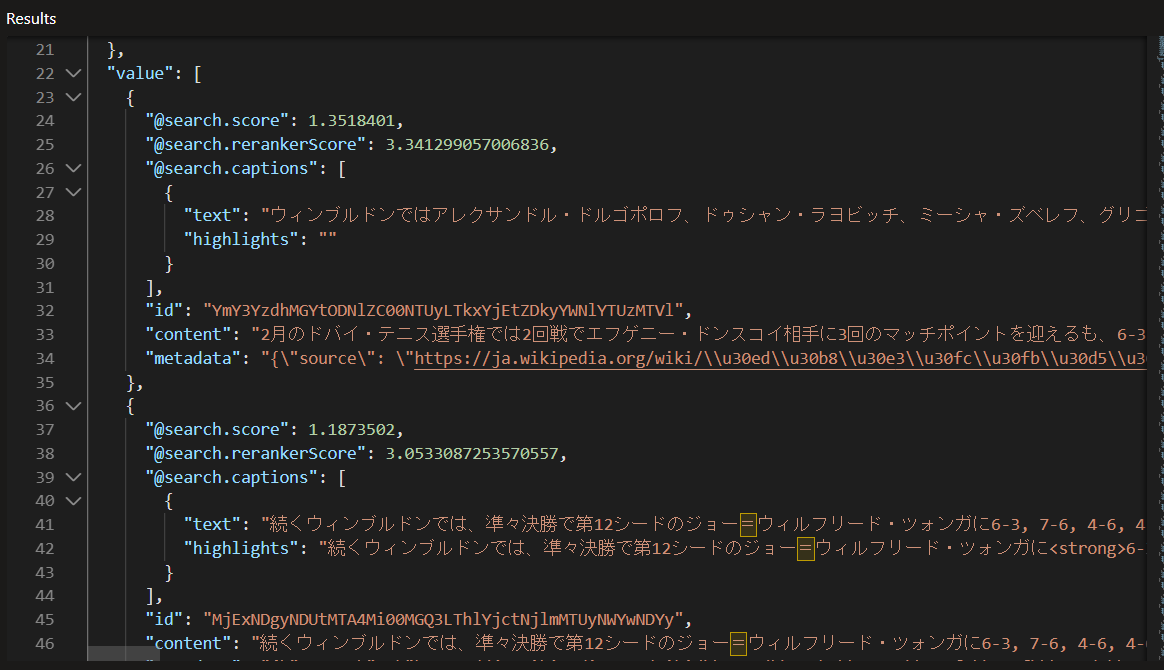
結果 (テキストが長いので画像で)
1番目の結果に、8勝目を挙げたという内容が現れている!
セマンティックハイブリッド検索
以下の設定で行う。
{
"vectors": [
{
"value": [
-0.0012641462,
-0.016507657,
-0.003483692,
... (省略)
],
"fields": "content_vector",
"k": 5
}
],
"queryType": "semantic",
"queryLanguage": "en-us",
"search": "ウィンブルドンの優勝回数は?",
"semanticConfiguration": "my-semantic-config",
"searchFields": "",
"speller": "lexicon",
"answers": "extractive|count-3",
"captions": "extractive|highlight-true",
"highlightPreTag": "<strong>",
"highlightPostTag": "</strong>",
"select": "id,content,metadata",
"filter": "",
"count": true
}
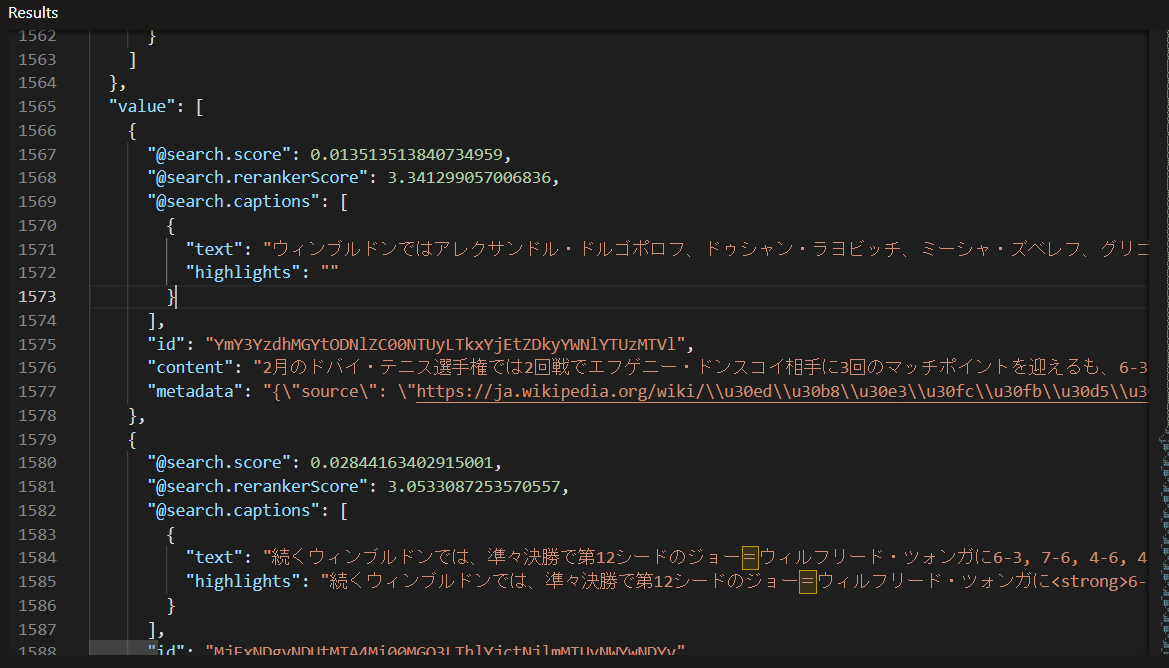
結果 (テキストが長いので画像で)
セマンティック検索と同様に8勝目を挙げたという内容が1番目に現れている。
[参考] 検索精度について
以下の内容に各検索方式での検索精度がまとめられている。結論としては、セマンティックハイブリッド検索が最も精度が高かったとのこと。
ということで
Azure Cognitive Search の各検索方式の違いと検索方法についてまとめました。
この検索結果を使い、Azure OpenAI Service へのプロンプトに質問に関連するドキュメントを含めることで独自データを回答させることができるようになります。
セマンティック検索は、Cognitive Search を使う最大のメリットなので OpenAI Service から良い回答が得られない場合は、採用の余地が大いにあると思います (Cognitive Search が Basic 以上のプランだとけっこう高額になってしまうのが難点ですが…)。
以上です。